Introduction to Imitation Learning
Imitation learning can help us solve sample inefficiency and computational feasibility problems, and also might potentially make the AI training process safer.
Join the DZone community and get the full member experience.
Join For Free
Living organisms are extremely complex — even the relatively simple ones such as flies or worms. They are able not only to operate successfully in the real world but are extremely resilient to changes in conditions. And that’s if we’re not even talking about humans. We can plan ahead, we can alter our plans given new information, and we can collaborate with others and execute our plans more effectively.
Science and such projects as CERN or a huge radio telescope in Arecibo are perfect examples of human collaboration and the art of planning. Yes, we do a lot of stupid stuff, but let’s not talk about that here. Let's instead focus on the good.
All the attempts to create an artificial organism with even smaller levels of autonomy have shown that years of the evolution process were not in vain, and building such an organism is a daunting task.
We can now beat the best human in chess or Go, we can get a crazy score in Video Pinball for Atari 2600, we can even already make a human broke by challenging him in poker. Can we open a bottle of champagne and celebrate the triumph? I’m afraid not.
Yes, machine learning has recently made a significant leap forward. The combination of new deep learning ideas with old ones has enabled us to advance in many domains, such as computer vision, speech recognition, and text translation.
Reinforcement learning has also benefited greatly from its marriage with deep learning. You’ve definitely heard of deep reinforcement learning success such as achieving superhuman scores in Atari 2600 games, solving Go, and making robots learn parkour.

Though we must admit that operating successfully in the real world is much harder than playing Go or Space Invaders. Many tasks are much harder than this. Imagine a kid riding a bicycle in the middle of a crowded city center or a man driving a Porsche 911 on an autobahn at 200 miles per hour. Let’s all admit that we are not there yet.
But Why Aren't We There Yet?
The typical machine learning approach is to train a model from scratch. Give it a million images and some time to figure it out. Give it a week and let it play Space Invaders until it reaches some acceptable score. We, as humans, beg to differ.

When a typical human starts to play some game they've never seen, they already have a huge amount of prior information. If they see a door in Montezuma’s Revenge, they realize that somewhere there should lie a key and he needs to find it. When he finds the key, he remembers that the closed door is back through the two previous rooms and he returns to open it. When he sees a ladder, he realizes that he can climb it because he has done this hundreds of time already.
What if we could somehow transfer human knowledge about the world to an agent? How can we extract all this information? How can we create a model out of it? There is a way. It’s called imitation learning.
Imitation learning is not the only name for leveraging human data for good. Some researchers also call it apprenticeship learning; others refer to it as learning from demonstration. From our point of view, there is no substantial difference between these titles and we will use imitation learning from now on.
In order to introduce imitation learning, we will need to understand the basics of reinforcement learning first. Let’s move on.
Reinforcement Learning 101
It’s not hard to get the general idea of the reinforcement learning setup. There is some agent and we want this agent to learn some task. Let’s say that we have an Atari 2600 console. The agent has access to the joystick and can see what’s happening on the screen.
Let’s say that 60 times per second, we give our agent a screenshot of the game and ask him what button he wants to press. If our agent does well, he can see that his score is increasing (positive reinforcement); otherwise, we can give him a penalty as a negative reward (negative reinforcement). Gradually, by trial and error, the agent starts to understand that it’s better to avoid some of the actions and do those which bring him a reward.
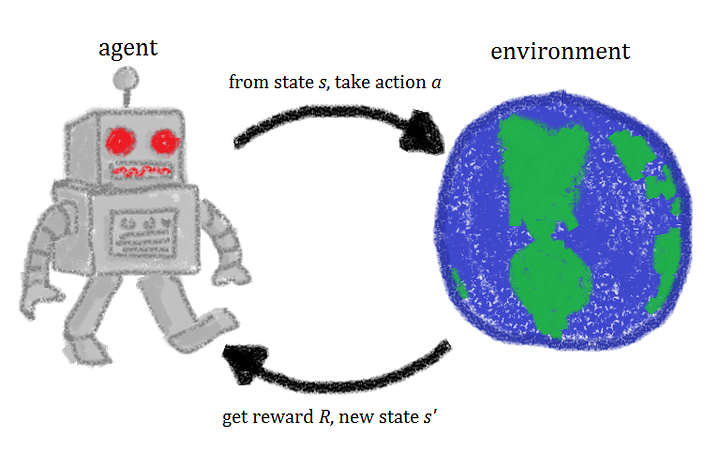
Usual reinforcement learning setup
Let’s make it more formal and describe the process stated above mathematically. We can describe the RL framework mentioned above (observe > act > get the reward and the next state) as a Markov Decision Process (MDP):
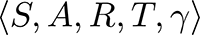
Where:
- S is the set of states.
- A is the set of actions.
- R is the reward function:

• T is the transition function:
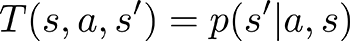
• The lambda symbol is the discounting factor that trades off the balance between the immediate reward and the future reward. There is a common opinion that humans prefer an immediate reward to one distant in time, though some say that we need discounting because of the mathematical convenience.
We also need a definition of a policy function for the next section. Policy is a function that returns an action given the state:
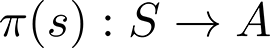
And actually, our final goal when solving an MDP is to learn such a policy in order to maximize the reward for our agent.
Let’s take an example of an MDP. The circles represent the states, arrows with green labels are actions, red labels are the rewards for actions, and the square is the terminal state. The green numeric labels are the transition probabilities.

