A Framework for Building Semantic Search Applications With Generative AI
This article explores a framework for building semantic search applications with generative AI, enabling developers with a unified scalable framework.
Join the DZone community and get the full member experience.
Join For FreeSearch applications play a critical role in this digital era. It enables enterprises to find the right and valuable information at the right time to make informed decisions. The efficient search application proves to improve productivity and efficiency for organizations to thrive. The traditional keyword search applications fail to understand the meaning, intent, and context of users or customers, They don't have the power to understand the nuances of human language. They are heavily built on keyword matching, which may lead to inaccurate results in understanding the intent behind the search. The developers and architects are facing challenges in building search applications that go beyond mere keyword matching.
Now it has been made it easier and more powerful to reimagine searches by leveraging cutting-edge technologies like natural language processing (NLP), machine learning (ML), and models. These advanced techniques can unlock the ability to truly understand the meaning and context of user queries which leads to more accurate and personalized results.
Why Semantic Search?
Semantic search uses natural language processing (NLP) to understand the intent of the search being made. With the rise of LLM, generative AI/LLM solutions can be combined with semantic search to capture the full essence of a customer query to provide personalized, accurate, and contextual search results. In this article, we will explore a framework for building semantic search applications with generative AI. This framework will enable developers, cloud architects, and cloud leaders with a unified scalable framework for building semantic search applications.
Below are possible types of semantic search solutions that can be built with Generative AI solutions across various industries. For example:
- Personalized recommendation: The search solution can provide products/movies based on user behavior, choices, and earlier search history.
- Knowledge management/discovery: It can be used to create searchable content of documents, which results in quick access and discovery.
- Image search: The search application can search based on the image queries, which will provide similar images or provide the text results/summary for the given image.
- Voice search/recommendations: With the integration of voice recognition libraries, the system can provide recommendations based on voice commands or queries.
- Multimodal search: This enables the combined search of text, image, and video together as input to provide summarized results.
Let's take a look at the framework approach of building semantic search applications with Generative AI.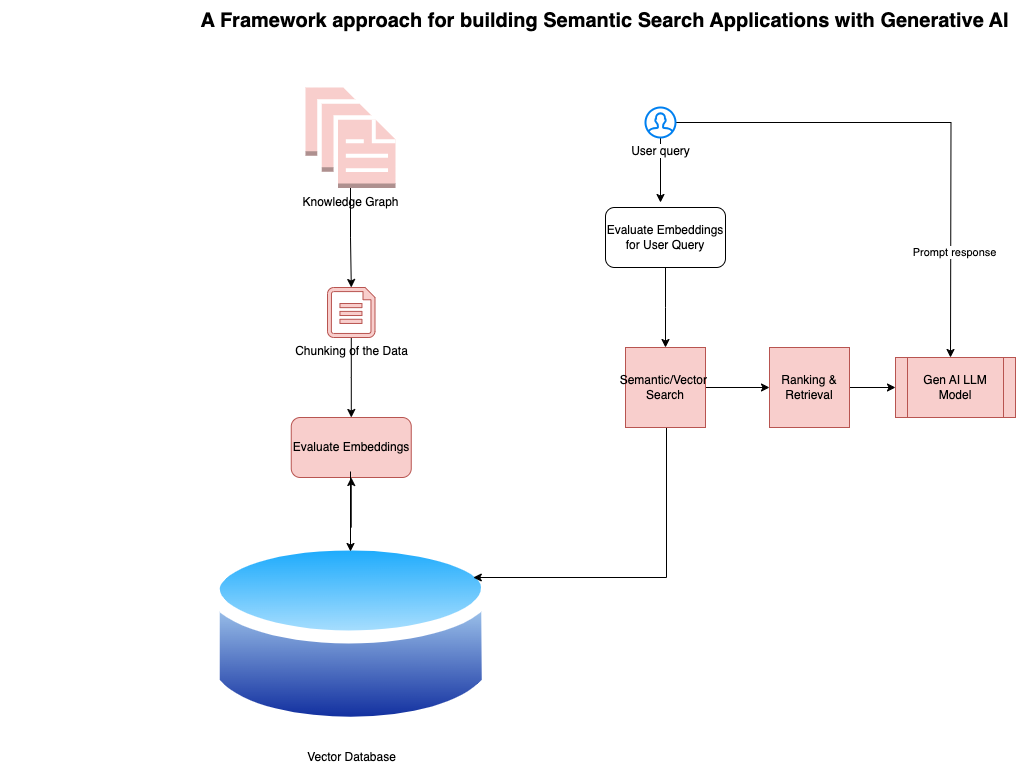
Figure 1: Framework for semantic search applications with Gen AI
Let's look at the framework components below.
1. Knowledge Graph
This is the source data used for semantic search. This can be documents or knowledge graph databases. In this step, we need to ingest data from various sources (documents, databases, APIs, etc.) and preprocess the data by cleaning, normalizing, and removing the duplicates.
2. Chunking of Knowledge Data
In this step, data is chunked if needed. The chunking of data helps improve computational speed to calculate the embeddings of the data, improves memory utilization, and provides accurate search results. It retains the semantic richness of the information which enables more contextual search results. The chunked data can optimize the embedding evaluation process, leading to more accurate representations and improved search capabilities in your application.
| S.No | Langchain |
| 1 | CharaterTextSplitter |
| 2. | RecursiveCharacterTextSplitter |
Here is the sample code to split the knowledge graph documents into chunks with Python:
def get_split_knowledgegraphdocuments(index_path: str) -> List[str]:
"""
This function is used to chunk documents
Args:
index_path: Path of the dataset folder containing the documents.
Returns:
List of chunked, or split documents.
"""
split_kdocs = []
for f_name in os.listdir(index_path):
print(f" your file_name : {file_name}")
if fname.endswith(".pdf"):
loader = UnstructuredPDFLoader(index_path + f_name)
else:
loader = TextLoader(index_path + f_name)
text_splitter = CharacterTextSplitter(chunk_size=8192, chunk_overlap=128)
split_docs.extend(text_splitter.split_documents(loader.load()))
return split_kdocs
3. Evaluate the Embedding
An embedding is a technique to represent data points as vectors in a lower-dimensional space. In the real world, most of our text, image, or video data are very high dimensional in nature. This essentially translates complex data, like text or images, into a format that machines can understand and manipulate more easily. Embeddings are a powerful tool for bridging the gap between complex real-world data representation and ML algorithms. This transformational representation helps with building effective and intelligent applications. In this step, evaluate the embedding of the source data with the help of embedding APIs available in the cloud market.
| S.No | Google Cloud | Azure | AWS | Open Source |
| 1 | Vertex AI Embeddings | Azure Open AI embeddings | Amazon Titan Multi-modal embedding model |
E5-Mistral-7B-instruct |
4. Vector Databases
Vector databases are a valuable tool for unlocking the power of unstructured and semi-structured data. By representing information as vectors and enabling similarity search, they pave the way for applications like semantic search, recommendation systems, and advanced NLP tasks. Vector databases are optimized for unstructured and semi-structured data, enabling searches based on semantic similarity.
| S.No | Google Cloud | Azure | AWS | Open Source |
| 1 | Vertex AI Vector Search | Azure AI Search | Amazon Kendra | PineCone |
Here is the sample code to generate embedding and store it in a vector database with the Google Cloud VertexAI platform.
# Create VertexAI Embeddings objects for the knowledge graph
EMBEDDING_NUM = 5
vembeddings = VertexAIEmbeddings(
model_name=EMBEDDING_MODEL, batch_size=EMBEDDING_NUM)
split_kdocs = get_split_documents(PATH)
db = Chroma.from_documents(
documents=split_kdocs, embedding=vembeddings, persist_directory=PERSIST_PATH
)
db.persist()
5. Semantic/Vector Search
The semantic/vector search algorithm calculates the search results from the embeddings stored in a vector database for a given user query. The similarity scores between query embeddings and document embeddings are calculated here. The output of this results in semantic search systems that can rank and present relevant results to the user.
6. Ranking and Results
The relevant scoring and ranking are performed, which evaluates the semantic similarity between the query and the retrieved information from the vector database, which considers factors such as context, entities, relationships, and overall query topic relevance.
Then the generated responses or summaries are then ranked based on their relevance scores and the most relevant results will appear at the top. The ranking algorithm produces results that consider user choices, personalization, and history.
7. Generative AI Model Output
Generative AI models are a critical component in semantic search applications to ensure a more natural and intuitive interaction between customers and the knowledge retrieval system. These models leverage their natural language understanding capabilities to interpret user queries accurately, match them semantically with relevant data in the knowledge graph or repository, and generate human-like responses or summaries or translate the search results depending on the user preference. You can use the multimodal capabilities of the foundation model to provide more interactive search, audio, video, and voice search, personalized recommendations, and summary. There is a possibility of fine-tuning the Generative AI model to suit your needs as well.
| S.No | Google Cloud | Azure | AWS | Open Source |
| 1. | Gemini Flash 1.5 | Azure Open AI | Amazon Bedrock | Llama |
Conclusion
The combination of Generative AI and semantic search opens up a world of possibilities across various industries such as healthcare, E-commerce, finance/banking, and manufacturing for finding relevant information, personalized recommendations, effective summarization multi-language translation, and knowledge discovery.
Opinions expressed by DZone contributors are their own.
Comments