Interactive PDF Q&A: A Retrieval-Augmented Generation Approach
Explore a RAG system to interact with PDFs by asking questions and getting relevant info. This locally hosted app uses LangChain and Streamlit.
Join the DZone community and get the full member experience.
Join For FreeIn the information age, dealing with huge PDFs happens on a day-to-day basis. Most of the time, I have found myself drowning in a sea of text, struggling to find the information I wanted or needed reading page after page. But, what if I can ask questions about the PDF and recover not only the relevant information but also the page contents?
That's where the Retrieval-Augmented Generation (RAG) technique comes into play. By combining these cutting-edge technologies, I have created a locally hosted application that allows you to chat with your PDFs, ask questions, and receive all the necessary context.
Let me walk you through the full process of building this kind of application!
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation or RAG is a method designed to improve the performance of the LLM by incorporating extra information on a given topic. This information reduces uncertainty and offers more context helping the model respond to the questions in a better way.
When building a basic Retrieval-Augmented Generation (RAG) system, there are two main components to focus on: the areas of Data Indexing and Data Retrieval and Generation. Data Indexing enables the system to store and/or search for documents whenever needed. Data Retrieval and Generation is where these indexed documents are queried, the data required is then pulled out, and answers are generated using this data.
Data Indexing
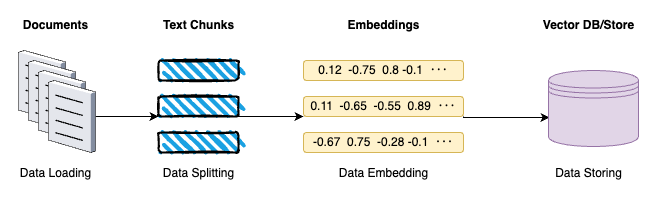 Data Indexing comprises of four key stages:
Data Indexing comprises of four key stages:
- Data loading: This initial stage involves the ingestion of PDFs, audio files, videos, etc. into a unified format for the next phases.
- Data splitting: The next step is to divide the content into manageable segments: segmenting the text into coherent sections or chunks that retain the context and meaning.
- Data embeddings: In this stage, the text chunks are transformed into numerical vectors. This transformation is done using embedding techniques that capture the semantic essence of the content.
- Data storing: The last step is storing the generated embeddings which is typically in a vector store.
Data Retrieval and Generation
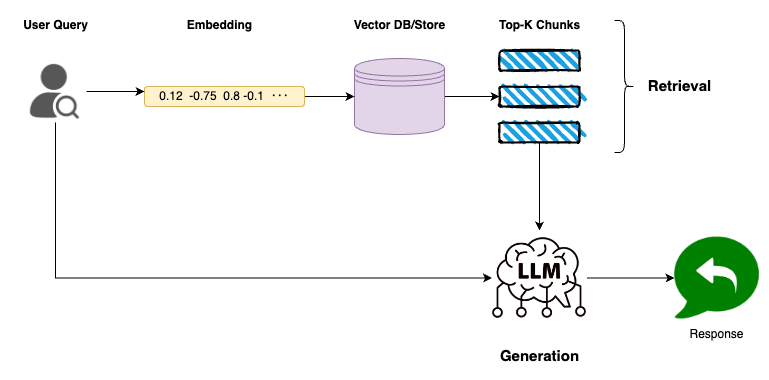
Retrieval
- Embedding the query: Transforming the user’s query into an embedding form so it can be compared for similarity with the document embeddings
- Searching the vector: The vector store contains vectors of different chunks of documents. Thus, by comparing this query embedding with the stored ones, the system determines which chunks are the most relevant to the query. Such comparison is often done with the help of computing cosine similarity or any other similarity metric.
- Selecting top-k chunks: The system takes the k-chunks closest to the query embedding based on the similarity scores obtained.
Generation
- Combining context and query: The top-k chunks provide the necessary context related to the query. When combined with the user's original question, the LLM receives a comprehensive input that will be used to generate the output.
Now that we have more context about it, let's jump into the action!
RAG for PDF Document
Prerequisites
Everything is described in this GitHub repository. There is also a Docker file to test the full application. I have used the following libraries:
- LangChain: It is a framework for developing applications using Large Language Models (LLMs). It gives the right instruments and approaches to control and coordinate LLMs should they be applied.
- PyPDF: This is used for loading and processing PDF documents. While PyMuPDF is known for its speed, I have faced several compatibility issues when setting up the Docker environment.
- FAISS stands for Facebook AI Similarity Search and is a library used for fast similarity search and clustering of dense vectors. FAISS is also good for fast nearest neighbor search, so its use is perfect when dealing with vector embeddings, as in the case of document chunks. I have decided to use this instead of a vector database for simplicity.
- Streamlit is employed for building the user interface of the application. Streamlit allows for the rapid development of interactive web applications, making it an excellent choice for creating a seamless user experience.
Data Indexing
- Load the PDF document.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(pdf_docs)
pdf_data = loader.load()
- Split it into chunks. I have used a chunk size of 1000 characters.
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=150,
length_function=len
)
docs = text_splitter.split_documents(pdf_data)
- I have used the OpenAI embedding model and loaded them into the FAISS vector store.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
embeddings = OpenAIEmbeddings(api_key = open_ai_key)
db = FAISS.from_documents(docs, embeddings)
- I have configured the retrieval to only the top 3 relevant chunks.
retriever = db.as_retriever(search_kwargs={'k': 3})
Data Retrieval and Generation
- Using the
RetrievalQAchain from LangChain, I have created the full Retrieval and Generation system linking into the previous FAISS retriever configured.
from langchain.chains import RetrievalQA
from langchain import PromptTemplate
from langchain_openai import ChatOpenAI
model = ChatOpenAI(api_key = open_ai_key)
custom_prompt_template = """Use the following pieces of information to answer the user's question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Context: {context}
Question: {question}
Only return the helpful answer below and nothing else.
Helpful answer:
"""
prompt = PromptTemplate(template=custom_prompt_template,
input_variables=['context', 'question'])
qa = RetrievalQA.from_chain_type(llm=model,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": prompt})Streamlit
I have used Streamlit to create an application where you can upload your own documents and start the RAG process with them. The only parameter required is your OpenAI API Key.

I used the book "Cloud Data Lakes for Dummies" as the example for the conversation shown in the following image.

Conclusion
At a time when information is available in a voluminous form and at users’ disposal, the opportunity to engage in meaningful discussions with documents can go a long way in saving time in the process of mining valuable information from large PDF documents. With the help of the Retrieval-Augmented Generation, we can filter out unwanted information and pay attention to the actual information.
This implementation offers a naive RAG solution; however, the possibilities to optimize it are enormous. By using different RAG techniques, it may be possible to further refine aspects such as embedding models, document chunking methods, and retrieval algorithms.
I hope that for you, this article is as fun to read as it was for me to create!
Opinions expressed by DZone contributors are their own.
Comments