Toward Intelligent Data Quality in Modern Data Pipelines
Data quality goes beyond null checks. Learn how GenAI helps detect subtle issues, explain anomalies, and strengthen testing in modern data pipelines.
Join the DZone community and get the full member experience.
Join For FreeWhat Data Quality Means in Practice
When I think about data quality in data engineering, I don’t immediately think about null checks or schema validation. Those are necessary, but they’re the obvious parts.
In a typical data pipeline, data is extracted from operational systems, transformed through layers of logic, and then loaded into tables, dashboards, and feature stores. At each step, expectations exist. We expect upstream systems to behave consistently. We expect transformations to preserve meaning. We expect metrics to reflect reality. And often, we expect that if nothing fails loudly, everything is fine. Some issues are easy to catch. Missing columns. Type mismatches. Duplicate keys. Those problems are visible. The harder issues are quieter.
A dataset can be technically valid and still incomplete in a way that matters. A metric can remain within a threshold and still be wrong because business logic changed. A schema can change without causing an error, and still change the meaning of the data downstream. At that point, data quality is not just about correctness in the moment. It’s about consistency over time.
Modern systems amplify this. Pipelines are built across teams. Data moves across domains. Real-time ingestion is common. Schemas evolve quickly. Volumes grow. Small upstream changes can propagate across multiple layers before anyone notices.
So data quality, at least the way I’ve come to see it, is about continuously validating both structure and behavior. It’s about surfacing assumptions before they quietly turn into incidents.
That sounds manageable in theory. In practice, it gets complicated.
Current Approaches and Where They Start to Strain
Most data quality implementations today revolve around deterministic checks. We define rules, enforce schemas, add constraints, and monitor a handful of metrics over time. And this works, up to a point.
Structural validation is rarely the real problem. Schema mismatches and type violations are usually caught. Referential integrity can be enforced. Basic completeness checks are straightforward. The complexity shows up in more subtle places.
Completeness, for example, is rarely binary. A dataset can pass every structural check and still be incomplete in a way that matters. Maybe one region’s data didn’t arrive. Maybe a subset of events dropped upstream. Nothing technically “breaks,” but something feels off.
Then there are thresholds. We often set them based on historical behavior. Row counts shouldn’t drop more than a certain percentage. Null rates should stay below some limit. But traffic grows. Seasonality shifts. Business behavior changes. A threshold that once made sense becomes either noisy or blind. So we tune it. And then retune it. Over time, we spend as much effort maintaining rules as writing them.
Rule authoring itself takes time. Translating business expectations into executable checks requires domain understanding. Profiling tools can summarize distributions, but someone still has to decide what matters and how strict to be.
When something fails, diagnosis is rarely straightforward. An alert fires. Or worse, nothing fails, but a metric looks suspicious. Now the team has to piece together what changed. A schema modification? A transformation tweak? An upstream API behavior shift? Root-cause analysis becomes a cross-system investigation involving lineage, logs, metrics, and recent commits.
In distributed environments, ownership boundaries make this harder. Producers and consumers are different teams. Contracts exist, but they don’t always capture every semantic assumption.
Testing is another gap I keep noticing. We test logic under controlled scenarios. Production data, however, is messy. Edge cases are unpredictable. Privacy constraints limit how freely we can use real data in test environments. So we simulate. And our simulations are often cleaner than reality.
None of this means current systems are ineffective. They are essential. But as pipelines scale, the cognitive load increases. The surface area increases. The effort to maintain coverage grows.
At some point, it starts to feel like we are only validating the problems we explicitly anticipated. And that’s where I started wondering whether something could assist with the parts that require interpretation, synthesis, and context.
How Generative AI Can Help
Over time, I’ve noticed that data quality work tends to cluster around a few recurring activities: writing rules, interpreting anomalies, diagnosing failures, handling schema changes, and designing realistic tests. These aren’t purely mechanical tasks. They require context. This is where generative AI (GenAI) becomes interesting.
Accelerating Rule and Test Generation
Translating business intent into validation logic is slow. Even with profiling summaries, someone has to decide what should become a rule.
Given schema definitions, metadata, and a description of business expectations, a model can propose candidate checks like completeness guards, distribution monitors, referential constraints, and even draft contract definitions. Instead of starting from scratch, engineers start from suggestions.
The same applies to testing. Instead of manually creating a handful of examples, generative systems can produce structured edge cases, including scenarios designed to break assumptions. That expands coverage beyond what we typically think to simulate.
Anomaly Interpretation
Metric monitoring can detect deviations. It’s less good at explaining them.
If row counts drop or a distribution shifts, an investigation begins. Someone has to correlate metric changes with recent schema diffs, deployments, or upstream behavior.
A generative system, especially when grounded in lineage metadata and recent changes, can synthesize these signals and propose structured hypotheses. This shortens the distance between detection and understanding.
Root-Cause Reasoning Across Artifacts
Incident diagnosis rarely lives in one place. It spans transformation logic, documentation, historical incidents, and commit history.
Retrieval-augmented approaches allow a model to reason across these artifacts in one place. It allows engineers to query a consolidated reasoning layer that connects context, instead of manually navigating multiple dashboards and repositories. This accelerates the investigation.
Schema Evolution Assistance
Schema changes are frequent and often subtle. Compatibility checks prevent obvious breakage, but they don’t always surface semantic impact.
A generative system can summarize code or schema changes in plain language and suggest migration notes. It can point out downstream tables or transformations that might be affected. It can also draft updated documentation that reflects the new structure. This is especially helpful in multi-team environments where context is spread across people and systems.
Synthetic Data and Edge-Case Simulation
Testing remains one of the weaker links in data quality.
Generative methods can create synthetic datasets that follow realistic distributions while introducing controlled anomalies. They can simulate partial drops, skewed distributions, delayed partitions, or malformed records. These are all scenarios that are hard to anticipate manually.
Synthetic data still requires evaluation for bias and privacy risk. But it widens the testing surface area significantly. Below is a simplified comparison of how these capabilities show up in practice.
| Task | classical approach | genAI-assisted approach |
|---|---|---|
|
Task |
Classical Approach |
GenAI-Assisted Approach |
|
Schema & constraint validation |
Explicit rule definition and enforcement |
Drafted contracts and candidate rules from metadata |
|
Metric monitoring |
Statistical baselines and thresholds |
Contextual explanation of deviations |
|
Rule authoring |
Manual translation of intent to checks |
Profile-driven rule suggestions |
|
Root-cause analysis |
Manual cross-system investigation |
Retrieval-based contextual reasoning |
|
Test data generation |
Handcrafted fixtures |
Synthetic scenario generation |
I’ve found it helpful to think of it as an added reasoning layer around the existing pipeline:
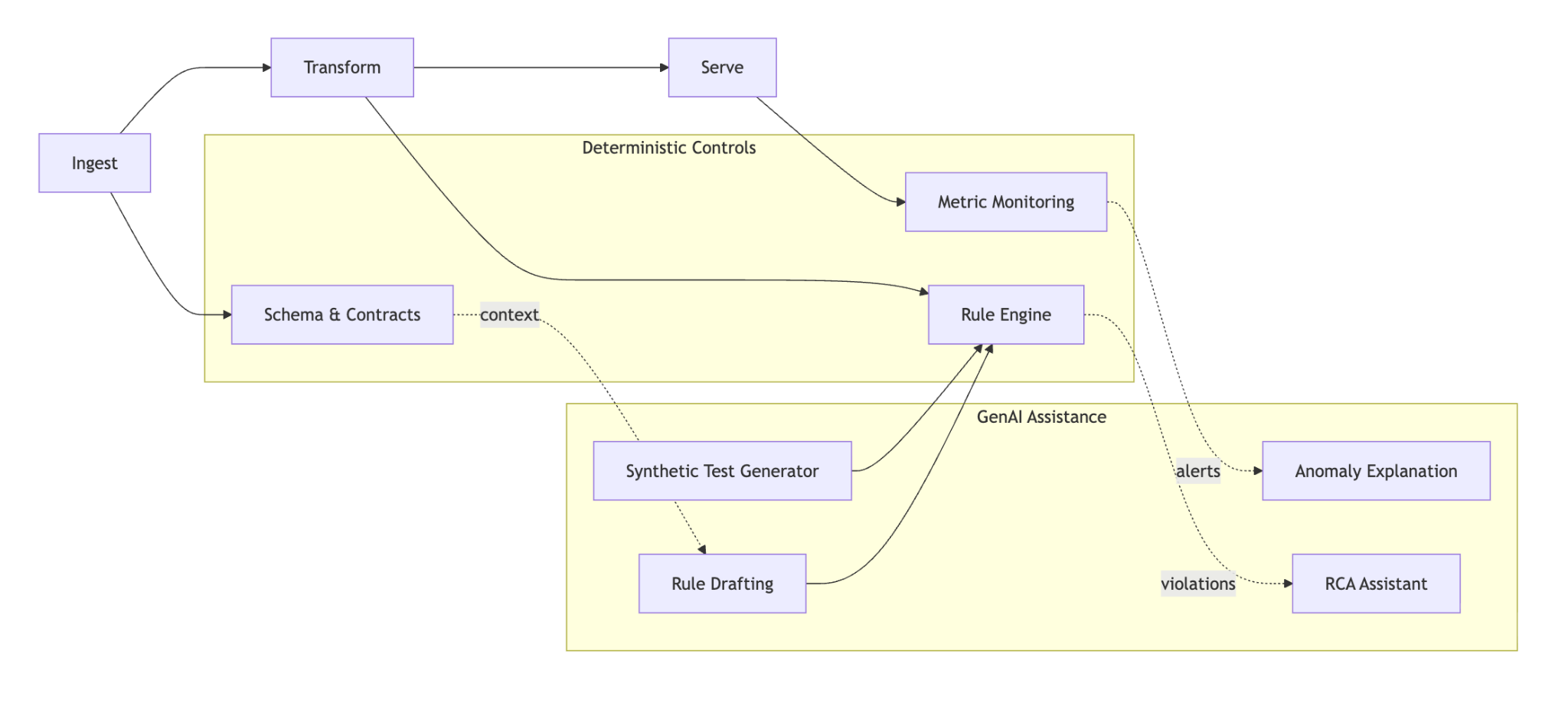
Conclusion
GenAI augments and accelerates the data quality work. Instead of manually drafting every rule, we can start from structured proposals. Instead of navigating dashboards during incidents, we can begin with synthesized context. Instead of relying on a small set of handcrafted test cases, we can explore broader scenarios.
Over time, that changes the feel of operating a pipeline. Data quality becomes less about maintaining an expanding checklist and more about continuously refining what the system understands as risk. It becomes easier to surface implicit assumptions. Easier to connect weak signals. Easier to explore “what if” scenarios before they reach production.
Of course, new capabilities introduce new responsibilities. Generated rules can be subtly wrong. Explanations can be incomplete. Synthetic data can encode bias. Systems that reason across artifacts must be carefully governed.
But those are design considerations, not disqualifiers. The underlying challenge hasn’t changed. Data systems are becoming more distributed and more dynamic. The number of datasets continues to grow. The pace of change keeps increasing.
What has changed is that we now have tools that can help with interpretation, synthesis, and exploration, which used to be manual and fragmented parts of data quality. After working with this kind of assistance in complex pipelines, it’s hard to imagine going back to purely manual quality workflows.
Opinions expressed by DZone contributors are their own.
Comments