LLMs for Debugging Code
Learn how LLMs can analyze code, assist in debugging workflows, and where their current limitations open space for future innovation.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) are transforming software development lifecycles, with their utility in code understanding, code generation, debugging, and many more. This article provides insights into how LLMs can be utilized to debug codebases, detailing their core capabilities, the methodologies used for training, and how the applications might evolve further in the future. Despite the issues with LLMs like hallucinations, the integration of LLMs into development environments through sophisticated, agentic debugging frameworks proves to improve developers’ efficiency.
Introduction
The Evolving Role of LLMs in Coding
LLMs have already proven their capabilities beyond their initial applications in natural language processing to achieve remarkable performance in diverse code-related tasks, including code generation and translation. They power AI coding assistants like GitHub Copilot and Cursor, and have demonstrated near-human-level performance on standard benchmarks such as HumanEval and MBPP.
LLMs can generate comprehensive code snippets from textual descriptions, complete functions, and provide real-time syntax suggestions, thereby streamlining the initial stages of code creation. However, there is a clear expansion use-case into more complex, iterative processes required throughout the software development lifecycle.
The Criticality of Code Debugging
Debugging is a time-consuming yet fundamental part of software development, involving error identification, localization, and repair. These errors range from simple syntax mistakes to complex logical flaws. Traditional debugging methods are often challenging, especially for junior programmers who may struggle with opaque compiler messages and complex codebases. The efficiency of the debugging process directly impacts development timelines and software quality, highlighting the need for more advanced and intuitive tools.
Core Capabilities of LLMs
Code Understanding and Analysis
Beyond the extensive pre-training on vast code corpora to understand natural language, LLMs are trained specifically with large coding databases to recognize common programming patterns and infer the intended meaning of code segments. This foundational capability allows them to analyze code for both syntax errors and logical inconsistencies.
Bug Localization and Identification
A primary application of LLMs in debugging is their capacity to assist in identifying and localizing bugs. Recent advancements in LLM-based debugging have moved beyond just line-level bug identification. More recent approaches can predict bug locations with finer granularity beyond the line level, down to the token level. We can employ various techniques for both bug identification and the bug-fixing process. This is achieved by leveraging encoder LLMs such as CodeT5, which allow for a more precise pinpointing of the problematic code segments.
Code Fixing
LLMs can provide suggestions on how to fix buggy code. More recently, LLM-agents are also able to propose the code changes directly. They may also employ an iterative process of improving and repairing source code.
There's also growing interest in self-repair techniques, where the LLM runs the code it generated, observes the results, and then makes adjustments based on what went wrong. This loop helps improve the reliability and quality of the final code. This self-correcting mechanism mimics aspects of human debugging, where developers test, observe failures, and then modify their code.
For example, how a developer might prompt an LLM for a bug fix:
# User Prompt:
# "The following Python function should calculate the factorial of a number,
# but it's returning an incorrect result for inputs greater than 0.
# Can you identify the bug and fix it?"
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n) # Bug is here - infinite recursion!
# --- LLM's Suggested Fix ---
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)RAG on Code Base and Q&A Forums
LLMs can perform an efficient retrieval-augmented generation (RAG) on the internal code-base and Q&A forums (internal and external) and provide a relevant and concise summary, which can be very helpful in the debugging journey. This can be about understanding a build or a runtime error on local change, questions about design and access patterns, or instantaneously performing RAG to understand and provide an overview and relevant pointers. LLMs can then combine this with their understanding of the code base in order to produce hints for further debugging and possible fixes.
This points to a future where advances in debugging won't just rely on better code-oriented models, but also on creative approaches that connect natural language understanding with code reasoning, enabling LLMs to interpret and solve coding issues in a more conceptual, human-like manner.
Test Case Generation for Debugging
LLMs can provide support for efficient debugging mechanisms through robust test case generation. They can create unit test cases with diverse test inputs, which is fundamental for effectively detecting bugs. Several AI coding tools exemplify this capability, allowing developers to generate well-structured test cases simply by providing natural language prompts.
// User Prompt:
// "Generate a JUnit test case for the following 'Calculator.add' method.
// Include a test for positive numbers, negative numbers, and zero."
class Calculator:
def add(self, a, b):
return a + b
// LLM-Generated Test Case:
import unittest
class TestCalculator(unittest.TestCase):
def test_add_positive_numbers(self):
calculator = Calculator()
self.assertEqual(5, calculator.add(2, 3), "Adding two positive numbers")
def test_add_negative_numbers(self):
calculator = Calculator()
self.assertEqual(-5, calculator.add(-2, -3), "Adding two negative numbers")
def test_add_with_zero(self):
calculator = Calculator()
self.assertEqual(2, calculator.add(2, 0), "Adding a number to zero")
if __name__ == '__main__':
unittest.main()
Approaches to Build Debug-Capabilities
Data Refinement and Supervised Fine-Tuning
It is a very important step to perform domain-specific training on high-quality debugging datasets in the required languages to enhance LLM to help with effective debugging and produce optimal performance.
Supervised fine-tuning (SFT) needs to be run on public and internal code bases to understand the design, build, and testing patterns. Research indicates that larger LLMs, particularly those exceeding 70 billion parameters, show extraordinary debugging abilities and superior bug-fixing accuracy in contrast to smaller models (e.g., 7B-scale models).
Natural Language as an Intermediate Representation (NL-DEBUGGING)
The NL-DEBUGGING framework represents a significant advancement by introducing natural language as an intermediate representation for code debugging. This approach involves translating code into natural language understanding to facilitate a deeper level of semantic reasoning and guide the debugging process. This enables LLMs to come up with diverse strategies and solutions for debugging. Popular natural-language representations include sketches, pseudocodes, and key thought points.
Advanced Prompt Engineering Strategies
The design of prompts is a critical factor in effectively adapting LLMs for bug-fixing tasks. Providing comprehensive context, such as the original source code, significantly improves the quality and relevance of error explanations generated by LLMs.
Various prompt engineering strategies can be employed to optimize performance, including one-shot prompting, assigning specific roles to the LLM (e.g., instructing it to "Act like a very senior Python developer"), and decomposing complex tasks into smaller, manageable sub-tasks. It may also be effective to do negative prompting, which explicitly states what the desired output should not contain.
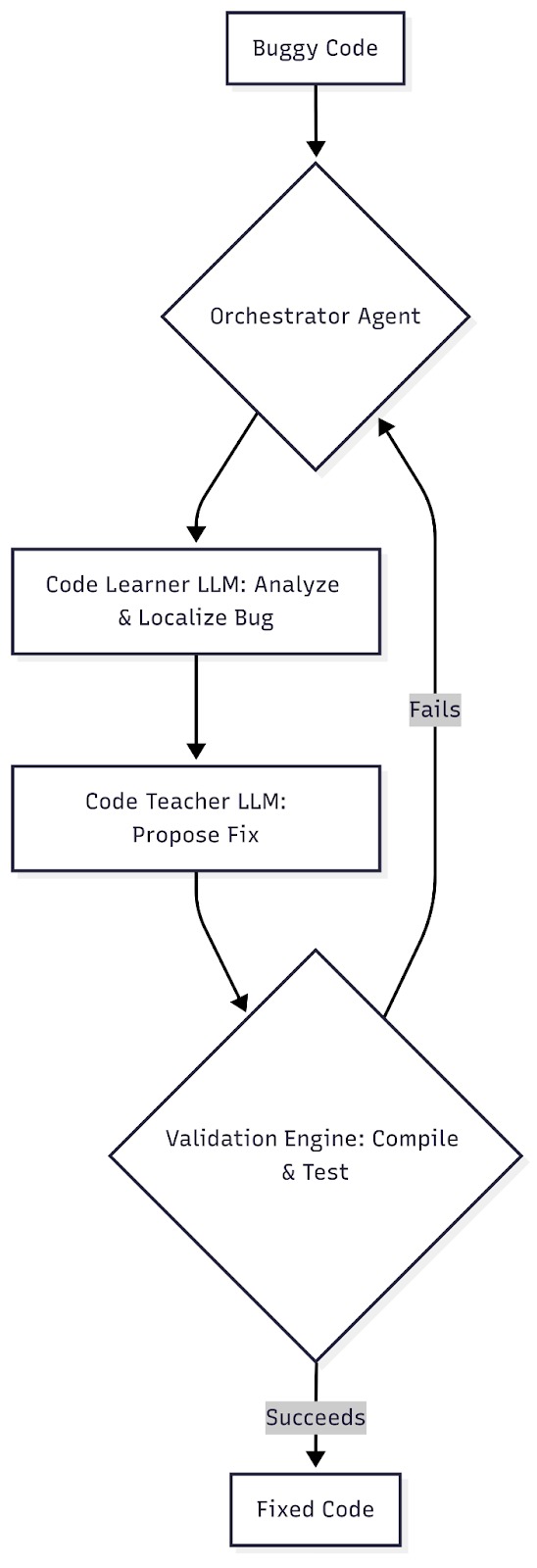
Multi-LLM and Agentic Debugging Flow
To overcome the inherent limitations of single LLMs and move beyond the simplistic "prompt in, code out" model that often falls short for complex debugging scenarios, researchers are developing multi-LLM and agentic debugging frameworks. Different LLMs have distinct roles, such as a "Code Learner" and a "Code Teacher," which integrate compiler feedback to improve the accuracy of bug identification and the fix.
For example, using Claude for code retrieval, and GPT-4 for deep analysis. In addition, iterative refinement may be employed where LLMs are designed to correct or debug their own outputs.
Limitations and Challenges
Shallow Code Understanding and Semantic Sensitivity
One of the key limitations of today’s large language models in debugging is that they often lack a deep understanding of how code actually works. Their comprehension relies heavily on lexical and syntactic features, rather than a semantic understanding of program logic.
Studies show that LLMs can lose the ability to debug the same bug in a substantial percentage of faulty programs (e.g., 78%) when small non-semantic changes (removal of dead-code, comments/variable naming update, etc.) are applied. LLMs may also struggle to discard irrelevant information, treating dead code as if it actively contributes to the program's semantics, which can lead to misdiagnosis during fault localization.
Performance on Complex and Logical Errors
While LLMs demonstrate promise, their overall debugging performance still falls short of human capabilities. Analysis shows that certain categories of errors still remain significantly challenging for LLMs - specifically, logical errors and bugs involving multiple intertwined issues are considerably more difficult for LLMs to understand/debug compared to simpler syntax and reference errors.
Context Window Constraints and Scalability Issues
Modern software repositories are often extensive, spanning thousands to millions of tokens. Effective debugging in such environments requires LLMs to process and understand entire codebases comprehensively. LLMs struggle to maintain reliable performance at extreme context sizes, even though recent advancements have made it possible to pass large contexts. Performance has been observed to degrade as context lengths increase, limiting their ability to fully grasp and debug large, multi-file projects in their entirety.
The Problem of Hallucinations and Inconsistent Output
A critical vulnerability in LLMs is their propensity to generate "hallucinations" — plausible-sounding but factually incorrect or entirely fabricated content. This often means developers need to double-check and sometimes spend extra time debugging the code or fixes suggested by the AI. Hallucinations can stem from various sources, including poorly written prompts, unclear contextual information provided to the model, or the use of outdated model versions.
Test Coverage Issues
While they can produce executable and varied test cases, they often struggle with the more strategic and logical aspect of testing: identifying which specific statements, branches, or execution paths need to be covered. This limitation is very relevant for debugging, as effective debugging often relies on precisely crafted test cases that isolate and expose specific problematic code paths.
The "Debugging Decay" Phenomenon
Research shows that AI debugging effectiveness follows an exponential decay pattern. After a few iterations, an LLM's ability to find bugs drops significantly (by 60-80%), making continuous, unguided iterations computationally expensive and inefficient. This suggests that human intervention is necessary to reset and guide the debugging process rather than relying on prolonged, independent AI iterations.
Conclusion
LLMs are set to revolutionize code debugging by enhancing efficiency and developer productivity. Their ability to understand code, localize bugs, suggest repairs, and generate test cases marks a significant advancement over traditional methods.
The future lies in a collaborative model where AI assists human developers, augmenting their skills rather than replacing them. Through continuous learning, strategic integration, and a focus on human-AI partnership, LLMs will become indispensable tools in the software development lifecycle, transforming debugging into a more proactive and intelligent process.
Opinions expressed by DZone contributors are their own.
Comments