Introduction to Message Brokers. Part 1: Apache Kafka vs. RabbitMQ
If you're looking for a message broker for your next project, read on to get an overview of to of the most popular open source solutions out there.
Join the DZone community and get the full member experience.
Join For Free

The growing amount of equipment connected to the internet has led to a new term, Internet of Things (or IoT). It came from the machine to machine communication and means a set of devices that are able to interact with each other. The necessity of improving system integration caused the development of message brokers, that is especially important for data analytics and business intelligence. In this article, we will look at two big data tools: Apache Kafka and Rabbit MQ.
Why Did Message Brokers Appear?
Can you imagine the current amount of data in the world? Nowadays, about 12 billion "smart" machines are connected to the internet. Considering that about 7 billion people live on the planet, we have almost one-and-a-half devices per person. By 2020, this number will significantly increase to 200 billion, or even more. With technological development, like the building of "smart" houses and other automatic systems, our everyday life becomes more and more digitized.
Message Broker Use Case
As a result of this digitization, software developers face the problem of successful data exchange. Imagine you have your own application. For example, it's an online store. So, you permanently work in your technological scope, and one day you need to make the application interact with other apps. Previously, you would use simple "end points" for machine to machine communication. But nowadays we have special message brokers. They make the process of data exchange simple and reliable. These tools use different protocols that determine the message format. The protocols show how the message should be transmitted, processed, and consumed.
Messaging in a Nutshell
" a message broker translates a message from the formal messaging protocol of the sender to the formal messaging protocol of the receiver." - Wikipedia
Programs like this are essential parts of computer networks. They ensure the transmitting of information from point A to point B.
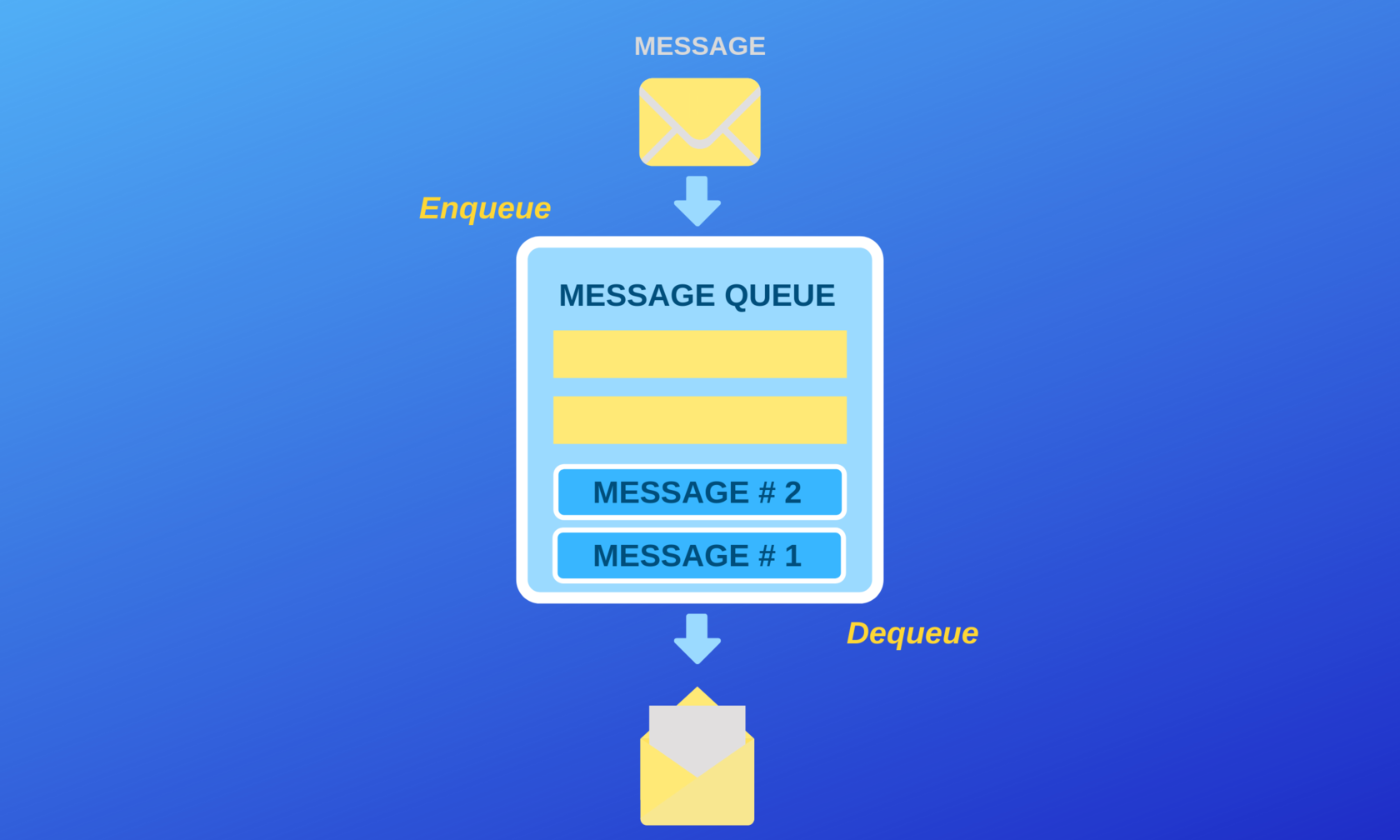 Messaging process
Messaging process
When Is a Message Broker Needed?
