What Is Lambda Architecture? Ultimate Guide to Getting Started
Discover the basics of lambda architecture in our comprehensive guide. Explore its components, workflow, applications, and best practices.
Join the DZone community and get the full member experience.
Join For FreeThe volume of data generated today is immense, coming from sources like the Internet of Things (IoT), social media, app metrics, and device analytics. The challenge for data engineering is processing and analyzing this vast amount of information in real time. This raises a crucial question: Are our current data systems capable of meeting this demand?
How Does Lambda Architecture Work?
Lambda architecture is a data engineering paradigm — a way of structuring a data system to overcome the latency problem and the accuracy problem. It was first introduced by Nathan Marz and James Warren in 2015. Lambda architecture structures the system into three layers: a batch layer, a speed layer, and a serving layer, which can be found in the figure below.
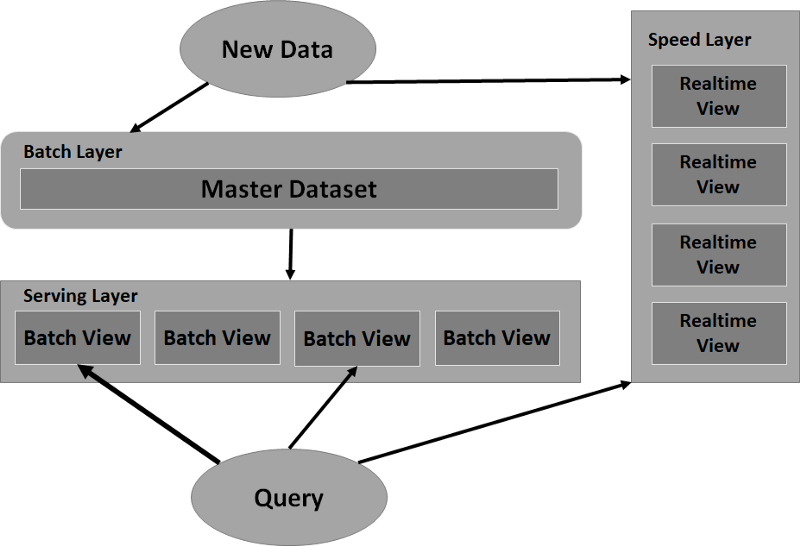
Lambda architecture is horizontally scalable. This means that if your data set becomes too large or the data views you need are too numerous, all you need to do is add more machines. It also confines the most complex part of the system in the speed layer, where the outputs are temporary and can be discarded (every few hours) if ever there is a need for refinement or correction.
The Three Layers of Lambda Architecture Explained
An elderly man living alone in a large mansion decides to set all his clocks to match the correct time on his kitchen clock, 9:04 AM. Due to his slow pace, by the time he reaches the last clock at 9:51 AM, he still sets it to 9:04 AM, making all his clocks incorrect. This is the problem we would experience if a data system only had a batch layer. The next day, he uses a stopwatch — his speed layer — to track his progress. Starting at 9:04 AM, he notes the elapsed time from the stopwatch when setting each clock, ensuring the last clock is accurately set to 9:51 AM.
Check Out Free Course to Learn More: "Introduction to Data Engineering"*
*Affiliate link. See Terms of Use.
In this analogy — which, admittedly, is not perfect — the man is the serving layer. He takes the batch view (the paper with “9:04 AM” written on it) around his mansion to answer “What time is it?” But, he also does the additional work of reconciling the batch view with the speed layer to get the most accurate answer possible.
Understanding the Batch Layer
As mentioned above, lambda architecture is made up of three layers. The first layer — the batch layer — stores the entire data set and computes batch views. The stored data set is immutable and append-only. New data is continually streamed in and appended to the data set, but old data will always remain unchanged. The batch layer also computes batch views, which are queries or functions on the entire data set. These views can subsequently be queried for low-latency answers to questions of the entire data set. The drawback, however, is that it takes a lot of time to compute these batch views.
Understanding the Serving Layer
The second layer in lambda architecture is the serving layer. The serving layer loads in the batch views and, much like a traditional database, allows for read-only querying on those batch views, providing low-latency responses. As soon as the batch layer has a new set of batch views ready, the serving layer swaps out the now-obsolete set of batch views for the current set.
Understanding the Speed Layer
The third layer is the speed layer. The data that streams into the batch layer also streams into the speed layer. The difference is that while the batch layer keeps all of the data since the beginning of its time, the speed layer only cares about the data that has arrived since the last set of batch views completed. The speed layer makes up for the high-latency in computing batch views by processing queries on the most recent data that the batch views have yet to take into account.
Advantages of Lambda Architecture
In Marz and Warren’s seminal book explaining lambda architecture, among other topics, they list eight desirable properties within a big data system, describing how lambda architecture satisfies the following requirements:
- Robustness and fault tolerance: Because the batch layer is designed to be append-only, thus containing the entire data set since the beginning of time, the system is human-fault tolerant. If there is any data corruption, all of the data from the point of corruption forward can be deleted and replaced with the correct data. Batch views can be swapped out for completely recomputed ones, and the speed layer can be discarded. In the time it takes to generate a new set of batch views, the entire system can be reset and running again.
- Scalability: Lambda architecture is designed with layers built as distributed systems. By simply adding more machines, end users can easily horizontally scale those systems.
- Generalization: Since lambda architecture is a general paradigm, adopters aren’t locked into a specific way of computing this or that batch view. Batch views and speed layer computations can be designed to meet the specific needs of the data system.
- Extensibility: As new types of data enter the data system, new views will become necessary. Data systems are not locked into certain kinds or a certain number of batch views. New views can be coded and added to the system, with the only constraint being resources, which are easily scalable.
- Ad hoc queries: If necessary, the batch layer can support ad hoc queries that were not available in the batch views. Assuming the high-latency for these ad hoc queries is permissible, then the batch layer’s usefulness is not restricted only to the batch views it generates.
- Minimal maintenance: Lambda architecture, in its typical incarnation, uses Apache Hadoop for the batch layer and ElephantDB for the serving layer. Both are fairly simple to maintain.
- Debuggability: The inputs to the batch layer’s computation of batch views are always the same: the entire data set. In contrast to debugging views computed on a snapshot of a stream of data, the inputs and outputs for each layer in lambda architecture are not moving targets, vastly simplifying the debugging of computations and queries.
- Low latency reads and updates: In lambda architecture, the last property of a big data system is fulfilled by the speed layer, which offers real-time queries of the latest data set.
Challenges of Lambda Architecture and Key Considerations
While the advantages of lambda architecture seem numerous and straightforward, there are some disadvantages to keep in mind. First and foremost, cost will become a consideration. While how to scale is not very complex — just add more machines — we can see that the batch layer will necessarily need to expand and grow over time. Since all data is append-only and no data in the batch layer is discarded, the cost of scaling will necessarily grow with time.
Others have noted the challenge of maintaining two separate sets of code to compute views for the batch layer and the speed layer. Both layers operate on the same set—or, in the case of the speed layer, subset—of data, and the questions asked of both layers are similar. However, because the two layers are built on completely different systems (for example, Hadoop or Snowflake for the batch layer, but Storm or Spark for the speed layer), code maintenance for two separate systems can be complicated.
Stream Processing and Lambda Architecture Challenges
We noted above that “the speed layer only cares about the data that has arrived since the completion of the last set of batch views.” While this is true, it’s important to make a clarification that small subset of data is not stored; it is processed immediately as it streams in, and then it is discarded. The speed layer is also referred to as the “stream-processing layer.” Remember that the goal of the speed layer is to provide low-latency, real-time views of the most recent data, the data that the batch views have yet to take into account.
On this point, the original authors of the lambda architecture refer to “eventual accuracy,” noting that the batch layer strives for exact computation while the speed layer strives for approximate computation. The approximate computation of the speed layer will eventually be replaced by the next set of batch views, moving the system towards “eventual accuracy.”
Processing the stream in real time in order to produce views that are constantly updated as new data streams in milliseconds is an incredibly complex task. Partnering a document-based database with an indexing and querying system is often recommended in these cases.
Differences Between Lambda Architecture and Kappa Architecture
We noted above that a considerable disadvantage of lambda architecture is maintaining two separate codebases to handle similar processing since the batch layer and the speed layer are different distributed systems. Kappa architecture seeks to address this concern by removing the batch layer altogether.
Instead, both the real-time views computed from recent data and the batch views computed from all data are performed within a single stream processing layer. The entire data set — the append-only log of immutable data — streams through the system quickly in order to produce the views with the exact computations. Meanwhile, the original “speed layer” tasks from lambda architecture are retained in kappa architecture, still providing the low-latency views with approximate computations.
This difference in kappa architecture allows for the maintenance of a single system for generating views, which simplifies the system’s codebase considerably.
Lambda Architecture via Containers on Heroku
Coordinating and deploying the various tools needed to support a lambda architecture — especially when you’re in the starting up and experimenting stage — is accomplished easily with Docker.
Heroku serves well as a container-based cloud platform-as-a-service (PaaS), allowing you to deploy and scale your applications with ease. For the batch layer, you would likely deploy a Docker container for Apache Hadoop. As the speed layer, you might consider deploying Apache Storm or Apache Spark. Lastly, for the serving layer, you could deploy Docker containers for Apache Cassandra or MongoDB, coupled with indexing and querying by Elasticsearch.
Use Cases and Applications
Lambda architecture benefits a wide variety of data-driven fields. Two examples include improving machine learning and managing the data streams from IoT.
Lambda Architecture in Machine Learning
In the field of machine learning, there’s no doubt that more data is better. For machine learning to apply algorithms or detect patterns, however, it needs to receive its data in a way that makes sense. Rather than receiving data from different directions without any semblance of structure, machine learning can benefit by processing data through a lambda architecture data system first. From there, machine learning algorithms can ask questions and begin to make sense of the data that enters the system.
Lambda Architecture for IoT
While machine learning might be on the output side of a lambda architecture, IoT might very well be on the input side of the data system. Imagine a city of millions of automobiles, each one equipped with sensors to send data on weather, air quality, traffic, location information, driving habits, and so on. This is the massive stream of data that would be fed into the batch layer and speed layer of a lambda architecture. Therefore, IoT devices are a perfect example of providing the data within lambda architectures.
Conclusion
Taking on the task of big data is not for the faint of heart. Scaling and system robustness are huge challenges, so paradigms like lambda architecture bring excellent guidance. As massive amounts of data stream into the data system, the batch layer provides high-latency accuracy, while the speed layer provides a low-latency approximation. Meanwhile, the speed layer responds to queries by reconciling these two views to provide the best possible response. Implementing a lambda architecture data system is not trivial. While perhaps complex and initially intimidating, the tools are available and ready to be deployed.
For additional reading, check out:
Opinions expressed by DZone contributors are their own.
Comments