Looking Inside Postgres at a GiST Index
What does the GiST API do? And what does it mean to extend Postgres’s indexing system, exactly? Read on to find out!
Join the DZone community and get the full member experience.
Join For Freein the last few posts in this series ( one , two , three , and four ), i showed you how to save hierarchical data into a flat database table using the postgres ltree extension . i explained that you represent tree nodes using path strings and how to search your tree data using special sql operators ltree provides.
but the real value of ltree isn’t the operators and functions it gives you — internally, these boil down to fairly simple string operations. instead, what makes ltree useful is that it integrates these new operators with postgres’s indexing code, which allows you to search for and find matching tree paths quickly . to achieve this, ltree takes advantage of the generalized search tree (gist) project, an api that allows c developers to extend postgres’s indexing system.
but what does the gist api do? and what does it mean to extend postgres’s indexing system, exactly? read on to find out!
searching without an index
here again is the tree table i used as an example in the earlier posts in this series:
create table tree(
id serial primary key,
letter char,
path ltree
);
note that the
path
column uses the custom
ltree
data type that the ltree extension provides. if you missed the previous posts,
ltree
columns represent hierarchical data by joining strings together with periods, i.e.
a.b.c.d
or
europe.estonia.tallinn
.
earlier, i used a simple tree with only seven nodes as an example. sql operations on a small table like this will always be fast. today, i’d like to imagine a much larger tree to explore the benefits indexes can provide. suppose that instead i have a tree containing hundreds or thousands of records in the path column:

now, suppose i search for a single tree node using a
select
statement:
select letter from tree where path = 'a.b.t.v'without an index on this table, postgres has to resort to a sequence scan , which is a technical way of saying that postgres has to iterate over all of the records in the table:
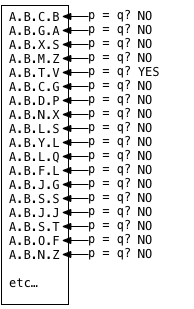
for each and every record in the table, postgres executes a comparison
p == q
where
p
is the value of the path column for each record in the table, and q is the query, or the value i’m searching for (
a.b.v.t
in this example). this loop can be very slow if there are many records. postgres has to check all of them because they can appear in any order and there’s no way to know how many matches there might be in the data ahead of time.
searching with a b-tree index
of course, there’s a simple solution to this problem. i just need to create an index on the path column:
create index tree_path_idx on tree (path);as you probably know, executing a search using an index is much faster. if you see a performance problem with a sql statement in your application, the first thing you should check for is a missing index. but why? why does creating an index speed up searches, exactly? the reason is that an index is a sorted copy of the target column’s data:

by sorting the values ahead of time, postgres can search through them much more quickly. it uses a binary search algorithm:

postgres starts by checking the value in the middle of the index. if the stored value (
p
) is too large and is greater than the query (
q
), if
p > q
, it moves up and checks the value at the 25% position. if the value is too small, if
p < q
, it moves down and checks the value at the 75% position. repeatedly dividing the index into smaller and smaller pieces, postgres only needs to search a few times before it finds the matching record or records.
however, for large tables with thousands or millions of rows, postgres can’t save all of the sorted data values in a single memory segment. instead, postgres indexes (and indexes inside of any relational database system) save values in a binary or balanced tree (b-tree):
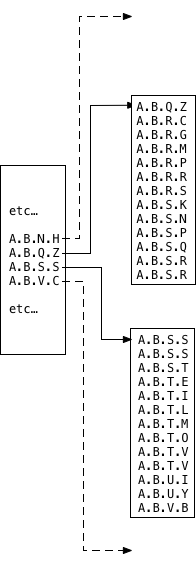
now, my values are saved in a series of different memory segments arranged in a tree structure. dividing the index up into pieces allows postgres to manage memory properly while saving possibly millions of values in the index. note that this isn’t the tree from my ltree dataset; b-trees are internal postgres data structures i don’t have access to. to learn more about the computer science behind this, read my 2014 article discovering the computer science behind postgres indexes .
now, postgres uses repeated binary searches — one for each memory segment in the b-tree — to find a value:

