Lock Striping in Java
Take a look at this implementation of lock striping in Java after examining the effects of a sequential bottleneck in concurrent requests.
Join the DZone community and get the full member experience.
Join For FreeThere are dozens of decent lock-free hashtable implementations. Usually, those data structures, instead of using plain locks, are using CAS-based operations to be lock-free. with this narrative, it might sound I’m gonna use this post to build an argument for lock-free data structures. that’s not the case, quite surprisingly. on the contrary, here we’re going to talk about plain old locks.
Now that everybody’s onboard, let’s implement a concurrent version of Map with this simple contract:
public interface ConcurrentMap<K, V> {
boolean put(K key, V value);
V get(K key);
boolean remove(K key);
}
Since this is going to be a thread-safe data structure, we should acquire some locks and subsequently release them while putting, getting, or removing elements:
xxxxxxxxxx
public abstract class AbstractConcurrentMap<K, V> implements ConcurrentMap<K, V> {
// constructor, fields and other methods
protected abstract void acquire(Entry<K, V> entry);
protected abstract void release(Entry<K, V> entry);
}
Also, we should initialize the implementation with a pre-defined number of buckets:
xxxxxxxxxx
public abstract class AbstractConcurrentMap<K, V> implements ConcurrentMap<K, V> {
protected static final int INITIAL_CAPACITY = 100;
protected List<Entry<K, V>>[] table;
protected int size = 0;
public AbstractConcurrentMap() {
table = (List<Entry<K, V>>[]) new List[INITIAL_CAPACITY];
for (var i = 0; i < INITIAL_CAPACITY; i++) {
table[i] = new ArrayList<>();
}
}
// omitted
}
One Size Fits All?
What happens when the number of stored elements are way more than the number of buckets? Even in the presence of the most versatile hash-functions, our hashtable’s performance would degrade significantly. In order to prevent this, we need to add more buckets when needed:
xxxxxxxxxx
protected abstract boolean shouldResize();
protected abstract void resize();
With the help of these abstract template methods, here’s how we can put a new key-value pair into our map:
xxxxxxxxxx
public boolean put(K key, V value) {
if (key == null) return false;
var entry = new Entry<>(key, value);
acquire(entry);
try {
var bucketNumber = findBucket(entry);
var currentPosition = table[bucketNumber].indexOf(entry);
if (currentPosition == -1) {
table[bucketNumber].add(entry);
size++;
} else {
table[bucketNumber].add(currentPosition, entry);
}
} finally {
release(entry);
}
if (shouldResize()) resize();
return true;
}
protected int findBucket(Entry<K, V> entry) {
return abs(entry.hashCode()) % table.length;
}
In order to find a bucket for the new element, we are relying on the hashcode of the key. Also, we should calculate the hashcode module of the number of buckets to prevent being out of bounds!
The remaining parts are pretty straightforward: we’re acquiring a lock for the new entry and only add the entry if it does not exist already. Otherwise, we would update the current entry. At the end of the operation, if we came to this conclusion that we should add more buckets, then we would do so to maintain the hashtable’s balance. The get and remove methods can also be implemented as easily.
Let’s fill the blanks by implementing all those abstract methods!
One Lock to Rule Them All
The simplest way to implement a thread-safe version of this data structure is to use just one lock for all its operations:
xxxxxxxxxx
public final class CoarseGrainedConcurrentMap<K, V> extends AbstractConcurrentMap<K, V> {
private final ReentrantLock lock;
public CoarseGrainedConcurrentMap() {
super();
lock = new ReentrantLock();
}
protected void acquire(Entry<K, V> entry) {
lock.lock();
}
protected void release(Entry<K, V> entry) {
lock.unlock();
}
// omitted
}
The current acquire-and-release implementations are completely independent of the map entry. As promised, we’re using just one ReentrantLock for synchronization. This approach is known as Coarse-Grained Synchronization since we’re using just one lock to enforce exclusive access across the whole hashtable.
Also, we should resize the hashtable to maintain its constant access and modification time. In order to do that, we can incorporate different heuristics. For example, when the average bucket size exceeds a specific number:
xxxxxxxxxx
protected boolean shouldResize() {
return size / table.length >= 5;
}
In order to add more buckets, we should copy the current hashtable and create a new table with, say, twice the size. Then add all entries from the old table to the new one:
xxxxxxxxxx
protected void resize() {
lock.lock();
try {
var oldTable = table;
var doubledCapacity = oldTable.length * 2;
table = (List<Entry<K, V>>[]) new List[doubledCapacity];
for (var i = 0; i < doubledCapacity; i++) {
table[i] = new ArrayList<>();
}
for (var entries : oldTable) {
for (var entry : entries) {
var newBucketNumber = abs(entry.hashCode()) % doubledCapacity;
table[newBucketNumber].add(entry);
}
}
} finally {
lock.unlock();
}
}
Please note that we should acquire and release the same lock for resize operation, too.
