[CSF] LogViewer: A New Tool for Monitoring Logs
This article is a project presentation of a viewer for log files.
Join the DZone community and get the full member experience.
Join For FreeThe project is located on GitHub: https://github.com/sevdokimov/log-viewer
Introduction
There are many tools in the world for analysis logs, but most of my colleagues used the simple text editor or “less” command in the terminal. Log analysis tools can be divided into two groups:
- Applications working on the local machine. They load log files from remote servers using SFTP or SSH.
- Log aggregators. A log aggregator is a server-based application that collects logs from other applications and stores them to an index. The index allows quick navigation and search.
The main disadvantage of #1 is the time of downloading logs from a remote machine. If the log weighs about 1G, it’s not usable to download it.
Log aggregator is the right solution for serious production environments, but they require additional resources for storing index and additional configuration to collect logs. In some cases, using a log aggregator is overkill.
I got an idea of how to make a log viewer that has some advantages of log aggregators, but actually, it’s a pure viewer. It doesn’t require additional storage for an index, doesn’t download log files to the local machine, but allows viewing logs on remote servers with nice features like filtering, search, merging events from several log files to one view.
The idea is to run a tiny Web UI on a server that provides access to log files located on the server. LogViewer doesn’t load an entire file to the memory. It loads only the part that the user is watching. This approach allows displaying huge log files without significant memory consumption. If we need monitoring logs on more than one node, LogViewer must be run on all nodes. Each LogViewer instance can connect to other instances and request data located on remote nodes. So each LogViewer can show events from the entire cluster merged into one view by date.
It’s important to make the tool as easy to use as possible. That’s why LogViewer can detect log format automatically, there is no required configuration, and log representation is close to a text editor representation.
Features
Highlighting
The text becomes much more readable if key elements are highlighted. Here is all the highlighting in one image:
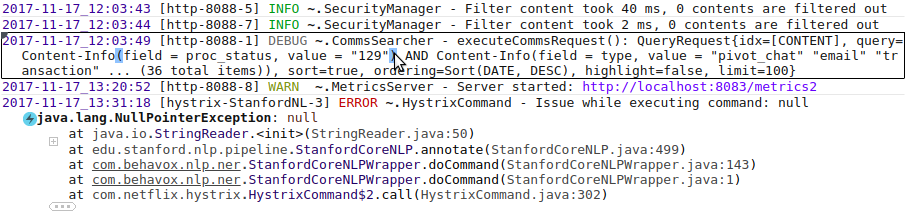
The event under the mouse cursor is emphasized with a rectangle. The severity of the events has different colors (ERROR is red, DEBUG is gray, etc). Paired brackets are highlighted when the cursor is over one of them. The exception class name is bold and the icon is added to make the exception more visible. The main part of a tracktrace element is a class name and method name; that’s why class names in each stacktrace element are highlighted with blue color.
Folding
LogViewer can hide redundant parts of a log to help focus on essential parts. For example, stacktraces of Java exceptions are quite long, but a user is only interested in the lines related to his application. Users can configure package names associated with his application, and then LogViewer will show only lines with those packages, adjacent lines, and the first line. Other lines will be folded under "+" and “...”, see the screenshot above. User can unfold the hidden text at any time by clicking to “+”.
The search works well in the folded text. If a user tries to find a string present under the folding, the folding will be unfolded automatically. If a user selects and copies text containing folding, the clipboard will contain the full text include hidden parts. It’s important to allow a user to copy the original text.
You can see the logger name “~.SecurityManager” in the screenshot, it’s a folded text too, the real logger name is “com.mycompany.foo.bar.SecurityManager”, but the package name is not essential and is replaced with “~”.
Filtering
LogViewer provides several ways to filter log events.
- Filtering by substring. This is the most commonly used type of filtering. You can input text in the Search field, press “Hide unmatched”, then only events with matched text will be shown.
- Filter by severity. There is a dropdown to select the severity of log events. You select ERROR level when you are looking for an error message, all events with lower levels will be hidden.
- Custom Groovy filter. You can define custom conditions to exclude events from the view. A condition is written in Groovy, all event fields are accessible as variables. It may be useful to exclude unmeaningful events that occur a lot of time and interfere with viewing the log
The page URL contains a hash of filter panel state, this allows refreshing the page without losing the filters and adding the page with the filter state to bookmarks.
Permanent Link to a Position in the Log
When a user found something interesting in the log, he can share it with colleagues by sending a permanent link to the position in the log. The permanent link opens the exact same view as the user saw when created the permanent link.
Merging Log Files
As mentioned above, LogViewer is a Web page, a user specifies file path via query parameters. Users can specify more than one "log" parameter in the URL. In this case, events from all files will be shown in one view. Events will be sorted by date. Of course, it's possible if the logs contain a full timestamp in each event.
If a file is located on another server, the path should be specified in the following format: log=/opt/my-app/logs/my-app.log@node-host-name . Current LogViewer instance will connect to the LogViewer instance located on node-host-name host, and load parts of /opt/my-app/logs/my-app.log file through that instance.
Video
A short video demonstrating the UI features.
Implementation Details
Language and Tools
I use Java 1.8 for the backend part, Angular 8 for frontend part, Maven as a build manager, HOCON to store application configuration, Selenium for integration tests.
The development stack was chosen only because I have experience in it.
Navigation
Each time the web page contains no more than N*3 events in the HTML document. Where N is the number of lines fit on screen.

When a user scrolls up or down, UI removes events that become farther than N items from the visible screen and loads the next events from backend. Frontend sends to backend requests like "Give me N events before/after the event with coordinate $eventCoordinate, using the filter $filter". "$eventCoordinate" consists of 3 fields: timestamp, file hash, offset from the file begin. Coordinates are ordered, unambiguous order is very important for proper displaying. In most cases, the timestamp is enough, but the timestamp is not unique, that's why coordinate contains file_hash, offset_from_file_begin fields too.
When backend gets the request, it finds the event by the coordinate (or the nearest event) and starts scanning the log to find N events matched to current filters. If more than one file is opened, the backend will find N events in each file, put all events to one list, sort it, and return N first events only.
Performance
I anticipate questions about performance. There is no index, so each search can perform a full scan of the log. Also if a filter filters out all elements, the system has to scan the entire file to make sure that no visible events exist. Actually, the full scan is not a big problem, the parser works fast enough. Parsing 1Gb file takes 3,5 sec on my machine. It is viable.
Communication Between Frontend and Backend
Frontend and backend communicate using WebSockets. But also it can be switched to "plain HTTP" mode when WebSocket messages are emulated by HTTP requests. I had to implement this mode when faced with the problem in one environment — there was a proxy that didn't support HTTP 1.1.
Format Detection
As mentioned above, the tool can detect format automatically. The format detection algorithm is not too smart. There are several predefined log formats. When the user is opening a file, the tool tries to apply each predefined format to the first 8kb of the file content. Then count how many lines were successfully parsed by each format. The format that could parse more lines than others will be assigned to the file. If no one format can parse more than 50% of lines, the system assumes that format is unknown. In this case, each line is perceived as a separate event.
Of course, the user can specify the log format explicitly in the configuration. It can be specified using log4J layout notation or using Regexp.
Embedding into Java Web Applications
Log-viewer can be embedded in Java web application. It may be useful when the application must be able to show its logs to users.
A developer can add LogViewer as a library, import one class to the Spring configuration, then his application will have an URL where a user can see the application’s log. The configuration is not required, the tool will automatically detect which log system is used by the application, where log files are stored, and what is the format. But that works for Logback and Log4J only.
Security
Web application that provides access to files system looks like a security breach. But configuration allows limit files and directories that are accessible through log-viewer. The user can specify patterns to make files visible. By default, the system shows files matched "**/*.log", this means any files with "log" extension.
Groovy filters are suspicious from a security point of view too. The tool has to run the user's code written in Groovy. A user can write any code. I use groovy-sandbox library to limit abilities of groovy code. This library allows defining while a list of methods that can be executed, other methods cannot be executed.
Working Through SSH (Not Implemented Yet)
In some cases, a public port with Web UI cannot be opened, only SSH access to the server is possible. In this case, LogViewer should support working via SSH. LogViewer can not download the entire log file from the server, but it can upload the agent to the server and run it there. Communication between the remote agent and LogViewer will go using input/output stream through SSH.
This functionality is not implemented because it wasn’t needed for me yet, but I think it’s a good idea.
Left to Do
There are a few features that must be implemented in the nearest future
Support rollover log files. When LogViewer is opening “my-app.log”, content from “my-app.log.1”, “my-app.log.2”, “my-app.log.3” must be visible as well.
Filter by date range. Adding UI to filtering by field value, Groovy filter is overkill for simple cases.
Better UI to choosing log files for opening. Currently, the only way to open several files in one view is passing all files paths to URL parameters.
Working through SSH when a public port cannot be opened on the server.
Opinions expressed by DZone contributors are their own.
Comments