Kafka Connect: Strategies To Handle Updates and Deletes
Get tips on managing updates and deletes using Kafka Connect, which allows you to set up a continuous flow of data from one data source to a target database.
Join the DZone community and get the full member experience.
Join For FreeKafka Connect is a great tool that allows you easily set up a continuous flow of data from one data source to a target database. It's very simple to configure, and quite useful when you have legacy systems that serve business data that you want, for one reason or another, in a different place. My typical use case is to move the data from Oracle tables to MongoDB collections consumed by microservices. This allows better scalability since we don't have to heavily hit the source tables with production queries.
One of the things not easily explained when you open your Kafka Connect manual is how you handle operations that modify existing data that was already moved; or in other words, updates and deletes. I thought this was a limitation of the typical JDBC/MongoDB pair of connectors we were using. At some moment I explored the Debezium Connectors that promised to capture these types of events and replicate them in the target database. The POC wasn't successful for us with OracleDB. We had limited access to these databases, and the level of configuration required for these connectors was not a straightforward solution.
As we kept playing with connectors, we found there are ways to handle these scenarios. I will explain two strategies. The first one, which is the most desirable one, requires a specific design in our source database. The second one is an alternative solution if that design is not present and cannot be changed for any reason.
The Basic Example
Let's imagine that we have an old system that handles promotions. To simplify our example, let's say we have this basic table with three columns. We need to continuously move this data from the SQL database to a document-based one like MongoDB.

Basic Concepts
First, we need to make a quick description of two types of Kafka connectors that can be used: incremental and bulk. Strictly speaking, the JDBC connector has four modes: bulk, timestamp, incrementing, timestamp+incrementing. I'm grouping the last three in incrementals because those share the same basic concept. You want to only move the new data that is detected from the source.
Bulk connectors always move the entire dataset. However, a lot depends on the use case of the data we're moving. Ideally, incremental connectors are the best solution, as it's easier to manage small chunks of new data in terms of use of resources, or readiness of the data. The questions here are: how does Kafka Connect, using purely SQL queries, and how does it know when new data was inserted in the source?
The source connector config can use one of these two properties (or both): incrementing.column.name & timestamp.column.name. Incrementing property uses an incremental column like an auto-generated id to detect when a new row is inserted. Timestamp property uses a column that is a DateTime to detect new changes. Kafka Connect holds an offset to append it to the SQL query used to grab our data from the source.
For example, if our table is called "promotions", we would use in our query property for the source connector as follows:
"query": "SELECT TITLE, DISCOUNT, PRODUCT_CATEGORY FROM PROMOTIONS",
"timestamp.column.name": "LAST_UPDATE_DATE"Kafka inside modifies the query to something like this:
SELECT * FROM ( SELECT TITLE, DISCOUNT, PRODUCT_CATEGORY FROM PROMOTIONS)
WHERE LAST_UPDATE_DATE > {OFFSET_DATE}On the sink connector side, which is the connector that saves the data in the target database, we need to set up a strategy to make proper upserts based on an ID. You can read more about that in the documentation of the sink connector you're using. In the case of the MongoDB connector, the typical setting I use is:
"document.id.strategy": "com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInValueStrategy",
This indicates that the _id for our documents will come from the source data. In that case, our source query should include an _id column:
"query": "SELECT PROMO_ID as \"_id\", TITLE, DISCOUNT, PRODUCT_CATEGORY FROM PROMOTIONS"At this point, we have the basic configuration to detect new insertions. Every time a new promotion is added with a new timestamp, the source connector will grab it and move it to the desired destination. But having this exact same configuration, we can accomplish our total goal of detecting updates and deletions. What we need is a proper design of our data source.
Modifying the Timestamp Column on Every Update
If we want to make sure our updates are handled and reflected in the target database, we need to make sure that every update that is made in the source table(s) also updates the timestamp column value. That can be accomplished via the application that writes to it passing the current timestamp as a parameter of the update operation, or creating a trigger that listens to the update event. And since the sink connector handles upserts based on the id, the update is also reflected in the target document.
Soft Deletions
To be able to handle deletions, we require our previous step along with what is considered good practice in database designs: soft deletions. This is the practice of not deleting (hard deletion) a record in the database whenever that is needed, but simply marking it with a special flag that indicates the record is no longer valid/active. This has its own benefits in terms of recoverability or auditing. This means, of course, that our applications or store procedures need to know about this design and filter out the inactive records when querying the data.
If it's hard to update the application that deletes the records to make soft deletions instead (in case the data source was not designed to consider that), we can also use a trigger to capture the hard deletion and do a soft one instead.
What we need to do for our Kafka Connect purposes is to also change our timestamp column value whenever the record is flagged as inactive. In this example, we are setting the HOT SUMMER promotion to non-active setting the ACTIVE column in 0. LAST_UPDATE_DATE is also modified with the most recent date which will make the source connector grab the record.

When the data is moved, for example to MongoDB, in order to consume it we would need to filter also based on this ACTIVE field:
db.getCollection('promotions').find({active: 1})Versioned Bulks
"query": "SELECT PROMO_ID as \"_id\", TITLE, DISCOUNT, PRODUCT_CATEGORY,
TO_CHAR(SYSDATE, 'yyyymmddhh24miss') AS SNAPSHOT FROM PROMOTIONS"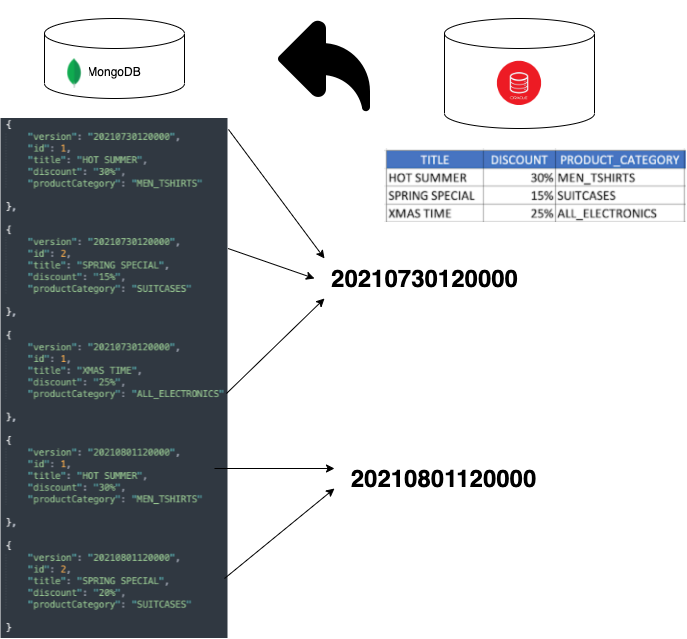
This approach is a little tricky, and should not be our first option, but it's an option I wanted to leave out there in case it's useful for someone.
Opinions expressed by DZone contributors are their own.
Comments