Sequential Bottleneck
Suppose there are three concurrent requests for putting something into the first bucket, getting something from the third bucket and removing something from the sixth bucket:
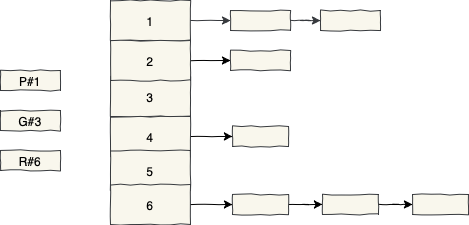
Ideally, we expect from a highly scalable concurrent data structure to serve such requests with as little coordination as possible. However, this is what happens in the real world:
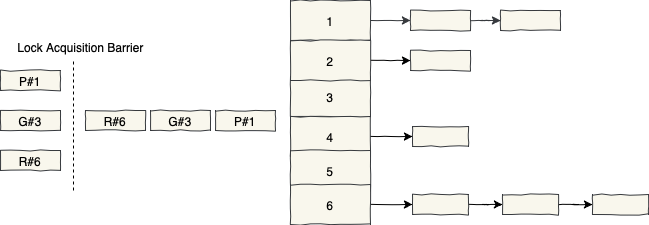
As we’re using only one lock for synchronization, concurrent requests will be blocked behind the first one that acquired the lock. When the first one releases the lock, the second one acquires it and after some time, releases it.
This phenomenon is known as Sequential Bottleneck (Something like Head of Line Blocking) and we should mitigate this effect in concurrent environments.
The United Stripes of Locks
One way to improve our current coarse-grained implementation is to use a collection of locks instead of just one lock. This way each lock would be responsible for synchronizing one or more buckets. This is more of a Finer-Grained Synchronization compared to our current approach:
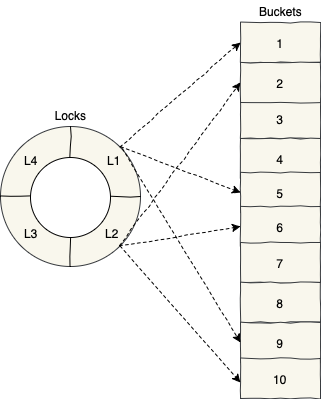
Here we’re dividing the hashtable into a few parts and synchronize each part independently. This way we reduce the contention for each lock and consequently improving the throughput. This idea also is called Lock Striping because we synchronize different parts (i.e. stripes) independently:
xxxxxxxxxx
public final class LockStripedConcurrentMap<K, V> extends AbstractConcurrentMap<K, V> {
private final ReentrantLock[] locks;
public LockStripedConcurrentMap() {
super();
locks = new ReentrantLock[INITIAL_CAPACITY];
for (int i = 0; i < INITIAL_CAPACITY; i++) {
locks[i] = new ReentrantLock();
}
}
// omitted
}
We need a method to find an appropriate lock for each entry (i.e. bucket):
xxxxxxxxxx
private ReentrantLock lockFor(Entry<K, V> entry) {
return locks[abs(entry.hashCode()) % locks.length];
}
Then we can acquire and release a lock for an operation on a particular entry as following:
xxxxxxxxxx
protected void acquire(Entry<K, V> entry) {
lockFor(entry).lock();
}
protected void release(Entry<K, V> entry) {
lockFor(entry).unlock();
}
The resize procedure is almost the same as before. The only difference is that we should acquire all locks before the resize and release all of them after the resize.
We expect the fine-grained approach to outperform the coarse-grained one, let’s measure it!
Moment of Truth
In order to benchmark these two approaches, we’re going to use the following workload on both implementations:
xxxxxxxxxx
final int NUMBER_OF_ITERATIONS = 100;
final List<String> KEYS = IntStream.rangeClosed(1, 100)
.mapToObj(i -> "key" + i).collect(toList());
void workload(ConcurrentMap<String, String> map) {
var requests = new CompletableFuture<?>[NUMBER_OF_ITERATIONS * 3];
for (var i = 0; i < NUMBER_OF_ITERATIONS; i++) {
requests[3 * i] = CompletableFuture.supplyAsync(
() -> map.put(randomKey(), "value")
);
requests[3 * i + 1] = CompletableFuture.supplyAsync(
() -> map.get(randomKey())
);
requests[3 * i + 2] = CompletableFuture.supplyAsync(
() -> map.remove(randomKey())
);
}
CompletableFuture.allOf(requests).join();
}
String randomKey() {
return KEYS.get(ThreadLocalRandom.current().nextInt(100));
}
Each time we will put a random key, get a random key, and remove a random key. Each workload would run these three operations 100 times. Adding the JMH to the mix, each workload would be executed thousands of times:
xxxxxxxxxx
(Throughput)
public void forCoarseGrainedLocking() {
workload(new CoarseGrainedConcurrentMap<>());
}
(Throughput)
public void forStripedLocking() {
workload(new LockStripedConcurrentMap<>());
}
The coarse-grained implementation can handle 8,547 operations per second on average:
xxxxxxxxxx
8547.430 ±(99.9%) 58.803 ops/s [Average]
(min, avg, max) = (8350.369, 8547.430, 8676.476), stdev = 104.523
CI (99.9%): [8488.627, 8606.234] (assumes normal distribution)
On the other hand, the fine-grained implementation can handle up to 13,855 operations per second on average.
xxxxxxxxxx
13855.946 ±(99.9%) 119.109 ops/s [Average]
(min, avg, max) = (13524.367, 13855.946, 14319.174), stdev = 211.716
CI (99.9%): [13736.837, 13975.055] (assumes normal distribution)
Recursive Split-Ordered Lists
In their paper, Ori Shalev and Nir Shavit proposed a way to implement a lock-free hashtable. They used a way of ordering elements in a linked list so that they can be repeatedly “split” using a single compare-and-swap operation. Anyway, they’ve used a pretty different approach to implement this concurrent data structure. It’s highly recommended to check out and read that paper.
Also, the source codes of this article are available on Github.
Published at DZone with permission of Ali Dehghani. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments