Low Code Serverless Integration With Kafka
In this article, we will build out a scenario of publishing messages from AWS Lambda to a Kafka topic.
Join the DZone community and get the full member experience.
Join For FreeKafka is a popular choice when huge volumes of real-time data streaming is a requirement. Simply, Kafka allows you to send messages between different components / applications in a distributed environment, facilitating an event-driven architecture.
Serverless compute is increasingly being preferred as the solution of choice for running application code on the cloud.
In this article, we will build out a scenario of publishing messages from AWS Lambda to a Kafka topic. Consider a stock brokerage, where publishing real-time updates to stock prices (called a stock ticker) is one of the core requirements. Given the volume of such messages to be published in sub-second duration, Kafka becomes a natural fit.
Use Case
Business scenario for the use case is depicted below.
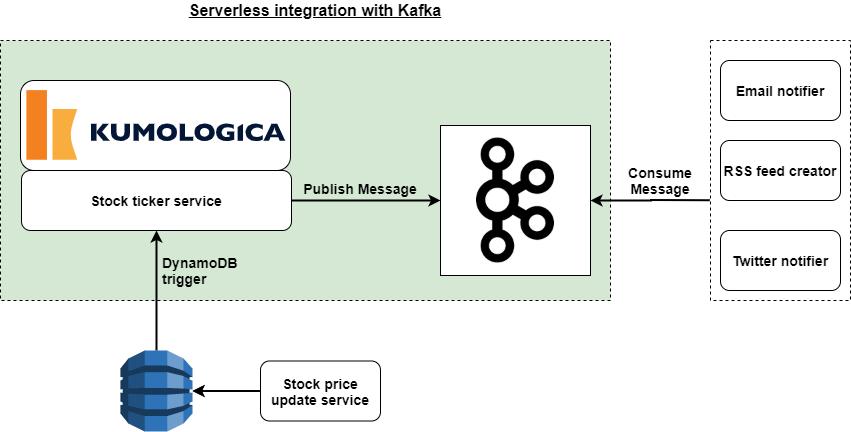
- Stock price update service keeps updating DynamoDB table with changes to the price of a stock.
- The DynamoDB table has streams enabled into which the stock symbols of the stocks whose price got updated are published.
- Stock ticker service listens for the stock symbol, and looks up details like:
- Stock name
- Current price
- Last traded price
- Percentage change in price
and publishes it as a message to a Kafka topic.
4. The Kafka topic is consumed downstream and acted upon accordingly.
In this article we will build the Stock ticker service that listens to DynamoDB streams and publishes appropriate messages to Kafka streams.
Prerequisite
- Kumologica designer installed in your machine. https://kumologica.com/download.html
- Access to a Kafka broker end-point. For this implementation, we ran a Docker image of Apache Kafka locally.
- A DynamoDB table with a structure as below:

Implementation
Kumologica flow for this use case will use the process logic as outlined below:
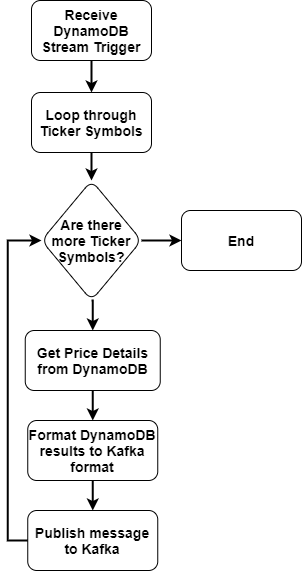
The implemented flow looks like this:

This flow is available in GIT at: Stock Ticker Service Flow
To import this flow into Kumologica designer, follow the steps below:
- Open Kumologica Designer, click the Home button and choose Create New Kumologica Project.
- Enter name (for example: KafkaFlow), select directory for project and switch Source into From Existing Flow …
- Copy and paste the flow json content that you downloaded from GIT.
- Press Create Button.
- The designer palette will show the flow.
Once the import is done, configure as below:
- If you have not already installed the Kafka node, do so by clicking on the “Add more nodes” button in the Kumologica editor, and install the Kafka node.
- Ensure that you update the following nodes:
- DynamoDB: update the table ARN
- Kafka: Kafka topic name and Kafka broker name
to reflect the environment that you are working with.
Testing
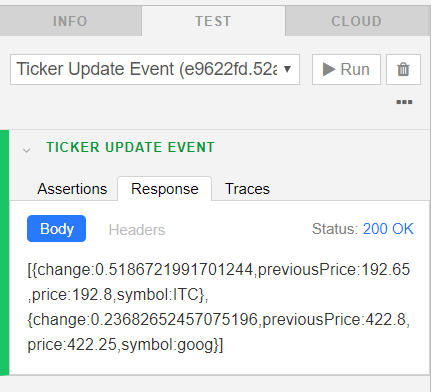
Kumologica Editor Integrated Tester
The flow can be tested from within the Kumologica editor using the TEST tab. A test case with the name “Ticker Update Event” is already available in the imported flow. Submit the test case and check that the message is published to the configured Kafka topic.
Deploy Flow to AWS Lambda
- Choose the CLOUD tab on the right side pane.
- Select the AWS profile that has required permissions to deploy Lambda.
- Under TRIGGERS section, select “Amazon DynamoDB” from the available options. For “Stream ARN”, provide the ARN of the DynamoDB stream.
- Click the DEPLOY button, and this triggers the build and deployment of the flow to AWS. The progress of the deployment can be tracked from the console.
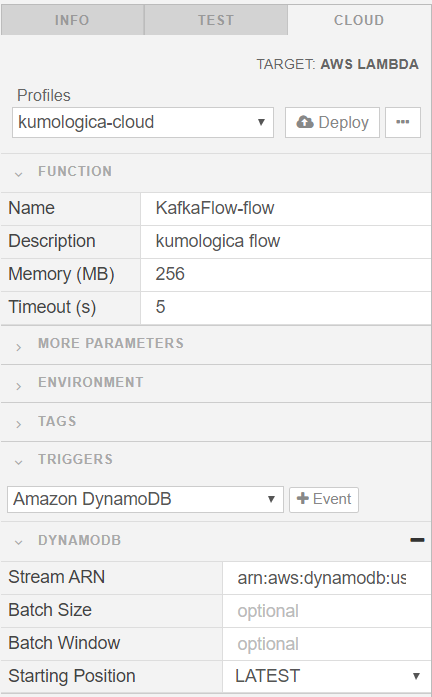
For testing, make some changes to the records in the DynamoDB table, and verify that the corresponding message is getting published to the Kafka topic.
Conclusion
This is a simple demonstration of the capabilities of Kumologica that enabled us to develop a complex use case with simple configuration of nodes. All the intricacies of the integration is taken care by Kumologica. Within few minutes we have created and deployed the Stock Ticker Service Kumologica flow.
Kumologica is totally free to download and use. Go ahead and give it a try, we would love to hear your feedback.
In the meantime, if there is a specific use case that you would like to see in a future article, please let us know in the comments section.
Opinions expressed by DZone contributors are their own.
Comments