each value in the parent or root segment is really a pointer to a child segment. postgres first searches the root segment using a binary search to find the right pointer and then jumps down to the child segment to find the actual matching records using another binary search. the algorithm is recursive; the b-tree could contain many levels in which case the child segments would contain pointers to grandchild segments, etc.
what’s the problem with standard postgres indexes?
but there’s a serious problem here i’ve overlooked so far. postgres’s index search code only supports certain operators. above, i was searching using this select statement:
select letter from tree where path = 'a.b.t.v'
i was looking for records that were equal to my query:
p == q
. using a b-tree index, i could also have searched for records greater than or less than my query:
p < q
or
p > q
.
but what if i want to use the custom
ltree <@
(ancestor) operator? what if i want to execute this
select
statement?
select letter from tree where path <@ 'a.b.v'as we saw in the previous posts in this series, this search will return all of the ltree records that appear somewhere on the branch under a.b.v, that are descendants of the a.b.v tree node.
a standard postgres index doesn’t work here. to execute this search efficiently using an index, postgres needs to execute this comparison as it walks the b-tree:
p <@ q
. but the standard postgres index search code doesn’t support
p <@ q
. instead, if i execute this search postgres resorts to a slow sequence scan again, even if i create an index on the ltree column.
to search tree data efficiently, we need a postgres index that will perform
p <@ q
comparisons equally well as
p == q
and
p < q
comparisons. we need a gist index!
the generalized search tree (gist) project
almost 20 years ago, an open-source project at uc berkeley solved this precise problem. the generalized search tree (gist) project added an api to postgres allowing c developers to extend the set of data types that can be used in a postgres index.
quoting from the project’s web page:
in the beginning, there was the b-tree. all database search trees since the b-tree have been variations on its theme. recognizing this, we have developed a new kind of index called a generalized search tree (gist), which provides the functionality of all these trees in a single package. the gist is an extensible data structure, which allows users to develop indices over any kind of data, supporting any lookup over that data.
gist achieves this by adding an api to postgres’s index system anyone can implement for their specific data type. gist implements the general indexing and searching code but calls out to custom code at four key moments in the indexing process. quoting from the project’s web page again, here’s a quick explanation of the four methods in the gist api:

gist indexes use a tree structure similar to the b-tree we saw above. but postgres doesn’t create the gist index tree structure by itself; postgres works with implementations of the gist union, penalty and picksplit api functions described above. and when you execute a sql statement that searches for a value in a gist index, postgres uses the consistent function to find the target values.
the key here is the implementor of the gist api can decide what type of data to index and how to arrange those data values in the gist tree. postgres doesn’t care what the data values are or how the tree looks. postgres simply calls consistent any time it needs to search for a value and lets the gist api implementor find the value.
an example would help understand this, and we have an example gist api implementation: the ltree extension!
implementing the gist api for tree paths
starting in around 2001, two students at moscow state university found the api from the gist project and decided to use it to build indexing support for tree data. oleg bartunov and teodor sigaev, in effect, wrote a “tree paths consistent” function, a “tree path union” function, etc. the c code that implements this api is the ltree extension. you can find these functions,
ltree_consistent
and
ltree_union
, among other functions, in a file called
ltree_gist.c
, located in the
contrib/ltree
directory in the postgres source code. they also implemented the penalty, picksplit and various other functions related to the gist algorithm.
i can use these custom functions on my own data simply by creating a gist index. returning to my ltree example, i’ll drop my b-tree index and create a gist index instead:
drop index tree_path_idx;
create index tree_path_idx on tree using gist (path);
notice the using gist keywords in the create index command. that’s all it takes; postgres automatically finds, loads, and uses the
ltree_union
,
ltree_picksplit
,
etc., functions whenever i insert a new value into the table. (it will also insert all existing records into the index immediately.) of course, earlier, i
installed the ltree extension
also.
let’s see how this works. suppose i add a few random tree records to my empty tree table after creating the index:
insert into tree (letter, path) values ('a', 'a.b.g.a');
insert into tree (letter, path) values ('e', 'a.b.t.e');
insert into tree (letter, path) values ('m', 'a.b.r.m');
insert into tree (letter, path) values ('f', 'a.b.e.f');
insert into tree (letter, path) values ('p', 'a.b.r.p');to get things started, postgres will allocate a new memory segment for the gist index and insert my five records:

if i search now using the ancestor operator:
select count(*) from tree where path <@ 'a.b.t'
…postgres will simply iterate over the records in the same order i inserted then and call the
ltree_consistent
function for each one. here again is what the gist api calls for the consistent function to do:

in this case, postgres will compare
p <@ a.b.t
for each of these five records:

because the values of
p
, the tree page keys, are simple path strings,
ltree_consistent
directly compares them with
a.b.t
and determines immediately whether each value is a descendant tree node of
a.b.t
. right now, the gist index hasn’t provided much value; postgres has to iterate over all the values, just like a sequence scan.
now, suppose i start to add more and more records to my table. postgres can fit up to 136 ltree records into the root gist memory segment, and index scans function the same way as a sequence scan by checking all the values.

but if i insert one more record, the 137th record doesn’t fit. at this point, postgres has to do something different:
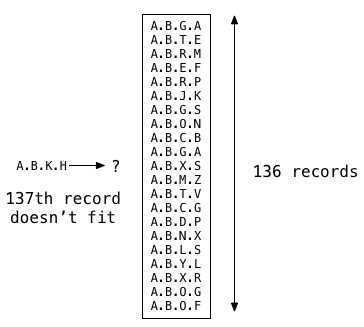
now, postgres “splits” the memory segment to make room for more values. it creates two new child memory segments and pointers to them from the parent or root segment.
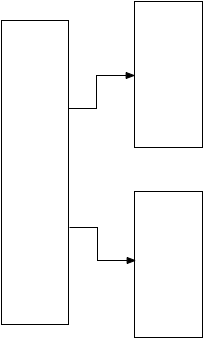
what does postgres do next? what does it place into each child segment? postgres leaves this decision to the gist api, to the ltree extension, by calling the the
ltree_picksplit
function. here again is the api spec for picksplit:

the
ltree_picksplit
function — the ltree implementation of the gist api — sorts the tree paths alphabetically and copies each half into one of the two new child segments. note that gist indexes don’t normally sort their contents; however, gist indexes created specifically by the ltree extension do because of the way
ltree_picksplit
works. we’ll see why it sorts the data in a moment.
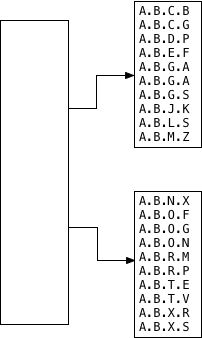
now, postgres has to decide what to leave in the root segment. to do this, it calls the union gist api:

in this example, each of the child segments is a set
s
. and the
ltree_union
function has to return a “union” value for each child segment that describes somehow what values are present in that segment:
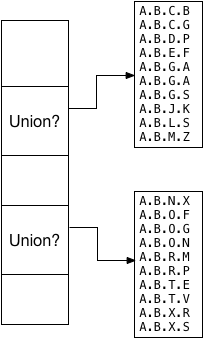
oleg and teodor decided this union value should be a pair of left/right values indicating the minimum and maximum tree branches inside of which all of the values fit alphabetically. this is why the ltree_picksplit function sorted the values. for example, because the first child segment contains the sorted values from a.b.c.b through a.b.m.z, the left/right union becomes a and a.b.m:
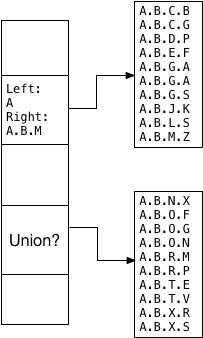
note that
a.b.m
is sufficient here to form a union value excluding
a.b.n.x
and all the following values; ltree doesn’t need to save
a.b.m.z
.
similarly, the left/right union for the second child segment becomes
a.b.n
/
a.b.x
:
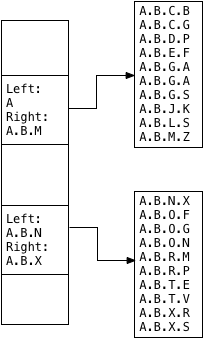
this is what a gist index looks like — or, what an ltree gist index looks like, specifically. the power of the gist api is that anyone can use it to create a postgres index for any type of data. postgres will always use the same pattern: the parent index page contains a set of union values, each of which somehow describes the contents of each child index page.
for ltree gist indexes, postgres saves left/right value pairs to describe the union of values that appear in each child index segment. for other types of gist indexes, the union values could be anything. for example, a gist index could store geographical information like latitude/longitude coordinates, or colors, or any sort of data at all. what’s important is that each union value describe the set of possible values that can appear under a certain branch of the index. and like b-trees, this union value/child page pattern is recursive: a gist index could hold millions of values in a tree with many pages saved in a large multi-level tree.
searching a gist index
after creating this gist index tree, searching for a value is straightforward. postgres uses the ltree_consistent function. as an example, let’s repeat the same sql query from above:
select count(*) from tree where path <@ 'a.b.t'
to execute this using the gist index, postgres iterates over the union values in the root memory segment and calls the
ltree_consistent
function for each one:
now, postgres passes each union value to
ltree_consistent
to calculate the
p <@ q
formula. the code inside of
ltree_consistent
then returns
maybe
if
q > left
and
q < right
. otherwise, it returns
no
.
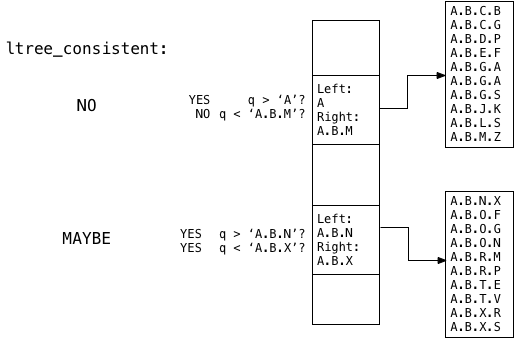
in this example, you can see
ltree_consistent
finds that the query
a.b.t
, or
q
,
maybe
is located inside the second child memory segment, but not the first one.
for the first child union structure,
ltree_consistent
finds
q > a true
but
q < a.b.m
false. therefore,
ltree_consistent
knows there can be no matches in the top child segment, so it skips down to the second union structure.
for the second child union structure,
ltree_consistent
finds both
q > a.b.n
true and
q < a.b.x
true. therefore, it returns
maybe
, meaning the search continues in the lower child segment:

note that postgres never had to search the first child segment: the tree structure limits the comparisons necessary to only the values that might match
p <@ a.b.t
.
imagine my table contained a million rows. searches using the gist index will still be fast because the gist tree limits the scope of the search. instead of executing
p <@ q
on every one of the million rows, postgres only needs to run
p <@ q
a handful of times, on a few union records and on the child segments of the tree that contain values that might match.
send them a postcard
oleg bartunov and teodor sigaev, the authors of the ltree extension, explain its usage and the algorithms i detailed above here on their
web page
. they included more examples of sql searches on tree data, including some which use the
ltree[]
data type i didn’t have time to cover in these blog posts.
but most importantly, they included this note at the bottom:

do you save tree data in postgres? does your app take advantage of the ltree extension? if so, you should send oleg and teodor a postcard! i just did.
Published at DZone with permission of Pat Shaughnessy. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments