Kafka Replication — Manipulate Your Topics and Records in Mirror Maker V1.0 and V2.0
Using the features of a tool might not enough. Check how to insert your own Java code into the Kafka mirror maker tools.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we will be working with both mirror maker v1.0 and v2.0. Therefore, we are doing some abbreviations.
- Mirror maker v1.0 -> mmv1
- Mirror maker v2.0 -> mmv2
Find the Project
Find all the docker images and code over here.
Have questions or wanna know more? Follow me on twitter Rodrigo_Loza_L
Introduction
Apache Kafka has released tools that can be used to replicate data between Kafka datacenters. Each has its own level of manipulation, architecture, performance and reliability. In this document, we will explore how to alter a data replication pipeline using the two versions of the Kafka mirror maker tool.
Manipulate the Replication Pipeline Records and Topics Using Kafka Mirror Maker V1.0
This version of the mirror maker tool allows to build the following architecture: This architecture allows the replication of topics and data from the source cluster to the target cluster. Some disadvantages that are worth mentioning are the following:
This architecture allows the replication of topics and data from the source cluster to the target cluster. Some disadvantages that are worth mentioning are the following:
- Topic configurations are not copied which means that default topic configurations will be used in the target cluster in order to create the topics.
- A consumer and producer are used to replicate the data. Sometimes it gets stuck or stops replicating. This forces the administrator to change the consumer group id in order to replicate all the data again. Otherwise, a restart is used to register the consumer group in the source cluster.
Let's check how to manipulate this flow of data between the Kafka clusters. In this version of mmv1 this is possible by KIP-3 which introduced the possibility to override the handle Method on the class MirrorMaker.MirrorMakerMessageHandler.
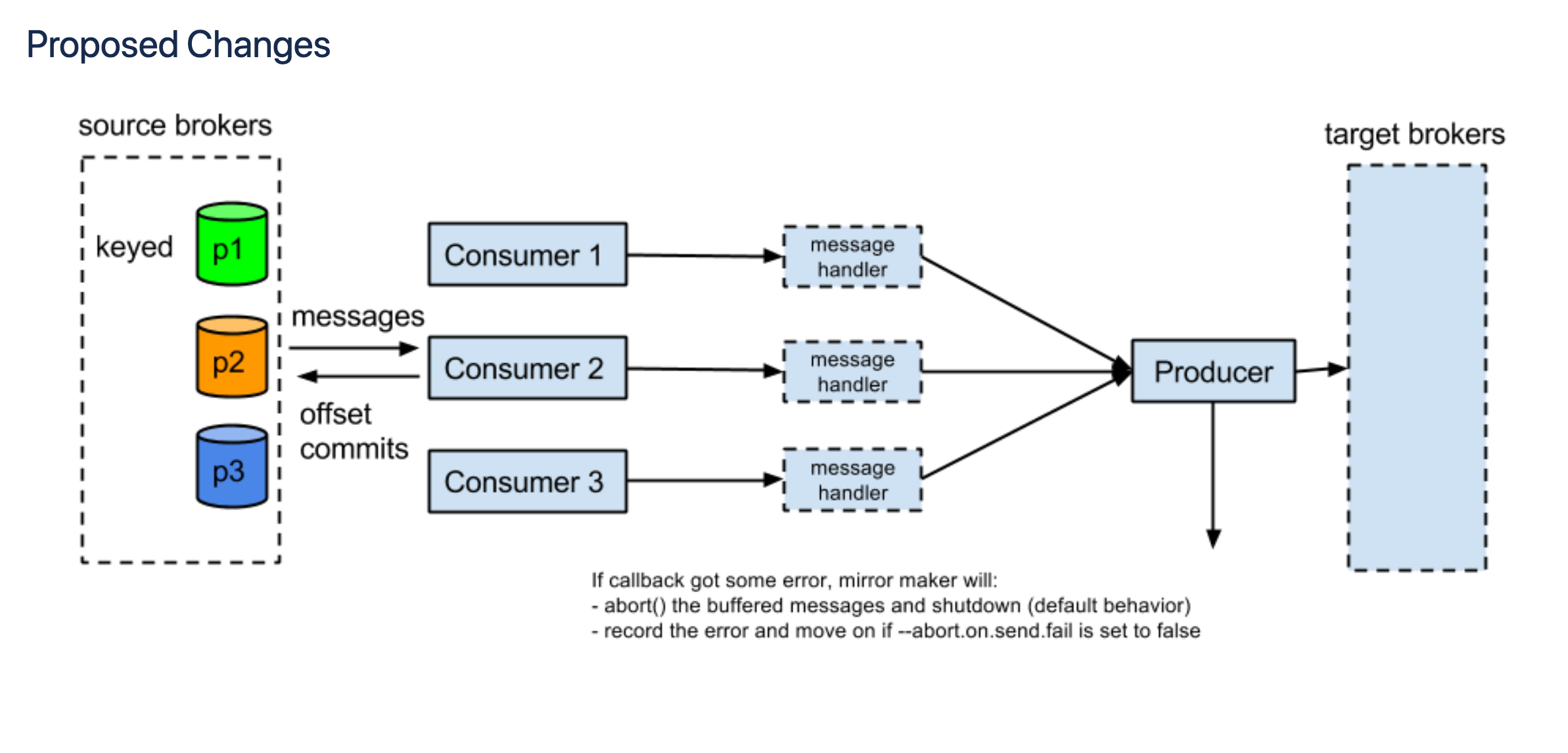
So what is it that we want to solve? A common case is topic mapping in which you have a topic on the source cluster. Your task is to replicate the data of that topic to another cluster. But, you don't want the topic to be called the same. Therefore, you need to rename that topic.

In the image above the topic named my_topic_1 in the source cluster is renamed to my_topic in the target cluster. This was possible by the TopicMapping class. Let's see how to implement it.