Redrawn from David Silver’s Reinforcement Course slides, lecture 2.
Our student starts in a state with the blue circle. He studies, but this is hard and sometimes boring. He decides to open a Facebook app and once he is there, he can either quit or continue scrolling. He then studies more and more and finally decides to go to the pub.
The state is a smaller filled circle since now there is an element of randomness based on the amount of knowledge the student forgets after visiting the pub. He can then either study more and pass the exam (+10 in reward), or he can go to sleep and finish the MDP right now.
Deep Q-Network (DQN)
Since we will use DQN and related ideas in the future, let’s briefly understand what is going on here.
The whole approach is built upon approximating the so-called Q function and building the agent’s behavior based on it. The idea of the Q function is that it returns you the entire expected discounted reward flow for the particular action and the particular state, given that starting from the next state, we will be following our policy. It answers the question, “How good is to press this button in this state?”
The Q function obeys the Bellman equation:

And finally, the Bellman principle of optimality is that notwithstanding what happened before, we should always take the action with the highest Q to maximize the reward flow:

But how do we get such a Q function? Let’s look at an example. Imagine you want to grab a coffee (+20 in reward) and a chocolate in a vending machine (+10 in reward). Your total reward cannot exceed thirty. Moreover, if you have taken the coffee already, it cannot be higher than 10 (the reward for chocolate) from now on.
This is the idea: The Q value for the current step and action is equal to the maximum Q value for the next state (since we behave optimally) plus the reward we get for the transition. The value of the quadratic objective function becomes:

Q-learning itself is not new. Q-learning that uses neural networks as a function approximator is also not new (for example, neural fitted-q iteration). A DQN paper was the first to use deep convolutional networks to solve this type of problem and introduced a couple of novelties that make the training process much more stable.
First of all, experience replay. The vanilla Q-learning point is to make a step, get the reward and the next state, then update the approximation function parameters based on this transition. The DQN idea is to make the transition and save it in a “replay memory” — an array that stores the last 10⁶ (<insert any large number here>) transitions with the information about the reward, states before and after the transition, and if the event is terminal (game over) or not.
Having this experience replay we can randomly sample mini-batches from it and learn more effectively.
- First, each transition might potentially be used in several weight updates and the data is used more efficiently.
- Second, by randomly sampling, we break the correlation between samples, and this reduces the variance of the weight updates.
Another thing that makes the algorithm more stable is that DQN uses two neural networks: the first to compute the Q value for the current state and the second to compute the Q value for the next state.
You can see that from the equation with the objective: Two different Q functions use theta and theta’, respectively. Each 10,000 steps, the parameters theta’ are copied from the learned parameter's theta and this helps a lot in increasing the stability.
The problem here with using one function is that when we update the weights, both Q(s,a) and Q(s’,a’) increase and this might lead to oscillations or policy divergence. Using two separate networks adds a delay between an update and computation of the target Q value and reduces such cases. If you have further interest in the phenomena, read the Method section in the DQN Nature paper.
Okay, everything described above sounds quite simple. If there is still something you do not understand, please have a look at David Silver’s lecture where he explains everything perfectly!
Knowing all of these, can we build true AI now? I’m sorry, but we can’t.
Challenges for Reinforcement Learning
There are several problems that hinder us from building an agent that will beat ByuN at StarCraft II, bring an autonomous car to the market, or give you an opportunity to buy your grandma a robot that will do the dishes for her after lunch.
One of these problems is that the rewards our agent gets might be very sparse in time. Let’s say that you play chess. If you lose, how do you know when you made a catastrophic move? Moreover, it’s highly possible that there was not a catastrophic move but several average ones.
The reward sparsity is one of the issues that hinder us in beating Montezuma’s Revenge — a notoriously hard Atari 2600 game, that has not been cracked yet.
Another problem that is closely connected to the previous one is the sample efficiency problem — or, more honestly, sample inefficiency. Even to master a simple game such as Space Invaders might take a couple of days of game time. It’s easy to speed up learning in games since we have access to the simulators, but what if we want to learn something in real life? Unfortunately, physics is not there yet and we cannot speed up time.

There is an approach that could potentially solve these problems and a bunch of others — imitation learning, as we mentioned at the beginning of this post. As we said, we humans rarely learn something without any prior information. Let’s use this data! What should we do?
What Is Imitation Learning?
The idea of imitation learning is implicitly giving an agent prior information about the world by mimicking human behavior in some sense.
Imitation learning will not only help us solve the sample inefficiency or computational feasibility problems but it also might potentially make the training process safer. We cannot just put an autonomous car in the middle of the street and let it do whatever it wants. We do not want it to kill humans that are around, destroy someone’s property, or destroy the equipment itself. Pretraining it on a human demonstrator’s data might make the training process faster and avoid undesirable situations.
Having said all of the above, we forgot one thing: the data.
Training a model requires some data. Training a deep learning model requires even more data. Training a deep reinforcement learning model requires… okay, you get the idea.
So, this series only partly describes what we can do with demonstration data. The main point of all of this is to call for human demonstration datasets because we do not have many, unfortunately, up to this moment.
Okay, we should stop here. The key points of this post are:
- Machine learning is still far from building an autonomous agent that is able to solve complex real-world tasks.
- Imitation learning is one of the possible solutions that will make these agents closer.
- We also outlined the basics of reinforcement learning and, in particular, described in detail one of the RL algorithms: DQN.
In the next chapter, we will write more about behavior cloning — the simplest approach to an RL problem that can leverage the human demonstration data.
Stay tuned!
Further Reading
Published at DZone with permission of Vitaly Kurin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments