Parameters to Measure in Chaos Engineering Experiments
This journal outlines key parameters to measure in Chaos Engineering experiments, such as system performance, availability, fault tolerance, and user experience.
Join the DZone community and get the full member experience.
Join For FreeKeywords: Chaos Engineering, System Resilience, Failure Injection, Performance Metrics, Fault Tolerance
Abstract
Chaos Engineering is an essential practice for testing system resilience by intentionally injecting failures and analyzing the system’s response. This journal explores key parameters to measure in Chaos Engineering experiments, including system performance, availability, fault tolerance, and user experience metrics. By systematically monitoring these parameters, organizations can proactively identify weaknesses, enhance failover mechanisms, and optimize recovery strategies. The study also provides a structured experiment template to help teams document and analyze chaos experiments effectively. The ultimate goal is to build confidence in a system’s ability to withstand turbulent operational conditions and ensure reliable service delivery.
Introduction
Chaos Engineering's intent is to add faults in a controlled manner through well-planned experiments in order to build confidence in the system to be able to tolerate turbulent operational conditions. To ensure effective chaos experiments, it is critical to measure specific parameters that reflect system performance, reliability, fault tolerance, and user experience. Typical stages of a chaos engineering experiment include:
- Identify system steady state
- Introduce a fault condition hypothesis
- Run the experiment
- Verify results
- Improve system’s handling of this fault condition
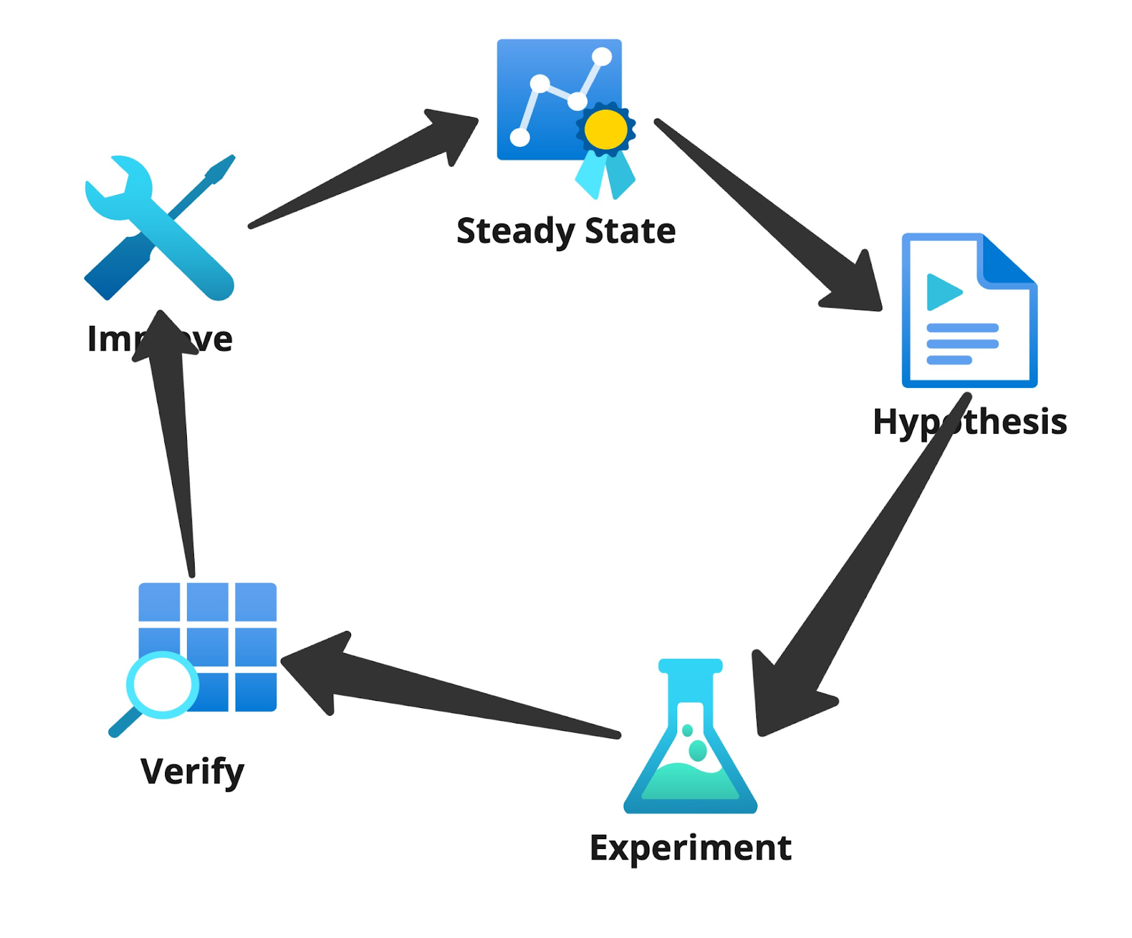
Clearly defining and quantifying each stage is crucial to achieving effective results. This journal entry outlines key parameters to measure and provides a structured template for documenting chaos experiments.
Parameters To Measure
To conduct an effective Chaos Engineering experiment, it is essential to measure key parameters that provide insights into how a system responds to failure injections. These parameters help in evaluating system stability, detecting potential vulnerabilities, and ensuring service continuity. The following sections outline the primary categories of metrics that should be observed during a chaos experiment to assess the impact on system performance, availability, fault tolerance, and user experience.
System Performance Metrics
System performance metrics help in understanding the impact of failure injections on the core functionality of the system. By closely monitoring these metrics, teams can assess how efficiently the system processes requests, handles loads, and maintains operational stability under stress conditions. Key performance indicators include:
- Response Time (Latency): Measure the system's request/response time before, during, and after the failure injection.
- Throughput (Requests Per Second): Evaluate whether the system maintains expected levels of request handling.
- Error Rate: Track the number of failed transactions (HTTP 4xx/5xx, database errors, etc.).
- Resource Utilization: Monitor CPU, memory, disk I/O, and network latency for signs of degradation.
Availability and Reliability Metrics
Ensuring system availability and reliability is crucial for maintaining uninterrupted service delivery. These metrics help in evaluating how well the system can withstand failures and recover quickly from disruptions, ensuring minimal impact on users and business operations.
- Service Uptime/Downtime: Measure how long the system remains available during the experiment.
- Mean Time to Recovery (MTTR): Calculate how quickly the system recovers from a failure.
- Mean Time Between Failures (MTBF): Assess the frequency of failures.
- Dependency Health Checks: Verify if essential services, databases, and third-party APIs remain accessible.
Fault Tolerance and Recovery Metrics
Fault tolerance and recovery metrics provide insights into how well the system can handle unexpected failures and restore normal operations. By measuring these parameters, teams can identify weaknesses in their failover strategies and optimize recovery processes.
- Failover Success Rate: Measure the effectiveness of automated traffic rerouting mechanisms.
- Self-Healing Mechanisms: Observe how well auto-scaling and self-repair mechanisms function.
- Data Consistency: Ensure no data loss or corruption occurs.
- Queue Length & Backlog: Monitor message queue health to detect processing slowdowns.
User Experience Metrics
User experience is a critical aspect of any system, as failures can directly impact customer satisfaction and business reputation. Monitoring these metrics ensures that service disruptions are minimized and performance remains within acceptable limits from an end-user perspective.
- Application Response Time: Measure any noticeable delays from an end-user perspective.
- Error Perception Rate: Count the number of users affected by failures.
- Session Drop-Off Rate: Track if users abandon sessions due to degraded performance.
- Frontend Performance (Page Load Times & UI Responsiveness): Observe any significant UI slowness caused by backend failures.
Chaos Experiment-Specific Metrics
Certain failures introduced in chaos experiments require monitoring unique parameters that are specific to the nature of the disruption. These metrics help evaluate the system's ability to withstand various types of injected faults.
- CPU Throttling or Memory Starvation Effects: Evaluate how the system behaves under constrained resources.
- Network Partitioning Impact: Analyze changes in network latency and packet loss.
- Database Failure Recovery Time: Measure how quickly database-related failures are mitigated.
- Container/Pod Restart Rate: Monitor Kubernetes/Docker container restarts to detect instability.
Chaos Engineering Experiment Template
|
Section |
Details |
|
Experiment Name |
|
|
Date |
|
|
Experiment Name |
|
|
Date |
|
|
Experiment Owner |
|
|
Target System/Service |
|
|
Experiment Hypothesis |
(e.g., “If the database fails, the system should recover within 10 seconds without data loss.”) |
|
Type of Failure |
(e.g., Network latency, CPU stress, database failure) |
|
Injection Method |
(e.g., Chaos Monkey, Gremlin, manual script, Kubernetes Fault Injection) |
|
Duration of Injection |
(e.g., 10 minutes) |
|
Blast Radius |
Which components/services are affected?) |
|
Rollback Strategy |
(How will you revert the failure if necessary?) |
|
System Performance Metrics |
(e.g., Response time, throughput, error rate) |
|
Availability & Reliability Metrics |
(e.g., MTTR, service uptime, failover success rate) |
|
User Experience Metrics |
(e.g., UI responsiveness, session drop-off rate) |
|
Chaos-Specific Metrics |
(e.g., CPU/memory spikes, container restarts) |
|
Pre-Experiment Baseline Metrics |
|
|
During Experiment Metrics |
|
|
Post-Experiment Recovery Metrics |
|
|
Unexpected Findings |
|
|
Conclusion & Learnings |
Did the system behave as expected? Did the failure propagate beyond the expected blast radius? What improvements are needed? |
|
Next Steps |
(e.g., Add automated failover, increase resource limits, improve monitoring) |
Conclusion
By systematically measuring key parameters and documenting chaos experiments, teams can proactively identify weaknesses in their system and improve overall resilience. Chaos engineering is not just about breaking things—it is a disciplined approach to uncovering hidden vulnerabilities and strengthening system reliability.
Through well-structured experiments, teams can gain insights into how their systems behave under real-world failure conditions, enabling them to develop better failover mechanisms, enhance monitoring strategies, and optimize recovery processes. Additionally, quantifiable data gathered from these experiments help teams make informed decisions about infrastructure improvements and risk mitigation strategies.
Continuous iteration and refinement of chaos engineering experiments ensure that systems remain robust against evolving failure scenarios. By embracing chaos as a proactive strategy rather than a reactive necessity, organizations can build confidence in their ability to maintain service reliability, even in the face of unexpected disruptions. Ultimately, this leads to a more resilient, scalable, and fault-tolerant system that enhances both operational stability and user experience.
References
- Basiri, A., van der Meulen, M. J. P., & Tamburri, D. A. (2022). "Chaos Engineering: A Systematic Literature Review". ACM Computing Surveys, 55(8), 1-38.
- Basiri, A., et al. (2019). "Chaos Engineering: Early Research and Future Directions". IEEE Software, 36(3), 35-41.
- Gremlin Inc. (2021). "Chaos Engineering: System Resilience Through Failure Injection". Retrieved from https://www.gremlin.com
- Netflix Engineering Blog. (2015). "Chaos Engineering Upgraded". Retrieved from https://netflixtechblog.com/chaos-engineering-upgraded-878d341f15fa
- Sharma, V., et al. (2017). "Performance and Resilience Testing Using Chaos Engineering". Proceedings of IEEE ICSE 2017, 12(1), 20-35.
- Adkins, H., et al. (2012). "Site Reliability Engineering: How Google Runs Production Systems". O'Reilly Media.
- Krishnan, S., & Baskaran, R. (2020). "Resilient Microservices Architecture Using Chaos Engineering". Springer Computing, 42(4), 23-41.
- Colt, G., & Fitzpatrick, J. (2020). "Modern Chaos Engineering: Observability and Fault Injection Strategies". Packt Publishing.
- Abbasi, A., et al. (2019). "Failure Recovery and System Performance Metrics in Cloud Environments". Journal of Cloud Computing, 8(1), 33-50.
- Taleb, N. N. (2012). "Antifragile: Things That Gain from Disorder". Random House.
Opinions expressed by DZone contributors are their own.
Comments