Create a java project and add the following dependencies. In my case I used gradle.
xxxxxxxxxx
dependencies {
compile group: 'org.apache.kafka', name: 'kafka_2.12', version: '2.3.0'
compile group: 'org.apache.logging.log4j', name: 'log4j-api', version: '2.13.3'
compile group: 'org.apache.logging.log4j', name: 'log4j-core', version: '2.13.3'
}
Next let's code the handle method that would deal with the topic mapping.
x
public class TopicMapping implements MirrorMaker.MirrorMakerMessageHandler {
private static final Logger logger = LoggerFactory.getLogger(TopicMapping.class);
private final String TOPIC_LIST_SPLITTER_TOKEN = ",";
private final String TOPIC_MAP_SPLITTER_TOKEN = ":";
private HashMap<String, String> topicMaps = new HashMap<>();
public TopicMapping(String topicMappingArgument) {
String[] listOfTopics = topicMappingArgument.split(TOPIC_LIST_SPLITTER_TOKEN);
for (int index=0; index<listOfTopics.length; index++){
String[] topicMap = listOfTopics[index].split(TOPIC_MAP_SPLITTER_TOKEN);
logger.info(stringFormatter("Topic map. Source: {0} Target: {1}", topicMap[0], topicMap[1]));
topicMaps.put(topicMap[0], topicMap[1]);
}
}
public List<ProducerRecord<byte[], byte[]>> handle(BaseConsumerRecord record) {
try {
// Get record information.
String headers = record.headers().toString();
//String key = new String(record.key(), Charset.forName("UTF-8"));
String value = new String(record.value(), Charset.forName("UTF-8"));
String topic = record.topic();
Long timestamp = record.timestamp();
String message = stringFormatter("New record arrived with headers: {0} value: {1} topic: {2}", headers, value, topic);
// Check if the topic is in topicMaps.
String targetTopic = topicMaps.getOrDefault(topic, null);
if (targetTopic != null) {
return Collections.singletonList(new ProducerRecord<byte[], byte[]>(
targetTopic,
null,
timestamp,
record.key(),
record.value(),
record.headers()
));
} else {
return Collections.singletonList(new ProducerRecord<byte[], byte[]>(
topic,
null,
timestamp,
record.key(),
record.value(),
record.headers()
));
}
}
catch (Exception e){
logger.error("NPE found in topic.");
e.printStackTrace();
return Collections.EMPTY_LIST;
}
}
public String stringFormatter(String line, Object ... params){
return new MessageFormat(line).format(params);
}
}
The try/catch is very important in the handle method. If you try the decode the record you may get a lot of NPEs depending on the data that you are sending. It depends on whether you are sending a record with keys, headers, value, etc.
Compile the project and produce the jar. The jar must be copied to kafka/libs/ afterwards so it can be read by the mirror maker message handler parameters.
This setup will take you sometime so I recommend you to check my repository with the examples here. Follow the next steps.
- Run build.sh
- Deploy the kafka nodes with this script
- Deploy mmv1 with this script
Check the entrypoint script of the Docker image. Note the topic whitelist is hardcoded to my_topic_.* so only topics that start with the pattern my_topic_ will be replicated. Check the message handler arguments in the yaml file. The mapping will follow the rules:
- my_topic_1 will be translated to my_topic
- my_topic_2 will be translated to my_other_topic
Let's test the replication pipeline. I created my_topic_1 and my_topic_2 in the source cluster manually.

Let's write some data to the topics.
Finally, let's verify the data has been written in the topics of the target cluster.
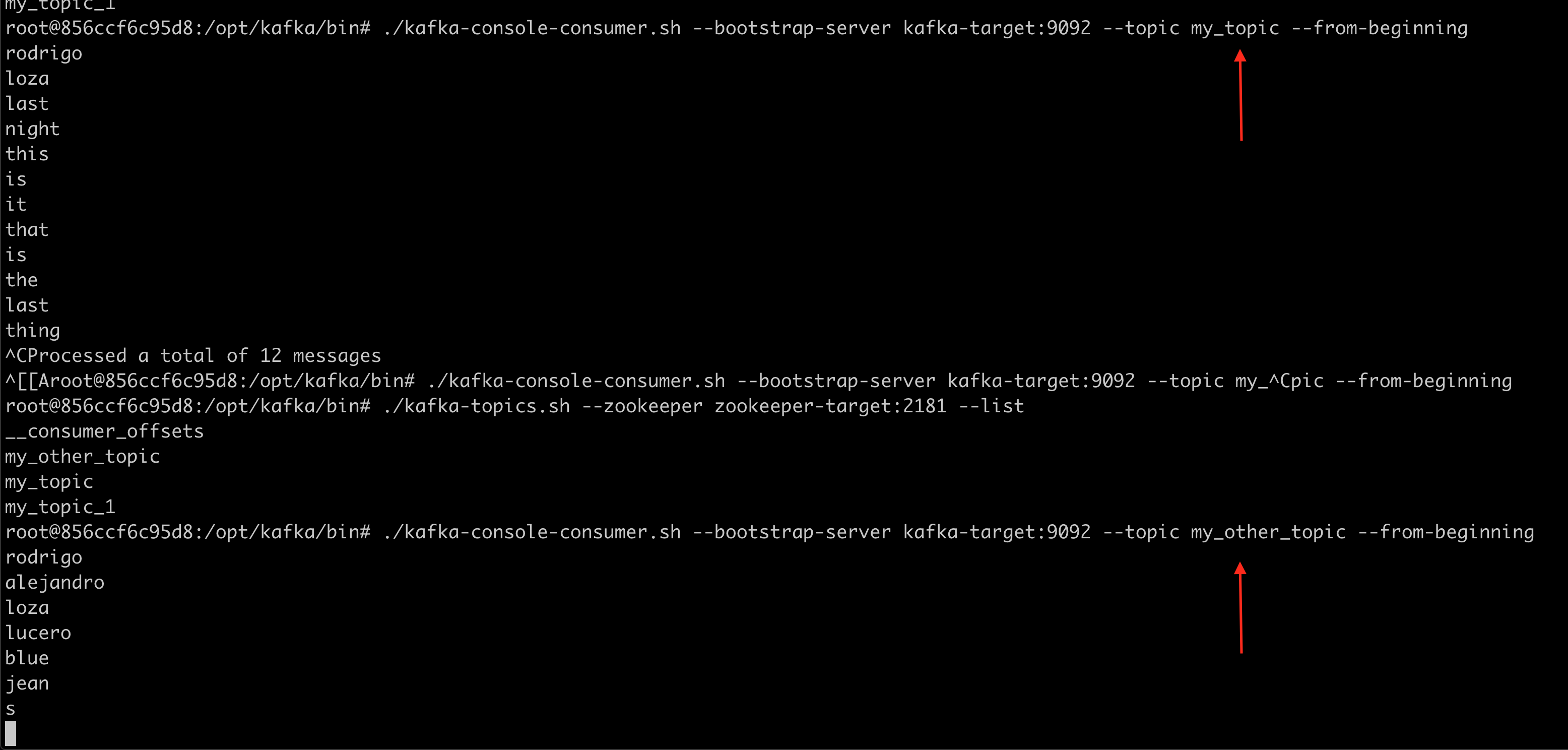
Note the data has been written to the correct mapped topics.
Before we move onto the next example note that the potential in the message handler method is amazing. You can apply any logic and transform the actual Kafka record as you want.
Manipulate the Replication Pipeline Topics Using Kafka Mirror Maker V2.0
The next example is another replication pipeline customization but using Kafka mirror maker version 2. For this example we will use an active-to-passive architecture. Sadly I haven't figured out how to manipulate the actual Kafka records yet (I guess tweaking this class).
Nonetheless, we can play around with the topics and create the topic mappings as we did in the previous example. Now this is what you really want to do because not only does mmv2 replicate your data and topics but also the topic configs. So if your topic is compacted on one side, it will compacted on the other side as well.
The methods that you need to override are in this class. It is a bit more complicated to understand but I got some help checking this repository. The replication policy that we will implement will be called identity replication policy.
x
public class IdentityMapperTopicReplicationPolicy extends DefaultReplicationPolicy {
private static final Logger logger = LoggerFactory.getLogger(IdentityMapperTopicReplicationPolicy.class);
public static final String TOPIC_REPLICATION_MAPS_ENVIRONMENT_VARIABLE_NAME = "TOPIC_REPLICATION_MAPS";
public static final String TOPICS_REPLICATION_MAPS_SEPARATOR = ":";
public static final String TOPICS_REPLICATION_MAP_SEPARATOR = ",";
private String sourceClusterAlias;
private HashMap<String, String> topicMappings = new HashMap<>();
public void configure(Map<String, ?> props) {
HashMap<String, List<String>> maps = new HashMap<>();
// Load source cluster alias from props.
sourceClusterAlias = props.get("source.cluster.alias").toString();
// Load the topic mapping parameter from the environment variables.
Map<String, String> environmentVariables = System.getenv();
String topicMappingEnvVar = null;
for (Map.Entry<String, String> environmentVariable : environmentVariables.entrySet()) {
if (environmentVariable.getKey().equals(TOPIC_REPLICATION_MAPS_ENVIRONMENT_VARIABLE_NAME)){
logger.info("TOPICS_REPLICATION_MAPS: " + environmentVariable.getValue());
topicMappingEnvVar = environmentVariable.getValue();
break;
}
}
if (topicMappingEnvVar == null){
String errorMessage = Utils.StringFormatter("{0} environment variable has not been set.", TOPIC_REPLICATION_MAPS_ENVIRONMENT_VARIABLE_NAME);
throw new RuntimeException(errorMessage);
}
// Load the mappings to a hashmap.
List<String> topicsMaps = Arrays.asList(topicMappingEnvVar.split(TOPICS_REPLICATION_MAPS_SEPARATOR));
for (String topicsMap : topicsMaps){
List<String> kafkaTopicsMap = Arrays.asList(topicsMap.split(TOPICS_REPLICATION_MAP_SEPARATOR));
String sourceTopic = kafkaTopicsMap.get(0);
String targetTopic = kafkaTopicsMap.get(1);
topicMappings.put(sourceTopic, targetTopic);
}
}
public String formatRemoteTopic(String sourceClusterAlias, String topic) {
String targetTopic = topicMappings.getOrDefault(topic, null);
logger.info(Utils.StringFormatter("Source topic: {0} Target topic: {1}", topic, targetTopic));
if (targetTopic != null) {
return targetTopic;
} else {
return topic;
}
}
public String topicSource(String topic) {
return topic == null ? null : sourceClusterAlias;
}
public String upstreamTopic(String topic) {
return null;
}
public boolean isInternalTopic(String topic) {
return topic.endsWith(".internal") || topic.endsWith("-internal") || topic.matches("__[a-zA-Z]+.*") || topic.startsWith(".");
}
}
Code highlights:
- The configure method is alike to the constructor we saw in the message handler of mmv1. It works as a starting point. We are using it to load the topic mappings.
- The formatRemoteTopic method is the one that produces the topic name in the target cluster. Any topic remapping should be done here. In this example, we load a map of topic mappings. If the whitelisted topic is in the map, it is mapped. Otherwise it is copied with the same name.
- The topicSource and upstreamTopic methods are a bit confusing. The way to make sure replication identity is achieved is by setting upstreamTopic to return always null and sourceTopic must return null if the topic variable is null otherwise return the source cluster alias.
- The method isInternalTopic() can be override in case it has a conflict with your own topics. In a production scenario I had multiple topics that started with ___ (triple underscore). So these could not be replicated until I changed the code.
Let's move to the example. Follow the next steps:
- Use this Dockerfile to build mmv2. It will build a docker image for Kafka and add the jar of the replication policy to the libs folder.
- Deploy the Kafka nodes using this bash script.
- Run this bash script to start mmv2 so replication starts between the two Kafka nodes.
Note this is the yaml of mmv2. Here is an environment variable with the topic mappings.
- source_topic_1 is mapped to target_topic_1.
- source_topic_2 is mapped to target_topic_2.
- Any other topic is copied as an identity.
Let's test the replication policy.
First, let's create source_topic_1, source_topic_2 and rodrigo_topic_1 in the source Kafka node.
x
./kafka-topics.sh --zookeeper zookeeper-source:2181 --partitions 1 --replication-factor 1 --topic source_topic_1 --create
./kafka-topics.sh --zookeeper zookeeper-source:2181 --partitions 1 --replication-factor 1 --topic source_topic_2 --create
./kafka-topics.sh --zookeeper zookeeper-source:2181 --partitions 1 --replication-factor 1 --topic rodrigo_topic_1 --create
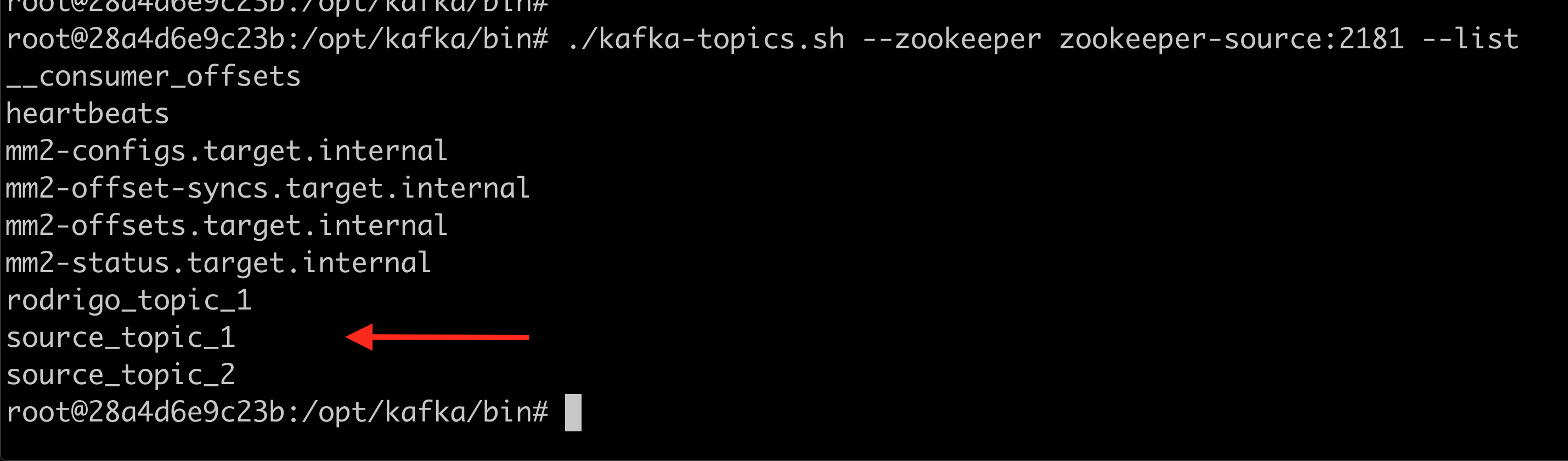
Let's check the target Kafka node to verify the replication policy has created the mapped and identity topics. 
The mapped topics and the identity topic have been created.
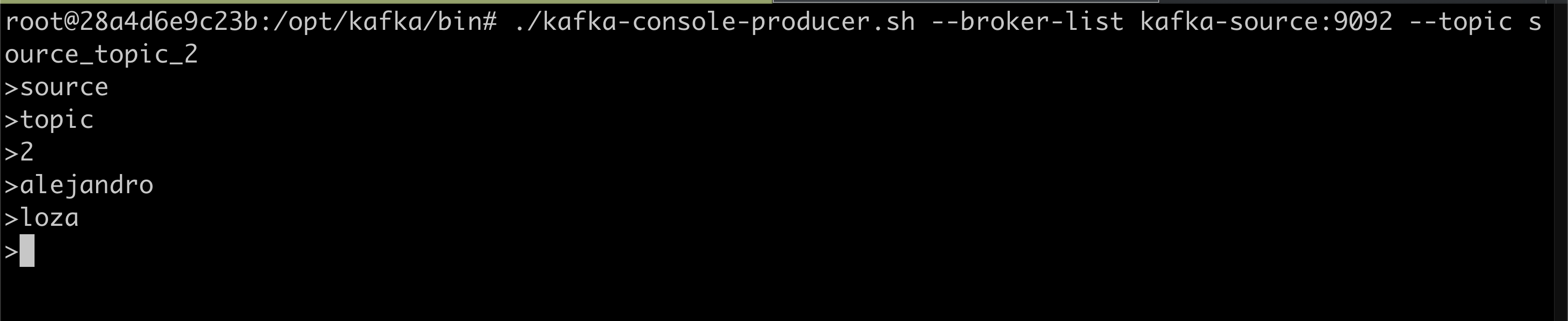
Finally, let's produce some data on the source topics. And validate the data is being streamed to the mapped and identity topics.
source_topic_1 into target_topic_1

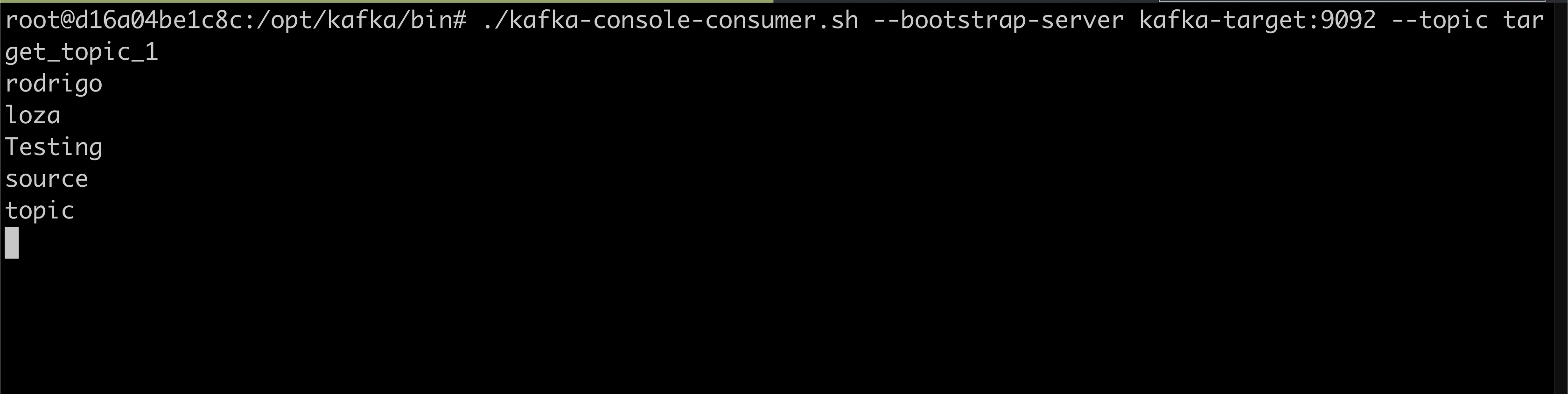
source_topic_2 into target_topic_2

rodrigo_topic_1 into rodrigo_topic_1


That's it. You have the power to manipulate data streaming in mmv2.
Conclusion
In this document we have made a review of both of the mirror maker tool releases. In addition, we have seen how to tweak the code in order to alter the replication pipelines. In conclusion, the tools presented in this document have different levels of manipulation, have different performance and have their own architecture to achieve their goals; finally, each architecture has its pros and cons. Thus, the boundaries of the problem must be defined before picking the Kafka mirror maker tool and its version.
Opinions expressed by DZone contributors are their own.
Comments