LLM-Powered Deep Parsing for Industrial Inventory Search
LLM-powered deep parsing converts messy industrial inventory data into structured, searchable data, enabling precise searches and scalable deduplication.
Join the DZone community and get the full member experience.
Join For FreeIndustrial ERPs often look structured on the surface: item IDs, purchase orders, stock levels. But in many companies, they are overloaded with unintentional duplicates because the most important information is buried inside an unstructured description field.
In heavy industry, descriptions are entered manually with little guidance or validation, so the same part shows up many times under different names. A single component might live three separate lives in the system:
- “Bosch Pump”
- “Pump, Bosch, 1500w”
- “Pmp Bsch hydraulic”
A domain expert would usually conclude that, with very high probability, these items refer to the same piece of equipment. To an ERP, these items are three different products. Multiply this by millions of line items, multiple sites, multiple languages, and years of legacy records, and you get a familiar outcome: data exists, but it is often too inconsistent to use efficiently.
In practice, this impacts two workflows that most teams care about:
- Search: Teams can’t reliably find what is already in storage, especially when they don’t know the exact naming used in the ERP.
- Deduplication: Procurement keeps purchasing “new” parts that already exist, and dead stock accumulates over time.
A common goal is to make descriptions usable for downstream automation by extracting a homogeneous, decision-ready structure from raw text. This is where LLM-powered deep parsing can be useful. LangChain is a practical framework for implementing this as a repeatable, testable pipeline rather than a collection of ad-hoc prompts.
Traditional Approaches and Where They Tend to Break
Full String Matching
Works when descriptions are clean and strictly validated. In real operations, that level of discipline is not common, so full matching is usually a starting point rather than a long-term solution.
Rules and Regex
Safe, deterministic, explainable. Also fragile. Descriptions differ by plant, vendor, technician, language, and era. As the scope expands to new item categories, maintaining rules often becomes a major effort, and coverage gaps show up quickly.
Approximate String Matching
Useful for typos. Less useful for meaning. It won’t reliably capture that “hydraulic” and “liquid pressure” are related contexts, and it often struggles with short abbreviations that carry important signals. Selecting and tuning fuzzy matching across many categories is usually a constant trade-off.
Semantic Search
Semantic search converts a query and each item into embeddings and retrieves nearest neighbors by vector distance in a similar way to how distance is calculated between two locations on a map. This is helpful in messy industrial text because it improves recall even when wording differs.
But industrial data is a place where small textual differences can imply big functional differences. A wrench 11mm and a wrench 21mm may sit close in semantic space because they share most context (“wrench”, tool category, usage), yet they are not interchangeable. For this reason, semantic search alone is usually not sufficient for reliable deduplication or for a strict “find exact part” search. It can help find candidates, but you typically still need a precision layer based on extracted attributes.
What Deep Parsing Changes in Practice
Efficient industrial search is not only about typos and semantics. Most of the time, it requires extracting the characteristics that drive interchangeability:
- Manufacturer/brand
- Category (bolt, bearing, motor, pump)
- Key specs (dimensions, voltage, pressure, thread type, strength class)
- Normalized units
- Standards and constraints relevant to the business
LLMs can help because they can follow high-level instructions like “extract manufacturer and relevant specs” while handling inconsistent phrasing, abbreviations, and word order. The catch is that LLMs are not “born” with your domain knowledge. They may not know internal abbreviations, preferred naming conventions, or which standard matters for a specific category. Fine-tuning a large model is often infeasible, and frequently not the most cost-effective path. A practical approach is to provide domain context at runtime (RAG) and enforce structured outputs with validation.
Parsing and Processing Pipeline
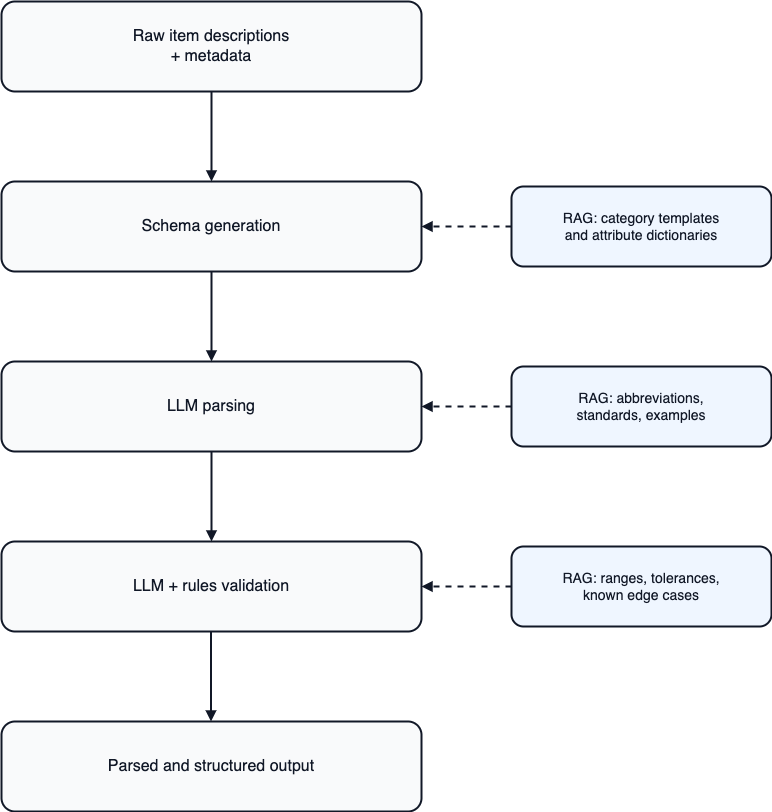
Raw Item Descriptions + Metadata
Input is usually not just a free-text description. Metadata often matters for correct interpretation and downstream decisions:
- Item category (if available)
- Vendor or manufacturer field (often partially filled)
- Unit of measure, procurement group, material group
This metadata is not always reliable, but even imperfect signals can help with routing and validation.
Schema Generation
Industrial catalogs are not one schema. A bolt, a bearing, and an electric motor have different attributes. Trying to force everything into one universal schema typically produces either a huge, sparse structure or a generic output that is not very usable.
A practical alternative is to generate a category-aware schema:
- Choose or infer the category (via metadata or a lightweight LLM classification)
- Let the LLM generate a category-specific template, what fields matter for this category. RAG can help here with instructions and guidelines that will make this crucial part more specific.
- Add attribute dictionaries via RAG (allowed values, synonyms, common aliases, unit conventions)
At this point, your output is a Pydantic schema that was generated by LLM with the help of internal company knowledge.
LLM Parsing
Once it is known what needs to be extracted, the parsing step focuses on turning raw text into a typed record, keeping the output consistent across items in the same category thanks to schemes generated earlier.
Two practical points tend to matter:
- Abbreviations and internal naming conventions are often the hardest part of the description. RAG can help to ease the pain here
- Standards and additional instructions help the model disambiguate what a term means in context
The output should be structured and typed (numbers as numbers, units normalized, enums constrained), not a free-form explanation. For example, LangChain handles that via structured output internally.
Validation
Parsing alone is not enough for operational use. You usually need validation and a decision layer, especially if the output drives deduplication. In many deployments, the match decision is not “LLM decides duplicates.” It is “LLM extracts structure, rules decide,” with an optional LLM contribution for borderline cases or for generating human-readable rationales for review queues.
Parsed output
The final output is a normalized JSON-like record you can store alongside the original description. It can also include confidence indicators and validation flags.
This parsed layer becomes useful across multiple workflows:
- Structured filters and faceted search (category, manufacturer, normalized specs)
- Better deduplication at ingestion time (flag likely duplicates before creating a new item)
- Reporting and governance (how much of the catalog has missing critical attributes)
- Downstream inventory optimization, where “same part” needs to be defined consistently
Common Failure Points
Hallucinations
LLMs can invent values, especially when inputs are thin or ambiguous. In practice, this is usually handled by enforcing strict schemas, grounding the model with retrieved domain context, running deterministic validators for units and plausible ranges, and routing low-confidence outputs to human review instead of letting the pipeline silently guess.
Data Quality Threshold
If the description is something like “Bearing 10”, there may not be enough signal to extract a meaningful structure. The practical approach here is to treat deep parsing as decision support rather than a guaranteed reconstruction of missing data. It helps to store uncertainty explicitly (for example, leaving required fields empty with a reason) and route such items into enrichment workflows using supplier documentation, historical purchase orders, or technician prompts.
Summary
For industrial inventory, deep parsing is most effective when treated as a structured extraction pipeline: raw descriptions and metadata are converted into a category-aware schema, parsed by an LLM, validated with rules, and written out as normalized structured data. RAG supports each stage with the right knowledge (templates and dictionaries for schema generation, abbreviations and standards for parsing, tolerances and edge cases for validation).
LangChain is a practical way to orchestrate this end-to-end with enforced output contracts, retrieval where it matters, and enough testing and tracing to operate it in production, resulting in a structured layer that typically improves search and enables scalable deduplication without an ERP rewrite.
Opinions expressed by DZone contributors are their own.
Comments