- If you want to control data feeds. For example, the number of registrations in any system.
- When the task is to send data to several applications and avoid direct use of their API.
- When you need to complete processes in a defined order, like a transactional system.
So, we can say that message brokers can do four important things:
- divide the publisher and consumer.
- store the messages.
- route messages.
- check and organize messages.
There are self-deployed and cloud-based messaging tools. In this article, I will share my experience of working with the first type.
Apache Kafka Message Broker
Pricing: Free
Official website: https://kafka.apache.org/
Useful resources: documentation, books
Pros:
- Easy to pick up
- Powerful event streaming platform
- Fault-tolerance and reliable solution
- Good scalability
- Free community distributed product
- Multi-tenancy
- Suitable for real-time processing
- Excellent for big data project
Cons:
- Lack of ready to use elements
- The absence of complete monitoring set
- Dependency on Apache ZooKeeper
- No routing
- Issues with an increasing number of messages
What do Netflix, eBay, Uber, The New York Times, PayPal, and Pinterest have in common? All these great enterprises have used or are using the world's most popular message broker, Apache Kafka.
The Story of Kafka Development
With numerous advantages for real-time processing and big data projects, this asynchronous messaging technology has conquered the world. How did it start?
In 2010, LinkedIn engineers faced the problem of integrating huge amounts of data from their infrastructure into a Lambda architecture. It also included Hadoop and real-time event processing systems.
As for traditional message brokers, they didn't satisfy LinkedIn's needs. These solutions were too heavy and slow. So, the engineering team developed a scalable and fault-tolerant messaging system without lots of bells and whistles. The new queue manager has quickly transformed into a full-fledged event streaming platform.
Apache Kafka Capabilities
The technology has become popular largely due to its compatibility. We can use Apache Kafka with a wide range of systems. They are:
- Web and desktop applications.
- Microservices
- Monitoring and analytical systems.
- Any required sinks or sources.
- NoSQL, Oracle, Hadoop, SFDC.
With the help of Apache Kafka, you can successfully create data-driven applications and manage complicated backend systems. The picture below shows the three main capabilities of this queue manager.

As you can see, Apache Kafka is able to:
- publish and subscribe to streams of records with excellent scalability and performance, which makes it suitable for company-wide use.
- durably store the streams, distributing data across multiple nodes for a highly available deployment.
- process data streams as they arrive, allowing you to aggregate, create windowing parameters, perform joins of data within a stream, etc.
Apache Kafka Key Terms and Concepts
First of all, you should know about the abstraction of a distributed commit log. This confusing term is crucial for understanding message brokers. Apache Kafka is based on the log data structure. This means a log is a time-ordered, append-only sequence of data inserts. As for other concepts, they are:
- topics (the stored streams of records).
- records (they include a key, a value, and a timestamp).
- APIs (Producer API, Consumer API, Streams API, Connector API).
Kafka Working Principle
There are two main patterns of messaging:
Both of them have some pros and cons. The advantage of the first pattern is the opportunity to easily scale the processing. On the other hand, queues aren't multi-subscriber. The second model provides the possibility to broadcast data to multiple consumer groups. At the same time, scaling is more difficult in this case.
Apache Kafka combines these two ways of data processing, getting the benefits of both of them. It should be mentioned that this queue manager provides better ordering guarantees than a traditional message broker.
Kafka Peculiarities
Combining the functions of messaging, storage, and processing, Kafka isn't a common message broker. It's a powerful event streaming platform capable of handling trillions of messages a day. Kafka is useful both for storing and processing historical data from the past and for real-time work. You can use it for creating streaming applications, as well as for streaming data pipelines.
If you want to follow the steps of Kafka users, you should be mindful of some nuances:
- the messages don't have separate IDs (they are addressed by their offset in the log).
- the system doesn't check the consumers of each topic or message.
- Kafka doesn't maintain any indexes and doesn't allow random access (it just delivers the messages in order, starting with the offset).
- the system doesn't have deletes and doesn't buffer the messages in userspace (but there are various configurable storage strategies).
Conclusion
Being a perfect open-source solution for real-time statistics and big data projects, this message broker has some weaknesses. The thing is it requires you to work a lot. You will feel a lack of plugins and other things that can be simply reused in your code.
I recommend you to use this multiple publish/subscribe and queueing tool when you need to optimize the processing of really big amounts of data (100,000 messages per second and more). In this case, Apache Kafka will satisfy your needs.
RabbitMQ Message Broker
Pricing: Free
Official website: https://www.rabbitmq.com
Useful resources: tools, best practices
Pros:
- Suitable for many programming languages and messaging protocols.
- Can be used on different operating systems and cloud environments.
- Simple to start using and to deploy.
- Gives an opportunity to use various developer tools.
- Modern, built-in user interface.
- Offers clustering and is very good at it.
- Scales to around 500,000+ messages per second.
Cons:
- Non-transactional (by default).
- Needs Erlang.
- Minimal configuration that can be done through code.
- Issues with processing big amounts of data.
The next very popular solution is written in the Erlang. As it's a simple, general-purpose, functional programming language, which consists of many ready to use components, this software doesn't require lots of manual work. RabbitMQ is known as a "traditional" message broker, which is suitable for a wide range of projects. It is successfully used for both the development of new startups and notable enterprises.
The software is built on the Open Telecom Platform for clustering and failover. You can find many client libraries for using the queue manager, written in all major programming languages.
The Story of RabbitMQ Development
One of the oldest open source message brokers can be used with various protocols. Many web developers like this software, because of its useful features, libraries, development tools, and instructions.
In 2007, Rabbit Technologies Ltd. had developed the system, which originally implemented AMQP. It's an open wire protocol for messaging with complex routing features. AMQP ensured cross-language flexibility of using message broking solutions outside the Java ecosystem. In fact, RabbitMQ perfectly works with Java, Spring, .NET, PHP, Python, Ruby, JavaScript, Go, Elixir, Objective-C, Swift, and many other technologies. The numerous plugins and libraries are the main advantage of the software.
RabbitMQ Capabilities
Created as a message broker for general use, RabbitMQ is based on the pub-sub communication pattern. The messaging process can be either synchronous or asynchronous, as you prefer. So, the main features of the message broker are:
- Support of numerous protocols and message queuing, changeable routing to queues, and different types of exchange.
- Clustering deployment ensures perfect availability and throughput. The software can be used across various zones and regions.
- The possibilities to use Puppet, BOSH, Chef, and Docker for deployment. Compatibility with the most popular modern programming languages.
- The opportunity for simple deployment in both private and public clouds.
- Pluggable authentication, authorization, and support for TLS and LDAP.
- Many of the proposed tools can be used for continuous integration, operational metrics, and work with other enterprise systems.
RabbitMQ Working Principle
Being a broker-centric program, RabbitMQ gives guarantees between producers and consumers. If you choose this software, you should use transient messages, rather than durable.
The program uses the broker to check the state of a message and verify whether the delivery was successfully completed. The message broker presumes that consumers are usually online.
As for the message ordering, the consumers will get the message in the published order itself. The order of publishing is managed consistently.
RabbitMQ Peculiarities
The main advantage of this message broker is the perfect set of plugins, combined with nice scalability. Many web developers enjoy clear documentation and well-defined rules, as well as the possibility of working with various message exchange models. In fact, RabbitMQ is suitable for three of them:
- Direct exchange model (individual exchange of a topic, one-by-one).
- Topic exchange model (each consumer gets a message which is sent to a specific topic).
- Fanout exchange model (all consumers connected to queues get the message).
Here you can see the gap between Kafka and RabbitMQ. If a consumer isn't connected to a fanout exchange in RabbitMQ, the message will be lost. At the same time, Kafka allows us to avoid this, because any consumer can read any message.
Conclusion
As for me, I like RabbitMQ due to the opportunity to use many plugins. They save time and speed-up work. You can easily adjust filters, priorities, message ordering, etc. Just like Kafka, RabbitMQ requires you to deploy and manage the software. But it has a convenient built-in UI and allows for the use of SSL for better security. As for its ability to cope with big data loads, here RabbitMQ is inferior to Kafka.
To sum up, both Apache Kafka and RabbitMQ are truly worth the attention of skilled software developers. I hope my article will help you find suitable big data technologies for your project.
Published at DZone with permission of Vitaliy Samofal. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments