MCP Servers Are Everywhere, but Most Are Collecting Dust: Key Lessons We Learned to Avoid That
Teams rushing to build MCP servers are discovering that enthusiasm doesn’t translate into usefulness. This article unpacks why and how to make your MCP server valuable.
Join the DZone community and get the full member experience.
Join For FreeIt took a little while to gain traction after Anthropic released the Model Context Protocol in November 2024, but the protocol has seen a recent boom in adoption, especially after the announcement that both OpenAI and Google will support the standard.
And it’s simple to understand why. The MCP proposed to solve, with an elegant solution, two of the biggest problems of AI tools: access to high-quality, specific data about your system, and integration with your existing tool stack.
But it’s not all roses. In fact, one of the most popular memes about this topic calls out how “MCP is probably the only piece of tech that has more builders than users”.
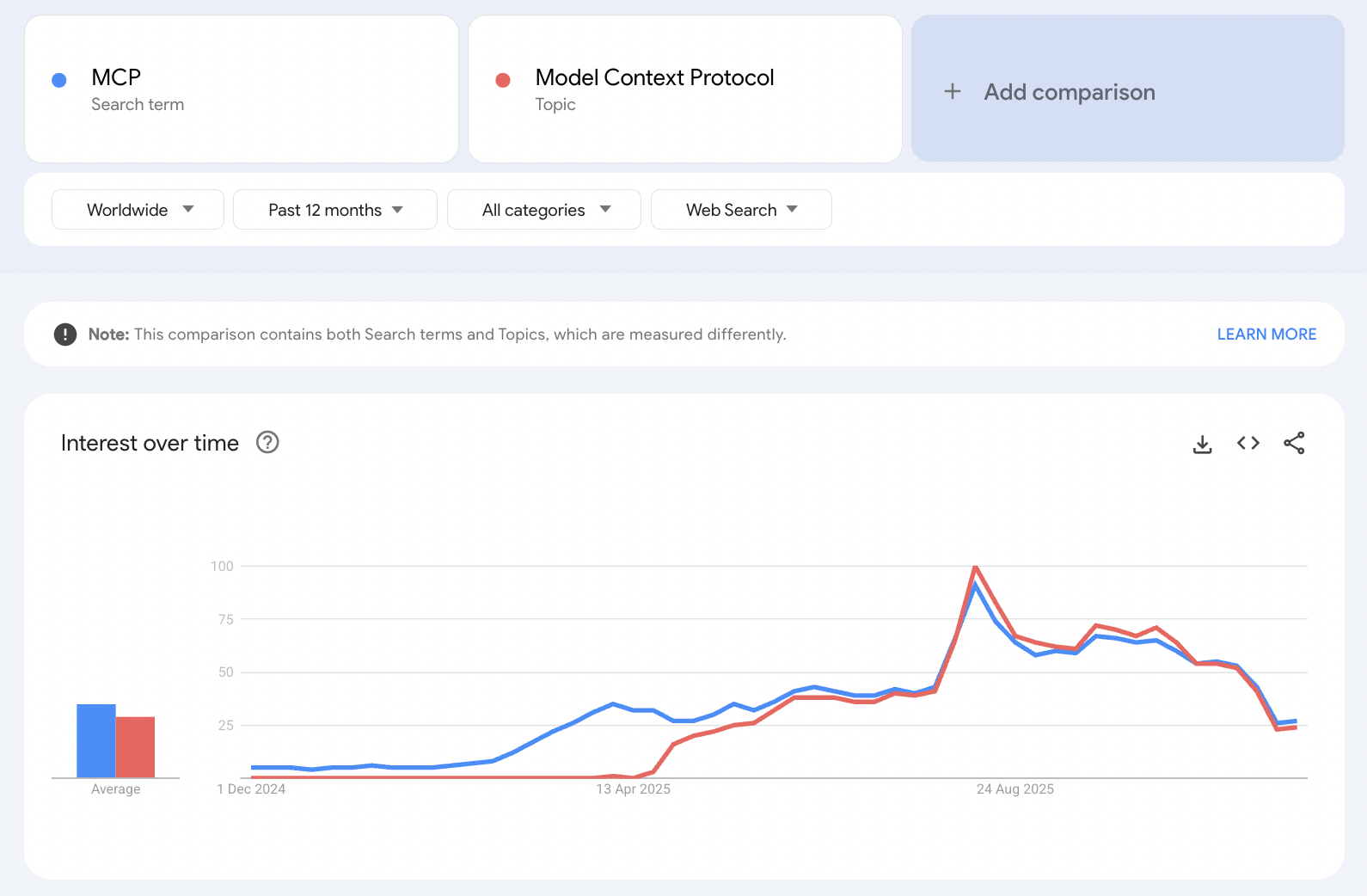
Users are starting to realize that a lot of the MCP servers out there are of dubious value and were probably built out of a sense of curiosity or just wanting to jump on the AI hype train. In fact, even worldwide searches for MCP saw a significant decline beginning in mid Q3.
The Data Problem MCP Aims to Solve
Data quality has always been the hidden variable in AI. Most coding assistants are trained on public datasets from the web. And as everyone by now knows, the quality of the output depends on the quality of the data on which the LLM is trained and how effectively you phrase your prompt.
Here’s the catch for engineers:
Your codebase isn’t in the training set.
AI models aren’t trained on your private repositories, your specific application use case, or the quirky integration logic your team built three years ago. Out of the box, they only “know” patterns that look like generic open-source projects.
Pre-MCP, adding context was painful.
If you wanted to make an AI tool useful on your system, you had to stuff that context into the prompt. But there are hard limits on how much you can fit:
- Technical limits: Even the largest context windows today (128K tokens in the best models, ~1M in a few experimental ones) aren’t big enough for most real systems. Models that support giant contexts usually hallucinate more and aren’t as good at code reasoning.
- Economic limits: Every time you ask a follow-up question, you pay for re-sending that massive context window. At hundreds of thousands of tokens per request, costs spiral quickly.
The result is that most engineers end up using AI tools in a very narrow way. Maybe on a single microservice, maybe just on a small portion of their application. For a system with dozens of interconnected services, pulling in enough context is either technically impossible or prohibitively expensive.
Take a simple example. We built a fun little “Time Travel” demo app for Multiplayer with only ~48K lines of code - its whole purpose is to send realistic data to our sandbox, to show users how our product would work with a “real” application.
If you assume ~2 tokens per line, just representing the code alone would consume the entire context window of a 100K-token model. And code is only one piece of the puzzle.
In reality, a developer debugging or shipping a feature needs far more than just source code. They also need:
- Frontend data (session replays to see what the user did)
- Backend data (logs, traces, metrics from APM/observability tools)
- Collaboration context (tickets, design docs, intent behind a feature decision)
Before MCP servers, collecting all of this was a manual, fragmented process. You’d need to query different systems, normalize formats, and feed them piecemeal into the AI. Every connector was a one-off integration: one for Snowflake into Claude, another custom one for your APM, another for your user bug reports … and so on. That required specialized engineering work and constant maintenance.
In short: AI coding tools struggled not because the models were weak, but because they were lacking clean, correlated, system-specific data. The context engineers actual need was either too big to fit, too costly to supply, or too hard to wire up.
Data Matters, but Scope Matters Too
Yes, data quality matters. But scope matters equally as much. If you have a well-defined use case, MCP can be transformative. If you’re just trying to check a “Supports MCP” box, it’ll end up gathering dust on the figurative “dev tool shelf”.
And this isn’t only a question of “Should this be an API integration or an MCP server?”, though that’s an important decision. Bill Doerrfeld’s excellent piece, “When Is MCP Actually Worth It?” is a great read on that topic. The real question is "What concrete user problem are you trying to solve?"
My recommendation is to put your APIs aside and think about integrations and what users actually want to do.
Maybe go even a step further: don’t start from the technology at all. Start from the pain point you're trying yo eliminate. Just as AI by itself doesn’t magically transform a business, MCP doesn’t add value unless it’s closing an existing, proven workflow gap.
In fact, adding AI or MCP features prematurely can make your product worse: slower, more complex, or simply irrelevant if it solves a problem no one actually has. As Stephen Whitworth of incident.io wisely said, “Look less at what cool new things AI could do, and more at what your users do 100 times a day that AI could make better.”
That perspective shaped how we built our own MCP server at Multiplayer.
We didn’t start with “let’s build an MCP.” We started by observing how developers already used Multiplayer: to debug issues and to design new features.
From there, the design choices became obvious.
- For debugging, we could pipe full-stack session data directly into AI tools.
- For feature development, we could surface annotations and sketches from replays to give the AI richer context.
In both cases, we weren’t introducing a new workflow. We were completing one. Developers already use Multiplayer to capture, correlate, and analyze data across their stack. By enabling them to feed that same data into their MCP environment, we made their existing tools smarter without adding friction.
The biggest lesson we learned: let use cases define the scope. Build MCP around real workflows, not around the acronym.
Building an MCP Server in Practice
Once you define the scope, the next challenge is to turn it into a real MCP implementation.
One of the easiest traps for teams is to make MCP tools behave like API request proxies: simply exposing every data endpoint to the model. It’s an understandable instinct. If data is good, more data must be better. But in practice, that approach quickly overwhelms the model and confuses its reasoning.
Designing practical MCP tools requires more than wrapping your existing APIs. If you mirror every REST endpoint one-to-one, AI agents struggle to use them meaningfully. Sometimes, fewer, better-defined tools lead to far more reliable outcomes. The key is to design around user intent, not backend structure.
When we built our MCP server, we followed a few core principles:
- Design tools by logical use, not by endpoint. We merged data from multiple API routes into unified tools grouped by user workflow rather than internal architecture.
- Keep it stateless and scalable. The server can run across environments with no shared state.
- Support flexible authentication. We offer both OAuth and API key modes.
- Standardize data for AI. All consumable data is exposed through consistent MCP resources instead of bespoke APIs.
Because Multiplayer already exposed rich datasets — session data, logs, traces, notes, screenshots, and sketches — the question wasn’t just what to make available, but also how to shape it for AI consumption. Each session in Multiplayer represents a dense web of interconnected data, and sending it all raw would exceed token limits and bury the useful signal.
Our focus became pre-filtering, flattening, and contextualizing the data before it reaches the MCP layer, giving the AI just enough to reason effectively without drowning it in noise.
One practical bottleneck was screenshot generation, which is resource-intensive. We optimized this by caching session assets (notes, screenshots) and regenerating them only when the underlying data changed. It was a small adjustment that made a big difference in performance.
We’re still evolving the system. Large sessions remain a known limitation since we don’t yet split them automatically. The next iteration introduces automatic chunking and summarization, allowing even multi-gigabyte sessions to be divided into manageable, model-friendly contexts.
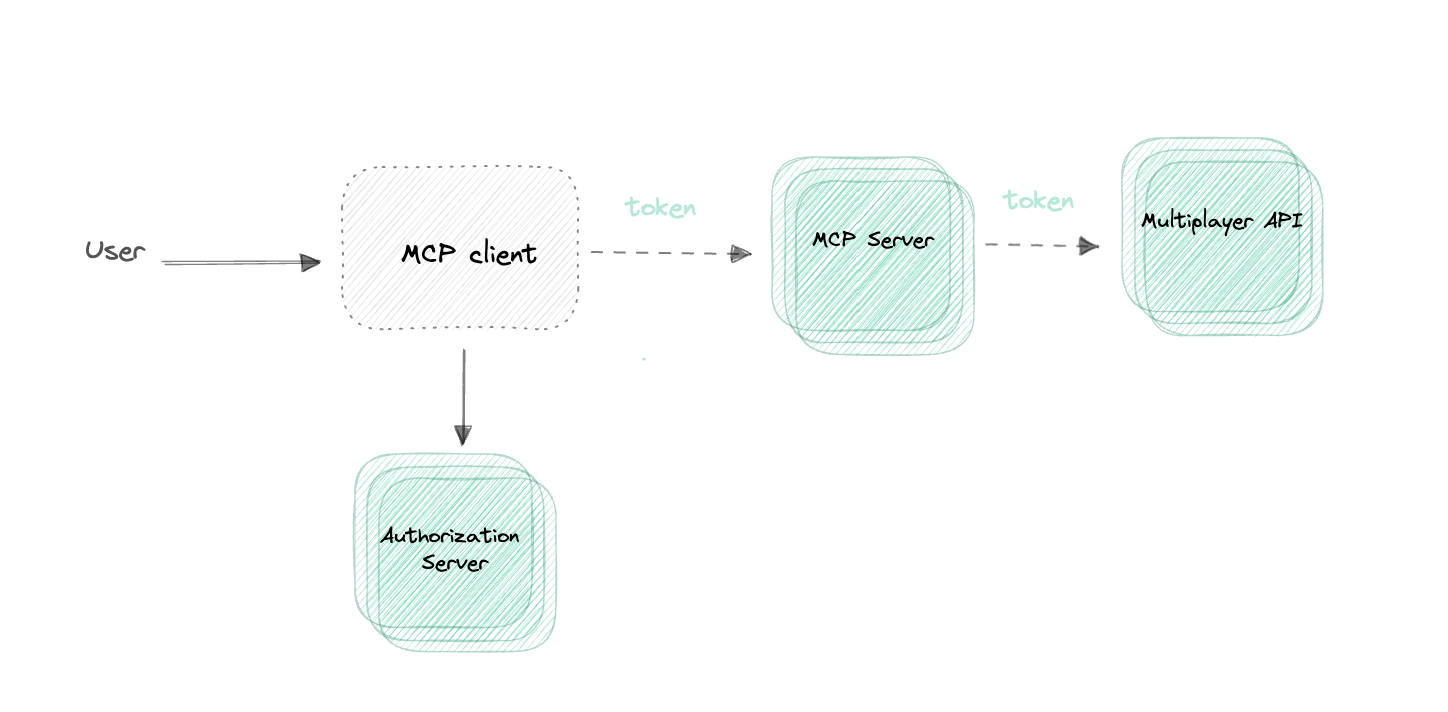
Limit What the MCP Can Do
Security is one of the most complex challenges in MCP systems. By design, MCP gives AI agents access to a broad range of tools and services, making the potential attack surface large.
Researchers have identified key risks such as tool poisoning (a compromised tool feeding malicious data), rug pulls (a once-trusted server turning malicious), tool shadowing (one tool impersonating another), and remote command execution (unauthorized code running on a system).
Because MCP servers can read, write, and connect across environments, safeguarding context data is critical. Robust access controls, auditability, and compliance checks should be built in from day one.
At Multiplayer, our guiding principle was simple: Limit what the MCP can do. Scope is a security decision.
It’s much easier to secure actions that request data than actions that change data. For now, our MCP server focuses exclusively on exposing read-only, full-stack session recording data to AI tools. That gives users rich debugging and development context without granting write privileges to production systems.
Keeping Risk Manageable
We also evaluated different deployment models. Early on, we experimented with a local MCP setup, but later switched to a remote MCP server with full OAuth 2.0 support for stronger authentication and access control. OAuth allows us to issue scoped tokens per tool and per session, meaning an AI agent can only access what it actually needs.
For teams who prefer a more straightforward setup, we still support API keys for backward compatibility, but with limited scopes and restricted actions.
In practice, implementing OAuth 2.0 consumed most of the build effort: when we began, MCP’s OAuth standards were still stabilizing, but once that foundation matured, the rest of the implementation was straightforward thanks to the excellent MCP developer documentation.
Security risks in MCP systems increase exponentially with the number of tools in play. A recent Pynt study analyzing 281 MCP configurations found that using just 10 plugins can raise the risk of exploitation to over 90%. That’s why our philosophy is to minimize the number of moving parts.
The problem we’re solving (giving developers full-stack context in one place) already exists within Multiplayer sessions. Our MCP makes that data usable by AI tools. We don’t rely on multiple MCPs for APM data, user sessions, or notes; everything flows through one secure layer.
Conclusion
At its core, the Model Context Protocol isn’t about exposing more data: it’s about exposing the right data in the right way. MCP tools are built for LLMs, not humans. Which means the goal isn’t to mirror your backend, but to give the model just enough clarity to be useful.
That starts with understanding user intent. Each tool should deliver concise, context-rich, and semantically meaningful information. The art of MCP design lies in curating, not dumping.
In effect, building an MCP server should follow the same discipline as designing a good public API: well-defined scopes, predictable behavior, and thoughtful access control. Using OAuth for authentication and keeping interactions read-only greatly limits the potential blast radius. But even then, no system is immune to emerging generative AI risks, such as prompt injection attacks or context manipulation.
Ultimately, the lesson we learned at Multiplayer is that MCP design is context design. The best systems are those that make data meaningful, safe, and actionable.
Opinions expressed by DZone contributors are their own.
Comments