Java Collection Overhead
In this article, we will concentrate on the overhead caused by lists that contain two or three elements, which can be easily overlooked.
Join the DZone community and get the full member experience.
Join For FreeThe Java Virtual Machine enables Java applications to be platform-independent while optimizing performance. One crucial component to understand when considering performance, especially memory utilization, is how the Java Collections Framework, specifically the ArrayList, handles size and capacity.
In this article, we will concentrate on the overhead caused by lists that contain two or three elements. The reason for this is that it’s a more common situation, and it can be easily overlooked.
The Difference Between Size and Capacity
The size of a list refers to the number of elements currently stored in it. It can change as we add or remove elements. The method List.size() provides this number. If we have a list with ten items, its size is ten.
The capacity of a list pertains to the amount of memory allocated for storing elements, regardless of whether these memory locations are currently in use. Capacity is primarily a concern for lists backed by arrays, like ArrayList. Capacity represents the maximum number of elements the list can hold before resizing its internal storage array. The capacity is always greater than or equal to the size of the list.
If we initialize an ArrayList and add ten items to it; its size is ten. However, the underlying array might have a capacity for fifteen items. This means adding five more items to the list wouldn’t trigger an expansion of the underlying array.
Understanding the distinction between size and capacity is crucial. While the size determines the actual data count, the capacity impacts memory utilization and can influence performance due to the potential need for array resizing and data copying.
The Initial Capacity of a List
The ArrayList class has a default initial capacity. As of Java 17, this capacity is ten. If we know we’ll have more or fewer elements, it’s often a good idea to set an initial capacity to reduce the number of resizes.
The LinkedList, for example, does not have a concept of capacity. It’s a doubly-linked list, meaning each element points to both its predecessor and successor. There’s no underlying array that needs resizing.
When considering JVM performance, understanding the initial capacity of lists and how they grow is crucial. Setting appropriate initial capacities can reduce the need for list resizing, reduce memory churn, and improve performance.
Effect on the Code
Let’s run two tests to compare the performance of the code:
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 1, jvmArgs = {"-Xlog:gc:file=list-creation-%t.txt,filecount=10,filesize=40gb -Xmx6gb
-Xms6gb"})
public void listCreationBenchmark(HeapDumperState heapDumperState, Blackhole blackhole) {
final List<Integer> result = new ArrayList<>();
result.add(1);
result.add(2);
result.add(3);
blackhole.consume(result);
}
@Benchmark
@BenchmarkMode(Mode.AverageTime)
@Fork(value = 2, jvmArgs = {"-Xlog:gc:file=limited-capacity-list-creation-
%t.txt,filecount=10,filesize=40gb -Xmx6gb -Xms6gb"})
public void limitedCapacityListCreationBenchmark(HeapDumperState heapDumperState, Blackhole blackhole) {
final List<Integer> result = new ArrayList<>(3);
result.add(1);
result.add(2);
result.add(3);
blackhole.consume(result);
}Note that HeapDumperState is a state that triggers a heap dump after each iteration so that we will get the information about created objects. All the tests run ten ten-minute iterations in two separate forks. The overall duration of each test took around one hour and forty minutes.
Overall, the tests didn’t show a significant difference, and anecdotally, all of the runs actually show that the first option with default capacity might be faster:
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| OverheadBenchmark.limitedCapacityListCreationBenchmark | thrpt | 20 | 116365294.187 | ± 4748264.227 | ops/s |
| OverheadBenchmark.listCreationBenchmark | thrpt | 20 | 121014905.085 | ± 188451.671 | ops/s |
The average time for a single operation is so minuscule that it’s hard to tell the difference in these tests. Please bear in mind that we’re measuring the creation of an ArrayList with three elements against ten elements.
Memory Footprint
When optimizing for performance, it’s important to understand the impact of memory allocation decisions on the JVM. We might think that the default capacity of an ArrayList is harmless. However, in some cases, there are implications, not only for large lists or high-frequency list operations but also for lists with a small number of elements.
Let’s look deeper into the garbage collection logs produced by these tests. We’ll be using HeapHero for this analysis. The initial guess would be that the ArrayList test with a default capacity would take more heap space, have more garbage collection cycles, and lower throughput.
The Increase in Memory Use
When initializing an ArrayList with the default constructor (i.e., without specifying a capacity), the list allocates memory for ten elements. If we add only three elements, we use 30% of the allocated memory, leaving 70% unused.
If we initialize the ArrayList with a capacity of three (new ArrayList<>(3)), it will allocate memory just for those three elements. Consequently, there’s less wastage.
This is clearly seen in the difference in average heap sizes. The ArrayList with explicitly declared capacity provided the following results:
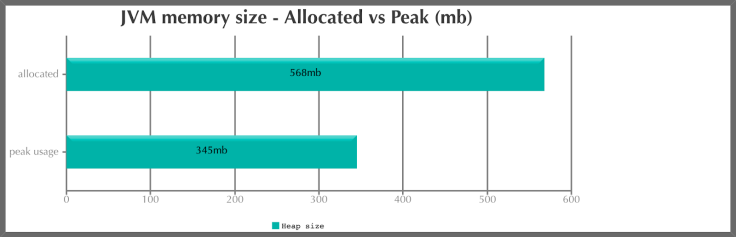 Fig 1: Memory allocation for an ArraysList with explicit capacity
Fig 1: Memory allocation for an ArraysList with explicit capacity
At the same time, the ArrayList with default capacity, as we expected, resulted in consuming more memory:
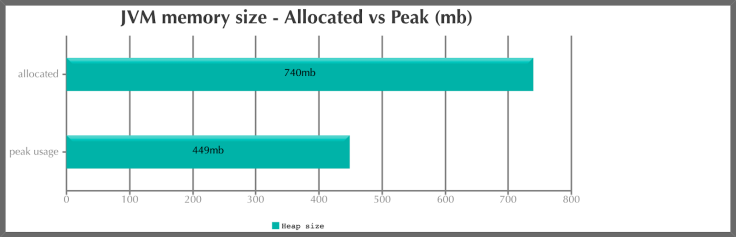 Fig 2: Memory allocation for an ArraysList with default capacity
Fig 2: Memory allocation for an ArraysList with default capacity
The Effect on the Throughput
Due to the memory footprint, JVM has to manage memory more aggressively with more frequent garbage collection cycles. Let’s compare the KPIs for both cases:
 Fig 3: Memory allocation for an ArraysList with explicit capacity
Fig 3: Memory allocation for an ArraysList with explicit capacity
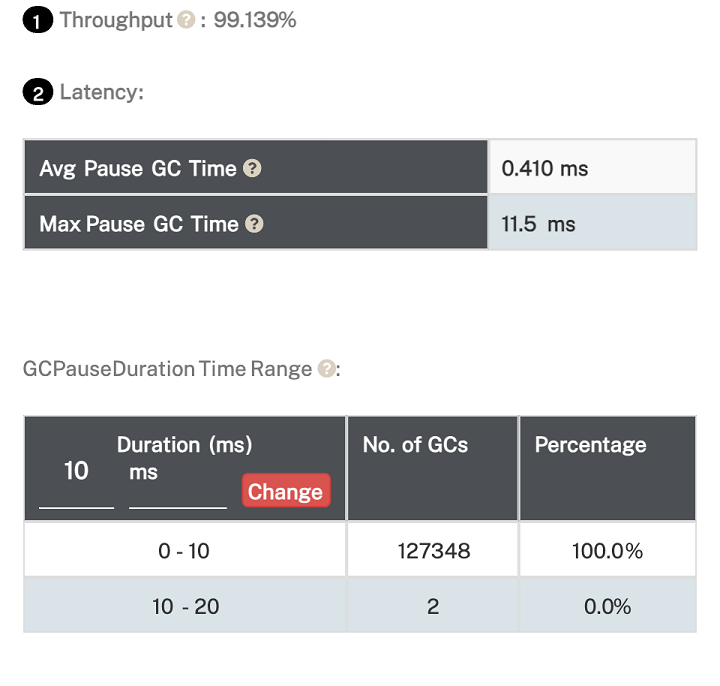 Fig 4: Throughtput for an ArraysList with default capacity
Fig 4: Throughtput for an ArraysList with default capacity
ArrayLists.
Please consider that the objects are becoming unreachable almost instantaneously. However, on a busy web server, this might cause more issues.
yCrash Analysis
While the previous metrics identified the issue, they didn’t identify the source of it. To find it out, we might use heap dump analysis to identify the heap’s state. In particular, we would concentrate on the Inefficient Collection section.
This section provides a good overview of the wasted memory due to oversized collections. The main cause of this problem is the difference between the capacity and the size of the collections.
The heap dump was captured before a garbage collection cycle. This way, we could better see the collection objects in our heap:
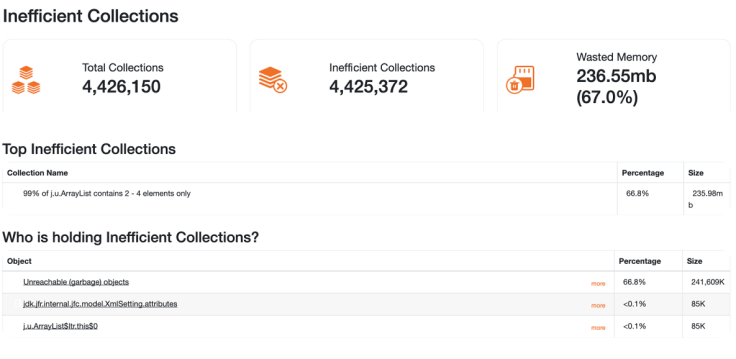 Fig 5: Inefficient collection information in yCrash
Fig 5: Inefficient collection information in yCrash
From this, we can see that we waste memory, and most of our collections (almost all of them) take up more space than they need.
Conclusion
Constant monitoring and analysis of an application is crucial to its healthy and performant work. Sometimes, it’s hard to see issues with occasional heap dumps and garbage collection logs. That’s why it’s so important to have a system that would analyze the application constantly. yCrash application can help with the monitoring and not only produce a better user experience but also give a service a competitive advantage on the market.
Published at DZone with permission of Eugene Kovko. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments