Learn to Access Java Database With Jakarta Data
In this article, we discuss the existing standards for databases in the Java world and the new Jakarta Data, which aims to make life easier for developers.
Join the DZone community and get the full member experience.
Join For FreeDealing with a database is one of the biggest challenges within a software architecture. In addition to choosing one of several options on the market, it is necessary to consider the persistence integrations. The purpose of this article is to show some of these patterns and learn about a new specification proposal, Jakarta Data, which aims to make life easier for developers with Java.
Understanding the Layers That Can Make Up Software
Whenever we talk about complexity in a corporate system, we focus on the ancient Roman military strategy: divide and conquer or divide et impera. To simplify the whole, we break it down into small units.
In the software world, one of the ways to simplify and break down complexity is through layers, whether physical or logical. These layers, mainly the logic ones, can be fragmented, becoming components and functionalities.
This breaking layer movement is one of the themes in the book "Clean Architecture" when mentioning, for example, the strategy of separating the business code from the infrastructure code.
The Three Types of Layers in an Application
According to the "Learning Domain-Driven Design" book, regardless of the architectural style that you are working with, such as monolith or microservices, there is a minimum number of three types of layers in an application. They are the:
- Presentation layer: It is the layer of interaction with the user consuming this resource, whether an end-user or someone who works in software engineering.
- Business logic layer: As its name suggests, this is where the business logic will be, or in the words of Eric Evans, "it is the layer that finds the heart of the business."
- Data access layer: This layer holds the entire persistence mechanism. In the context of Stateless architecture, we can think that it is the place with some state guarantee, noting that the storage mechanism is transparent, be it a NoSQL database, SQL, a Rest API, etc.
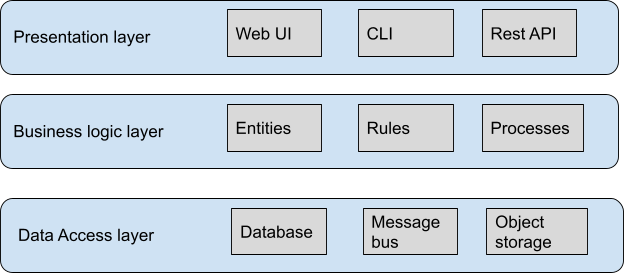
These three types of layers tend to be present in various software architecture styles, from simple ones, such as MVC, to more complex ones, such as CQRS, hexagonal model, onion, among others.
In addition to the three types of layers, the architectural models are very concerned with the communication between these components to ensure high cohesion and low coupling, and they follow the Dependency Inversion Principle, the DIP.
This isolation of the data access layer mainly ensures that the database paradigm "leaks" into the business model. We know a big difference — also known as impedance — especially between relational databases and object-oriented programming.
Persistence Layer
After the proper introduction about layers and their importance, we will focus on the persistence layer or database. A point of criticism and admiration within the object-oriented paradigm is a wide range of options and standards for communication.
For this article, we will talk about some patterns taking into account the single responsibility principle and the coupling with the business and database layer.
It is worth noting that there is no "silver bullet" solution, so it is essential to pay attention to which context this pattern will be used.
Pattern Types When It Comes to Database
Of course, we have several integration models and patterns between the database and OOP. This article focuses on the following:
- Pattern 1: Data-oriented programming
- Pattern 2: Active record
- Pattern 3: Mapper
Next, let's look at these patterns in detail.
Pattern 1: Data-Oriented Programming
In his book "Data-Oriented Programming", author Yehonathan Sharvit proposes reducing complexity by promoting and treating data as a "first-class citizen."
This pattern summarizes three principles:
- The code is data separated.
- Data is immutable.
- Data has flexible access.
This proposal eliminates the entity layer, focusing explicitly on data dictionaries through, for example, an implementation of Map.
Pattern 2: Active Record
After Martin Follower's book "Patterns of Enterprise Application Architecture," this pattern became quite popular.
In short, the pattern has a single object, which is responsible for both the data and the behavior. It allows simplifying business rules since the idea is that there is direct access to data.
However, in the case of more complex architectures, active record tends to become quite challenging to deal with. We add a high coupling between the database solution, not to mention the break of single responsibility. In addition to being responsible for business rules, the same class is also responsible for database operations.
The most recent and widely used solution is Quarkus's Panache within the Java world. This way, it is possible to make an application with microservices with only two classes.
@Entity
public class Person extends PanacheEntity {
public String name;
public LocalDate birth;
public Status status;
}
Person person =...;
// persist it
person.persist();
ist<Person> people = Person.listAll();
// finding a specific person by ID
person = Person.findById(personId);
Pattern 3: Mapper
Another database communication solution that meets the previous premise is mapper. Generally speaking, it leaves entity and database operations separate. What, at most, tends to appear within classes is the metadata or annotations of the Java world.
This standard ensures greater separation between the business layer and the database, and it guarantees the single-responsibility principle. We simplify maintenance and reading in applications, as we have a class for the entity and another for database operations.
However, for simple projects, Mapper tends to be unfeasible. It is the case, for example, of straightforward applications with CRUD that, depending on the style, will need three or four classes to achieve the same objective, unlike standards such as active record, which would perform this function with half the number of objects.
The most common example, of course, is the ORM Hibernate. However, this type of solution is not exclusive to relational databases, as there are solutions for NoSQL such as Spring Data and Jakarta NoSQL.
@Entity
public class Person {
@Id
String name;
@Column
LocalDate birth;
@Column
Status status;
}
Person person =...;
template.insert(person);
List<Person> people = template.query("select * from Person");
// finding a specific person by ID
person = template.find(Person.class, personId);
DAO vs. Repository
From a mapper, it is possible to think of two more patterns. They are:
- DAO (Data Access Object)
- Repository
These patterns consider the decoupling between the model and the persistence layer, but the similarity ends there.
The differences are in the coupling as it is linked to the data access layer, and not to the model, in addition to the focus on the service layers, semantics, and nomenclature. Let's better understand these models separately.
Data Access Object (DAO)
The data access object (DAO) standard isolates the application and business layers from persistence through an abstraction API. This API, in turn, bears a close resemblance to the database engine.
Person person =...;
personDAO.insert(person);
// finding a specific person by ID
person = personDAO.read(id);
Repository
The repository pattern is a mechanism that allows you to encapsulate storage, retrieval, and search behavior by emulating a collection of objects. In this way, the design further hides the relationship of the persistence mechanism.
This pattern focuses on the closest proximity of entities and hides where the data comes from, making it possible for a Repository to use a DAO pattern itself.
Summarizing DAO x Repository
The important point is the semantics. Let's take an example: consider that a Car entity would have Garage as a class, representing the collection of entities. The result would be the following code snippet:
Car car =...;
garage.save(car);
// finding a specific car by ID
car = garage.get(id);
In short, if we compare the two types of pattern inside mapper:
- DAO focuses on an abstraction for accessing some kind of data.
- The repository focuses on a collection, regardless of the object's origin. For this reason, a repository can use a DAO to achieve its goal.
A New API Proposal for Data Access Is Born: Jakarta Data
After knowing all the patterns, and their respective importance and trade-offs, it is essential to take one more step: to see an API that better explores these patterns and, thus, facilitates the adoption of good practices with Java and data resources.
The proposal for a new specification called Jakarta Data is born. Jakarta Data is premised on three principles:
- An easy and declarative API
- A cohesion in this layer
- A decoupling of the other layers
Still, in its first version, the focus of this new proposal is on delivering the repository pattern so that, with just one interface and a few annotations, it is possible to implement Jakarta Data, initially, in three projects:
Relational with JPA, NoSQL with Jakarta NoSQL, and REST with REST Client for MicroProfile.
@Entity
public class Person {
@Id
String name;
@Column
LocalDate birth;
@Column
Status status;
}
public interface PersonRepository extends Repository<Person, String> {
}
Person person =...;
repository.save(person);
Optional<Person> person = repository.findById(id);
repository.deleteById(id);
In summary, from Jakarta Data, it is easier to deal with the business layer both in terms of polyglot persistence and its decoupling.
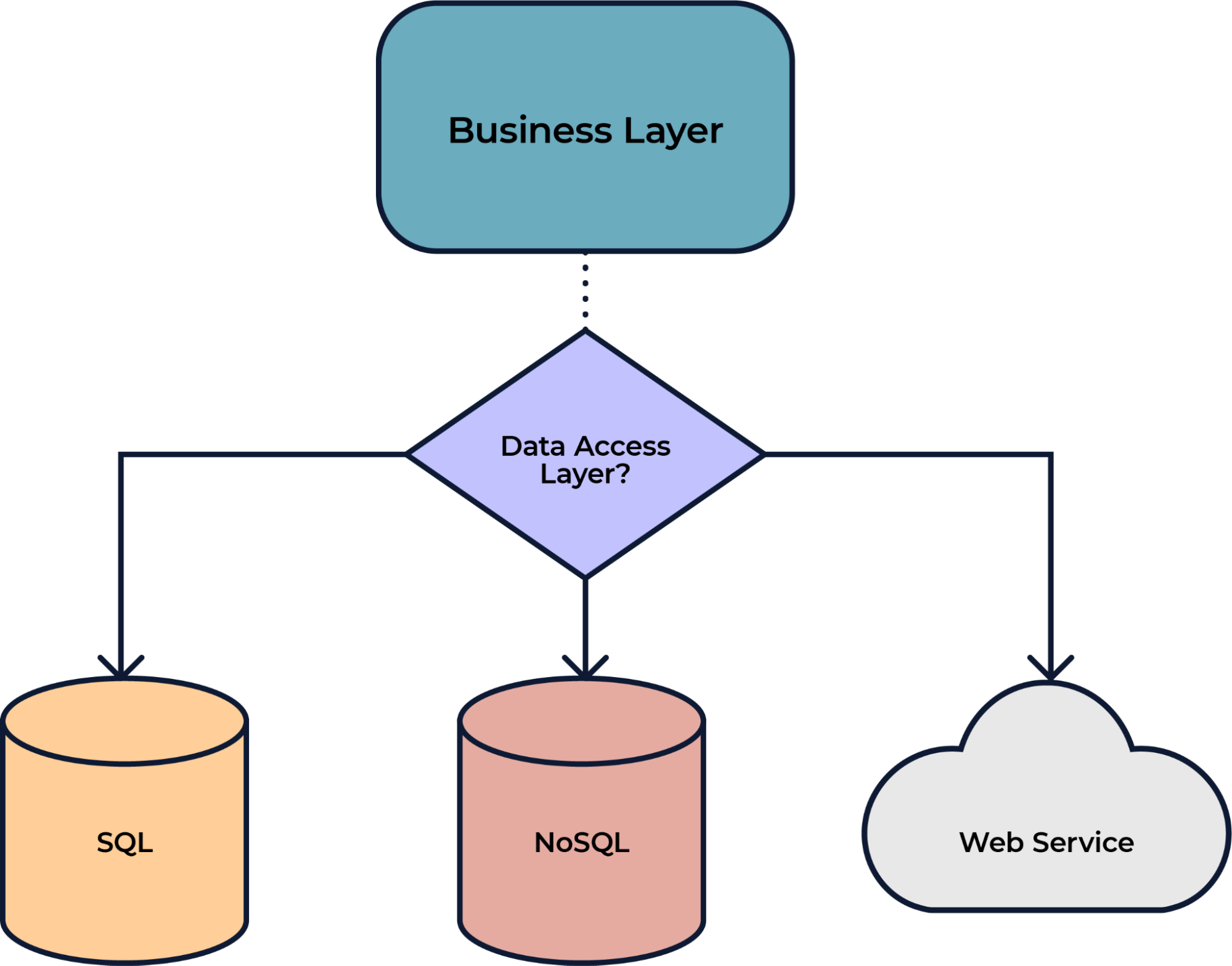
Jakarta Data: More Ease and Integration
Overall, we always take into account the degree of insulation of the other layers and their ease of use and maintenance. From this scenario, Jakarta Data was born, whose objective is to help use these patterns in a simple and integrated way to the world of Java specification. And, by default, the expectation is full support from the community and providing help and feedback.
Opinions expressed by DZone contributors are their own.
Comments