Machine Learning: Validation Techniques
In this post, you will briefly learn about different validation techniques: resubstitution, hold-out, k-fold cross-validation, LOOCV, random subsampling, and bootstrapping.
Join the DZone community and get the full member experience.
Join For FreeValidation techniques in machine learning are used to get the error rate of the ML model, which can be considered as close to the true error rate of the population. If the data volume is large enough to be representative of the population, you may not need the validation techniques. However, in real-world scenarios, we work with samples of data that may not be a true representative of the population. This is where validation techniques come into the picture.
In this post, you will briefly learn about different validation techniques:
- Resubstitution
- Hold-out
- K-fold cross-validation
- LOOCV
- Random subsampling
- Bootstrapping
Machine Learning Validation Techniques
Resubstitution
If all the data is used for training the model and the error rate is evaluated based on outcome vs. actual value from the same training data set, this error is called the resubstitution error. This technique is called the resubstitution validation technique.
Holdout
To avoid the resubstitution error, the data is split into two different datasets labeled as a training and a testing dataset. This can be a 60/40 or 70/30 or 80/20 split. This technique is called the hold-out validation technique. In this case, there is a likelihood that uneven distribution of different classes of data is found in training and test dataset. To fix this, the training and test dataset is created with equal distribution of different classes of data. This process is called stratification.
K-Fold Cross-Validation
In this technique, k-1 folds are used for training and the remaining one is used for testing as shown in the picture given below. 
Figure 1: K-fold cross-validation
The advantage is that entire data is used for training and testing. The error rate of the model is average of the error rate of each iteration. This technique can also be called a form the repeated hold-out method. The error rate could be improved by using stratification technique.
Leave-One-Out Cross-Validation (LOOCV)
In this technique, all of the data except one record is used for training and one record is used for testing. This process is repeated for N times if there are N records. The advantage is that entire data is used for training and testing. The error rate of the model is average of the error rate of each iteration. The following diagram represents the LOOCV validation technique. 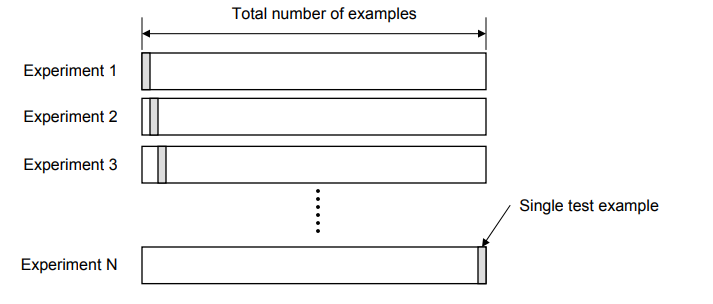
Figure 2: LOOCV validation technique
Random Subsampling
In this technique, multiple sets of data are randomly chosen from the dataset and combined to form a test dataset. The remaining data forms the training dataset. The following diagram represents the random subsampling validation technique. The error rate of the model is the average of the error rate of each iteration. 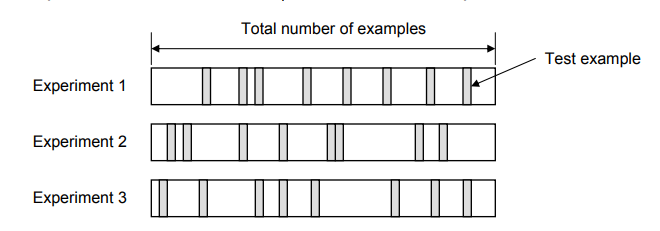
Figure 3: Random subsampling validation technique
Bootstrapping
In this technique, the training dataset is randomly selected with replacement. The remaining examples that were not selected for training are used for testing. Unlike K-fold cross-validation, the value is likely to change from fold-to-fold. The error rate of the model is average of the error rate of each iteration. The following diagram represents the same. 
Figure 4: Bootstrapping validation technique
Published at DZone with permission of Ajitesh Kumar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments