Knowledge Graphs and Analytics Without Graph Databases for Gen-AI
A new paradigm that is cost-effective and efficient.
Join the DZone community and get the full member experience.
Join For FreeGraphs are more relevant and useful today than ever. Thanks to the AI revolution happening right now, engineers are thinking about the opportunities around Gen-AI, leveraging open Gen-AI solutions with dynamic prompting, data grounding, and masking which further pushes them to think about effective solutions like knowledge graphs.
Engineer, Mary is working on a data grounding problem and is considering building their Knowledge Graph for an AI solution for personalized product recommendations at work, and starts to wonder about
- How to build these graphs,
- Where to store them,
- How to integrate with vast amounts of data we have from wide sources of databases, warehouses, and lake houses?
Mary’s concern seems very reasonable and if she has to now write application logic to generate Graphs, connecting with a new Graph database to store them, which comes with its challenges like integration, security, costs, reliability, and technology learnings.
Mary can overcome these cumbersome issues with a simple yet powerful application of Native Graph Analytics Engines.
Yes, it’s possible today to achieve graph queries on existing data without materializing the graphs or using graph databases.
Wondering how graph analytics and graph queries are achieved natively on pre-existing data in databases, warehouses, and lakes!! Let’s take a sneak peek.
Let me take a step back and explain what are Graphs and How is Graph analytics beneficial over traditional data analytics.
In Software Engineering, Graphs are data structures to model and represent relationships between entities. They consist of vertices (nodes) and edges (relationships) that connect these vertices, and can be directed or undirected, weighted or unweighted.
Graph analytics is a powerful emerging form of data analysis on graph based data that helps businesses understand complex relationships between various data entities. It helps in understanding, visualizing and deriving meaningful insights out of the complex relationships.
How is graph analytics with graph databases better than traditional SQL analytics on relational stores?
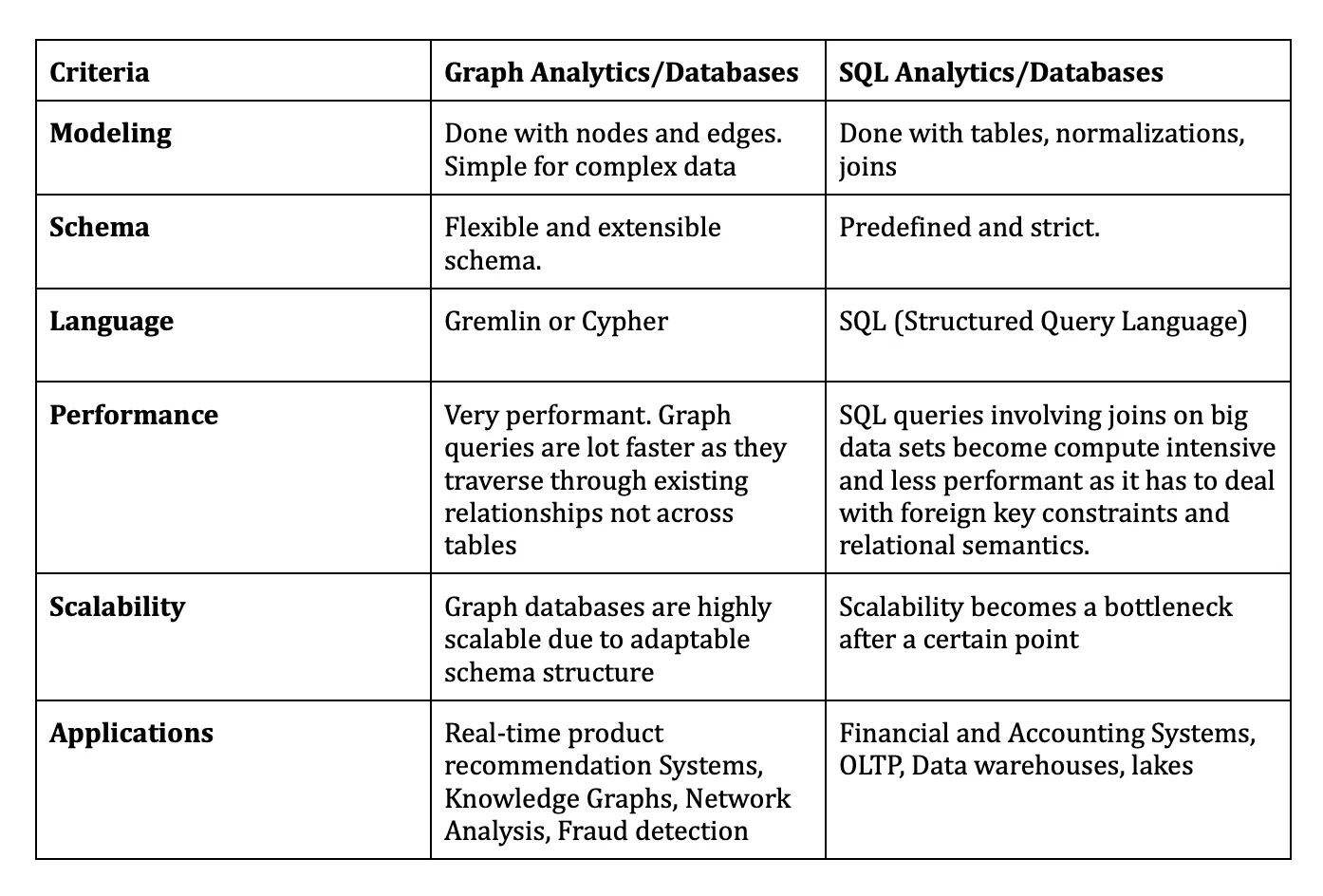 Table Comparison of Graph vs Traditional Analytics
Table Comparison of Graph vs Traditional Analytics
We can see graph analytics are more performant, flexible, extensible, scalable, and relevant for intelligent|AI analytics.
How Graph Analytics Is Achieved Today
Most of the enterprises today for leveraging Graph analytics generate Graphs and store them in graph databases. Neo4j, TigerGraph, Amazon Neptune, and OrientDB are widely adopted as graph databases in the industry.
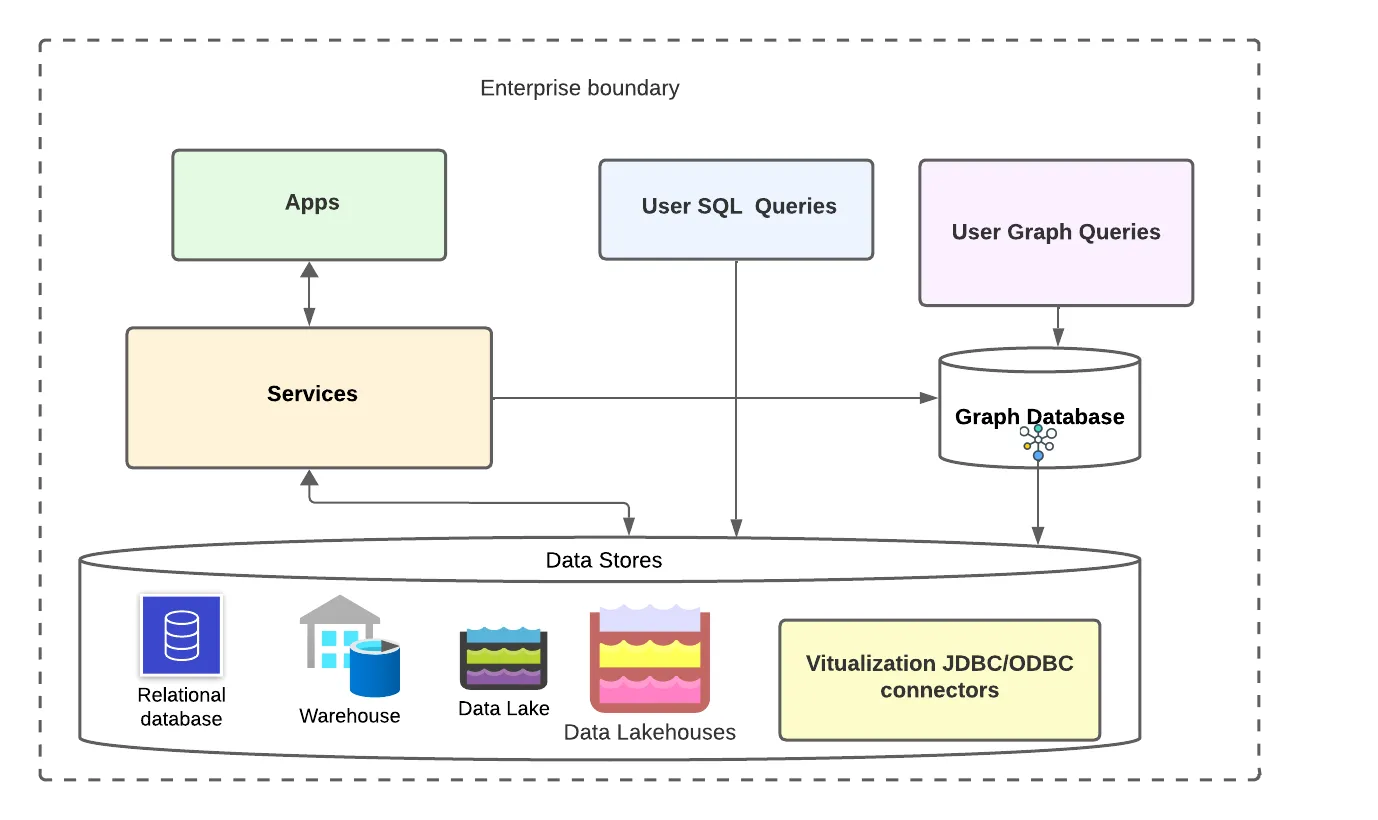
Source: Author
The New Paradigm
Native Graph Analytics Engines are the new paradigm where we can directly achieve graph queries, and visualization on existing relational/SQL data without using Graph Databases in between and still leveraging all the advantages we get from both Graph and Traditional Analytics approaches.
This seems to be a very powerful tool with a lot of opportunities around Graph Analytics and seems to altogether can thrown away using redundant graph databases and shift to this new paradigm of Native Graph analytics.
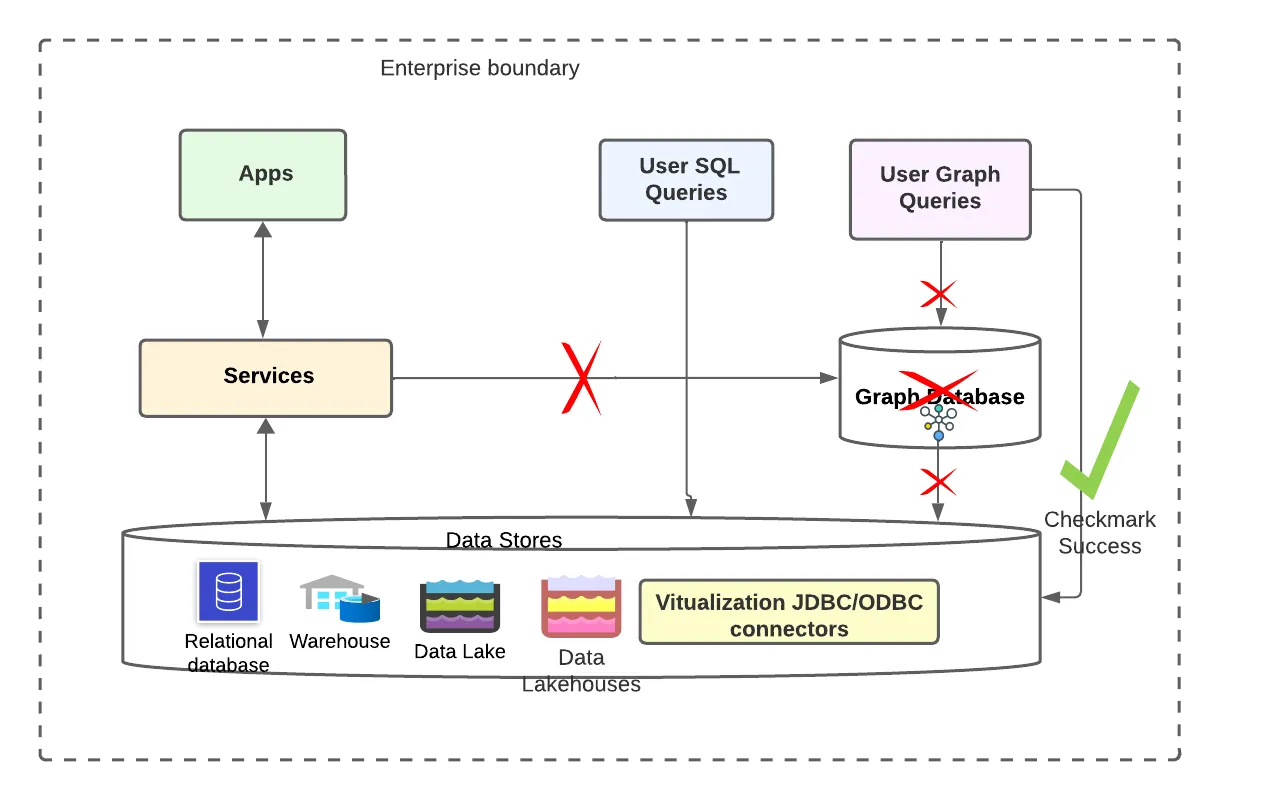 Removing Graph databases from the flow
Removing Graph databases from the flow
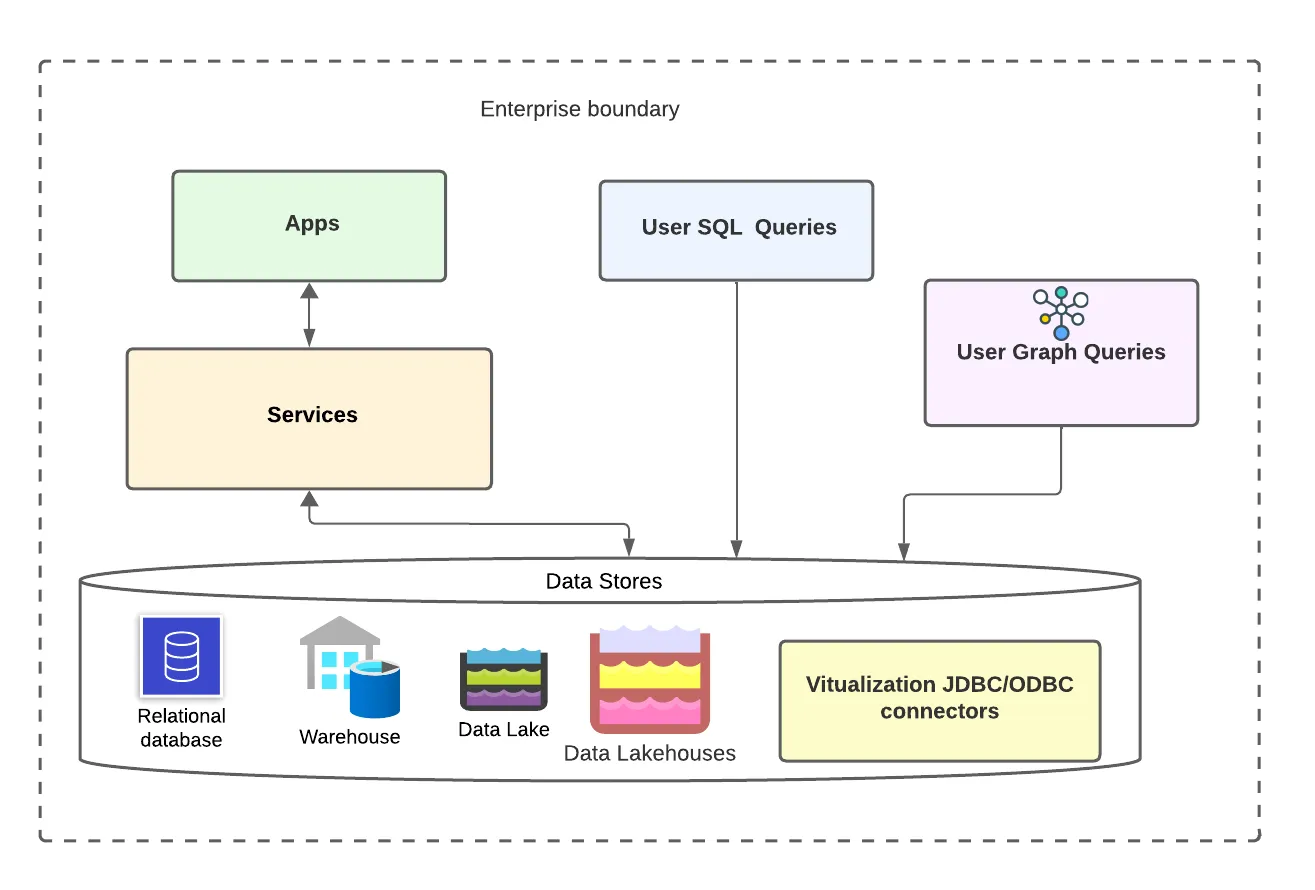
Ultimate user flow diagram
Three Birds at a Shot!
If we can apply graph queries on existing traditional data stores like relational databases, warehouses, lakes, or lake houses, we can achieve three things in one go,
- Zero-ETL: No need for copying, migration, or ETL of data from existing data stored to build and store graphs. Also, no need to copy base relational data from one lake to another. You can have a virtual layer that queries on the fly.
- No new Graph databases: No need for materializing and storing data in graph format, They can be done on the fly in run time, no need for a new graph database to bring in, and no need to bother with integration, cost, and security constraints.
- High Performance: Also achieve all the performance benefits that graph queries have on relational data.
Industry is keeping up fast with this new approach and there have already been a few players on this front.
Open Source Libraries for Development
Apache Spark GraphX: GraphX is a new component in Spark for graphs and graph-parallel computation which includes a growing collection of graph algorithms and builders to simplify graph analytics tasks.
Apache Flink Gelly: Gelly is Apache Flink’s graph-processing API and library. Flink’s native support for iterations makes it a suitable platform for large-scale graph analytics.
Readily Available Players/Engines for Native Support
PuppyGraph: Using PuppyGraph, you can now graph query your existing data in warehouses, lakes, and lake houses in any of the following open table formats with a seamless no-ETL integration.
- Apache Iceberg
- Apache Hudi
- Apache Hive
- Delta Lake
And relational data from the below Databases
- MySQL
- PostgreSQL
Timbr.ai: Timbr’s Semantic Graph Platform is a SQL-native knowledge graph that turns your databases into reasoning machines so we can apply optimized graphs like SQL queries on data. It supports full back-end integration to any relational database that is SQL / ANSI SQL compliant or can be queried in SQL. The connection can be established either by a JDBC or ODBC connector with no ETL.
- Relational databases(MySQL, MariaDb, SqlServer, PostgreSQL, SAP Hana, Aurora Oracle)
- NoSQL databases (MongoDB)
- Datalakes (S3, GCS, Microsoft ADLS)
- Warehouses ( RedShift, BigQuery, Snowflake, Databricks, Synapse, Athena)
- Engines (Apache Spark, Presto, Trino)
- Data formats (Parquet/JSON/CSV)
To summarize, it’s worth exploring these options we have in place to achieve graph analytics without the use of graph databases and materializing graphs. Good luck trying!!
Opinions expressed by DZone contributors are their own.
Comments