Machine Learning Algorithms: Which One to Choose for Your Problem
Many articles about machine learning algorithms provide great definitions — but they don't make it easier to choose which algorithm you should use. Enter: this article!
Join the DZone community and get the full member experience.
Join For FreeWhen I was beginning my journey in data science, I often faced the problem of choosing the most appropriate algorithm for my specific problem. If you’re like me, when you open some article about machine learning algorithms, you see dozens of detailed descriptions. The paradox is that this doesn't make it easier to choose which one to use.
In this article for Statsbot, I will try to explain basic concepts and give some intuition of using different kinds of machine learning algorithms for different tasks. At the end of the article, you’ll find a structured overview of the main features of described algorithms.

First of all, you should distinguish the four types of machine learning tasks:
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
- Reinforcement learning
Supervised Learning
Supervised learning is the task of inferring a function from labeled training data. By fitting to the labeled training set, we want to find the most optimal model parameters to predict unknown labels on other objects (test sets). If the label is a real number, we call the task regression. If the label is from a limited number of values, where these values are unordered, then it’s classification.

Unsupervised Learning
In unsupervised learning, we have less information about objects. In particular, the train set is unlabeled. What is our goal now? It’s possible to observe some similarities between groups of objects and include them in appropriate clusters. Some objects can differ hugely from all clusters, and in this way, we assume these objects to be anomalies.

Semi-Supervised Learning
Semi-supervised learning tasks include both of the problems we described earlier: they use labeled and unlabeled data. That is a great opportunity for those who can’t afford to label their data. The method allows us to significantly improve accuracy because we can use unlabeled data in the train set with a small amount of labeled data.
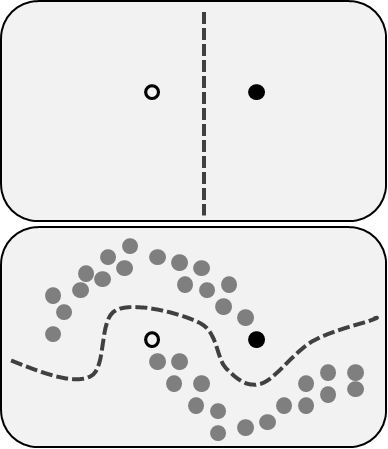
Reinforcement Learning
Reinforcement learning is not like any of our previous tasks because we don’t have labeled or unlabeled datasets here. RL is an area of machine learning concerned with how software agents ought to take actions in some environment to maximize some notion of cumulative reward.
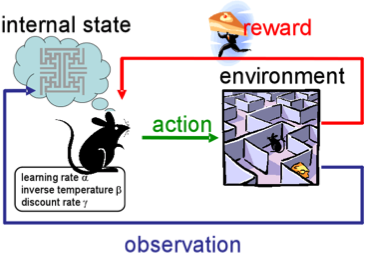
Imagine that you’re a robot in some strange place. You can perform activities and get rewards from the environment for them. After each action, your behavior is getting more complex and clever, so you are training to behave the most effective way on each step. In biology, this is called adaptation to the natural environment.
Commonly Used Machine Learning Algorithms
Now that we have some intuition about types of machine learning tasks, let’s explore the most popular algorithms with their applications in real life.
Linear Regression and Linear Classifier
These are probably the simplest algorithms in machine learning. You have features x1,…xn of objects (matrix A) and labels (vector b). Your goal is to find the most optimal weights w1,…wn and bias for these features according to some loss function; for example, MSE or MAE for a regression problem. In the case of MSE there is a mathematical equation from the least squares method:
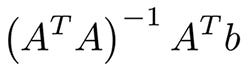
In practice, it’s easier to optimize it with gradient descent, that is much more computationally efficient. Despite the simplicity of this algorithm, it works pretty well when you have thousands of features; for example, bag of words or n-grams in text analysis. More complex algorithms suffer from overfitting many features and not huge datasets, while linear regression provides decent quality.

To prevent overfitting, we often use regularization techniques like lasso and ridge. The idea is to add the sum of modules of weights and the sum of squares of weights, respectively, to our loss function. Read a great tutorial on these algorithms at the end of the article.
Logistic Regression
Don’t confuse these classification algorithms with regression methods for using “regression” in its title. Logistic regression performs binary classification, so the label outputs are binary. Let’s define P(y=1|x) as the conditional probability that the output y is 1 under the condition that there is given the input feature vector x. The coefficients w are the weights that the model wants to learn.

Since this algorithm calculates the probability of belonging to each class, you should take into account how much the probability differs from 0 or 1 and average it over all objects, as we did with linear regression. Such a loss function is the average of cross-entropies:
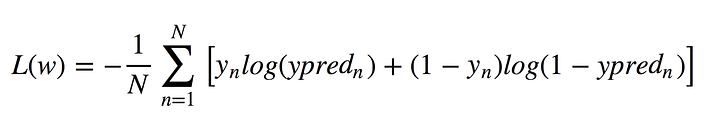
Don’t panic! I’ll make it easy for you. Allow y to be the right answers: 0 or 1, y_pred — predicted answers. If y equals 0, then the first addend under sum equals 0 and the second is the less the closer our predicted y_pred to 0 according to the properties of the logarithm. Similarly, in the case when y equals 1.
What is great about a logistic regression? It takes the linear combination of features and applies a non-linear function (sigmoid) to it, so it’s a very very small instance of a neural network!
Decision Trees
Another popular and easy-to-understand algorithm is decision trees. Their graphics help you see what you’re thinking and their engine requires a systematic, documented thought process.
The idea of this algorithm is quite simple. In every node, we choose the best split among all features and all possible split points. Each split is selected in such a way as to maximize some functional. In classification trees, we use cross-entropy and Gini index. In regression trees, we minimize the sum of a squared error between the predictive variable of the target values of the points that fall in that region and the one we assign to it.
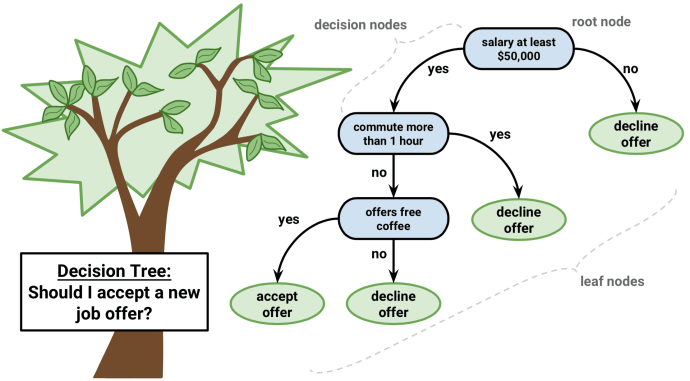
We make this procedure recursively for each node and finish when we meet stopping criteria. They can vary from a minimum number of leafs in a node to tree height. Single trees are used very rarely, but in composition with many others, they build very efficient algorithms such as random forest or gradient tree boosting.
K-Means
Sometimes, you don’t know any labels, and your goal is to assign labels according to the features of objects. This is called a clusterization task.
Suppose you want to divide all data objects into k clusters. You need to select random k points from your data and name them centers of clusters. The clusters of other objects are defined by the closest cluster center. Then, centers of the clusters are converted and the process repeats until convergence.

This is the clearest clusterization technique but it still has some disadvantages. First of all, you should know a number of clusters that we can’t know. Secondly, the result depends on the points randomly chosen at the beginning and the algorithm doesn’t guarantee that we’ll achieve the global minimum of the functional.
There is a range of clustering methods with different advantages and disadvantages, which you could learn in recommended reading.
Principal Component Analysis (PCA)
Have you ever prepared for a difficult exam the night, or even the morning, before it was going to happen? There's no way that you can remember all the information you need to, but you want to maximize the information that you can remember in the time available; for example, learning first the theorems that occur in many exams and so on.
Principal component analysis is based on the same idea. This algorithm provides dimensionality reduction. Sometimes you have a wide range of features, probably highly correlated between each other, and models can easily overfit on a huge amount of data. Then, you can apply PCA.
Surprisingly, these vectors are eigenvectors of correlation matrix of features from a dataset.
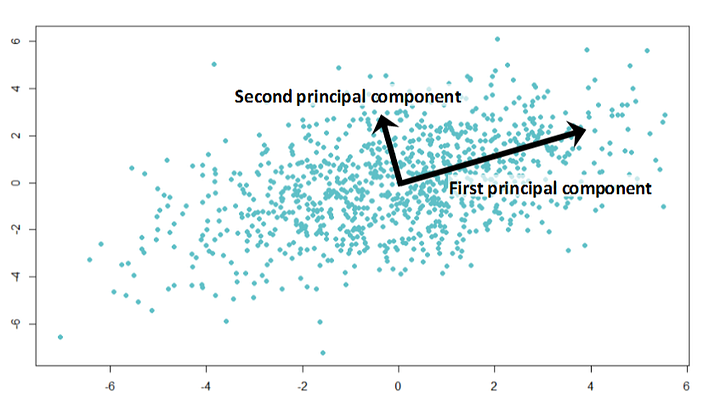
The algorithm now is clear:
We calculate the correlation matrix of feature columns and find eigenvectors of this matrix.
We take these multidimensional vectors and calculate the projection of all features on them.
New features are coordinates from a projection and their number depends on the count of eigenvectors, on which you calculate the projection.
Neural Networks
I already mentioned neural networks when we talked about logistic regression. There are a lot of different architectures that are valuable in very specific tasks. More often, it’s a range of layers or components with linear connections among them and following nonlinearities.
If you’re working with images, convolutional deep neural networks show the great results. Nonlinearities are represented by convolutional and pooling layers, capable of capturing the characteristic features of images.

For working with texts and sequences, you’d better choose recurrent neural networks. RNNs contain LSTM or GRU modules and can work with data for which we know the dimension in advance. One of the most known applications of RNNs is machine translation.
Conclusion
I hope that you now understand common perceptions of the most used machine learning algorithms and give intuition on how to choose one for your specific problem. To make things easier for you, I’ve prepared a structured overview of their main features:
Linear regression and linear classifier: Despite an apparent simplicity, they are very useful on a huge amount of features where better algorithms suffer from overfitting.
Logistic regression: The simplest non-linear classifier with a linear combination of parameters and nonlinear function (sigmoid) for binary classification.
Decision trees: Often similar to people’s decision process and is easy to interpret, but they are most often used in compositions such as random forest or gradient boosting.
K-means: A more primal but very easy-to-understand the algorithm that can be perfect as a baseline in a variety of problems.
PCA: A great choice to reduce the dimensionality of your feature space with minimum loss of information.
Neural networks: A new era of machine learning algorithms that can be applied for many tasks, but their training needs huge computational complexity.
Recommended Sources
Published at DZone with permission of Daniil Korbut. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments