Modernizing Chaos Engineering: The Shift From Traditional to Event-Driven
Event-driven chaos engineering modernizes resilience testing by injecting failures based on real-time signals and system events.
Join the DZone community and get the full member experience.
Join For FreeImagine you're a car manufacturer. Traditionally, you schedule crash tests every few months using standard scenarios — front impact, side impact, and rollover. These tests are helpful, but they don’t guarantee how the car will perform with actual drivers, under real conditions, during unexpected events like icy roads or sudden brake failures.
Now imagine that instead of static crash tests, your vehicles have smart sensors that simulate critical failures at the moment drivers make changes, like switching to sport mode, engaging cruise control, or driving in a snowstorm. These real-time, event-triggered safety checks provide far more relevant insights, helping you design safer cars for real-world situations.
That’s the shift from traditional chaos engineering to event-driven chaos engineering: moving from planned, periodic assessments to intelligent, automated experiments tied to real system events — like deployments, scaling, or spikes in traffic — to ensure your systems remain resilient where and when it matters most.
Traditional Chaos Engineering: The Classic Approach
Traditional chaos engineering relies on predefined fault injection scenarios executed at scheduled times or during testing windows. Traditional chaos engineering injects randomness or failure into a system, usually in a controlled, (sometimes) periodic, and manually triggered fashion.
The focus is on steady-state validation, uncovering failure domains, and pre-emptively strengthening weak points — often in production, but sometimes in staging. These experiments are:
- Manually triggered or cron-based
- Pre-planned and scoped
- Monitored through dashboards and logs
- Executed using tools like Gremlin, Chaos Monkey, or LitmusChaos in batch mode
An example of traditional chaos engineering is injecting CPU stress into a microservice every Wednesday at 2 PM to observe behaviour under pressure.
Pros
- Simple to implement and understand
- Great for baselining resilience
- Useful during controlled tests and game days
Limitations
- Static and not context-aware
- Risk of missing real-time edge cases
- Hard to integrate into dynamic production systems
Event-Driven Chaos Engineering: Adaptive and Real-Time
Modern architectures — containerised micro-services, event streaming platforms, and serverless functions — live and die by events. Event-driven chaos engineering responds to real-time events and system states to trigger chaos experiments dynamically. It aligns with observability signals, CI/CD pipelines, and incident triggers for more context-aware fault injection.
Why Event-Driven?
- Contextual relevance: Instead of generic breakage, failures are more reflective of production realities, catching configuration drift, integration failures, and regressions tied to actual changes.
- Automated, continuous resilience: Event-driven chaos integrates directly with CI/CD pipelines and cloud-native workflows, providing constant, meaningful feedback loops.
- Faster detection, faster recovery: Organizations can validate sub-second recovery—the modern gold standard — before customers are truly at risk.
Example Triggers
- Pod restarts > 5 in a minute
- Latency spike over 500 ms
- Deployment of a new version
- K8s events like
CrashLoopBackOff
How It Works
- Observe: Monitor system metrics, events, and logs in real time.
- Trigger: When certain conditions are met, chaos is injected automatically.
- Analyze: Collect data to determine system response and resilience.
- Heal: Automatically roll back or alert teams if thresholds are exceeded.
Tools like event-driven Ansible, LitmusChaos with event watchers, and OpenChaos support such automation.
Challenges
- More complex to configure
- Requires strong observability foundations
- Needs guardrails to avoid cascading failures
Traditional vs. Event-Driven: Key Differences
|
Aspect
|
Traditional
|
Event-Driven
|
|---|---|---|
|
Trigger Mechanism |
Scheduled or manually triggered |
Automatically initiated by real system events (e.g., deployments, scaling, traffic spikes) |
|
Testing Approach |
Periodic, often at arbitrary times |
Contextual - aligns chaos with meaningful changes or risks in the system |
|
Environment |
Production or production-like; sometimes staging |
Primarily production or production-like; tightly coupled to operational events |
|
Objective |
Explore general system resilience; find hidden failures over time |
Validate system resilience in direct response to specific, real-time events and changes |
|
Blast Radius Control |
Often broader or less adaptive |
Typically fine-grained and closely scoped to affected components |
|
Automation |
May require manual intervention or periodic scripts |
Highly automated, integrated into CI/CD and operational workflows |
|
Relevance to Real-world Failures |
Can be generic, not always mapping to true production incidents |
Directly reflects production scenarios, maximizing the likelihood of uncovering emergent risks |
|
Feedback Loop |
Post-experiment analysis, slower iteration |
Immediate insights support faster remediation and continuous improvement |
How Event-Driven Chaos Engineering Enhances System Resilience
Event-driven approaches dynamically trigger failure scenarios based on actual system events, making resilience testing more realistic, relevant, and timely.
Here’s a breakdown of how it contributes to stronger, more resilient systems:
- Real-time reaction to system changes
- More relevant scenarios, simulating real production conditions.
- Reduces the gap between test conditions and real-world failures.
- Improves system learning and self-healing
- Ensures that resilience features are actually working as expected.
- Builds trust in automated recovery processes.
- Reduces blast radius via targeted injection
- Minimizes the risk of system-wide outages
- Enables safe experimentation even in production environments
- Faster feedback loop for DevOps and SRE
- Speeds up incident detection and response time
- Shifts resilience testing left into the CI/CD lifecycle
- Enhances observability and adaptive testing
- Increases the system’s ability to detect, diagnose, and respond to issues
- Turns observability into actionable resilience testing triggers
- Supports chaos-as-code and policy-driven resilience
- Codifies resilience strategies as version-controlled artifacts
- Encourages governed, repeatable resilience testing
Event-Driven Chaos Engineering Architecture
Depending on the cloud provider, different services can be leveraged to implement event-driven chaos engineering. Below is an example architecture designed for IBM Cloud.
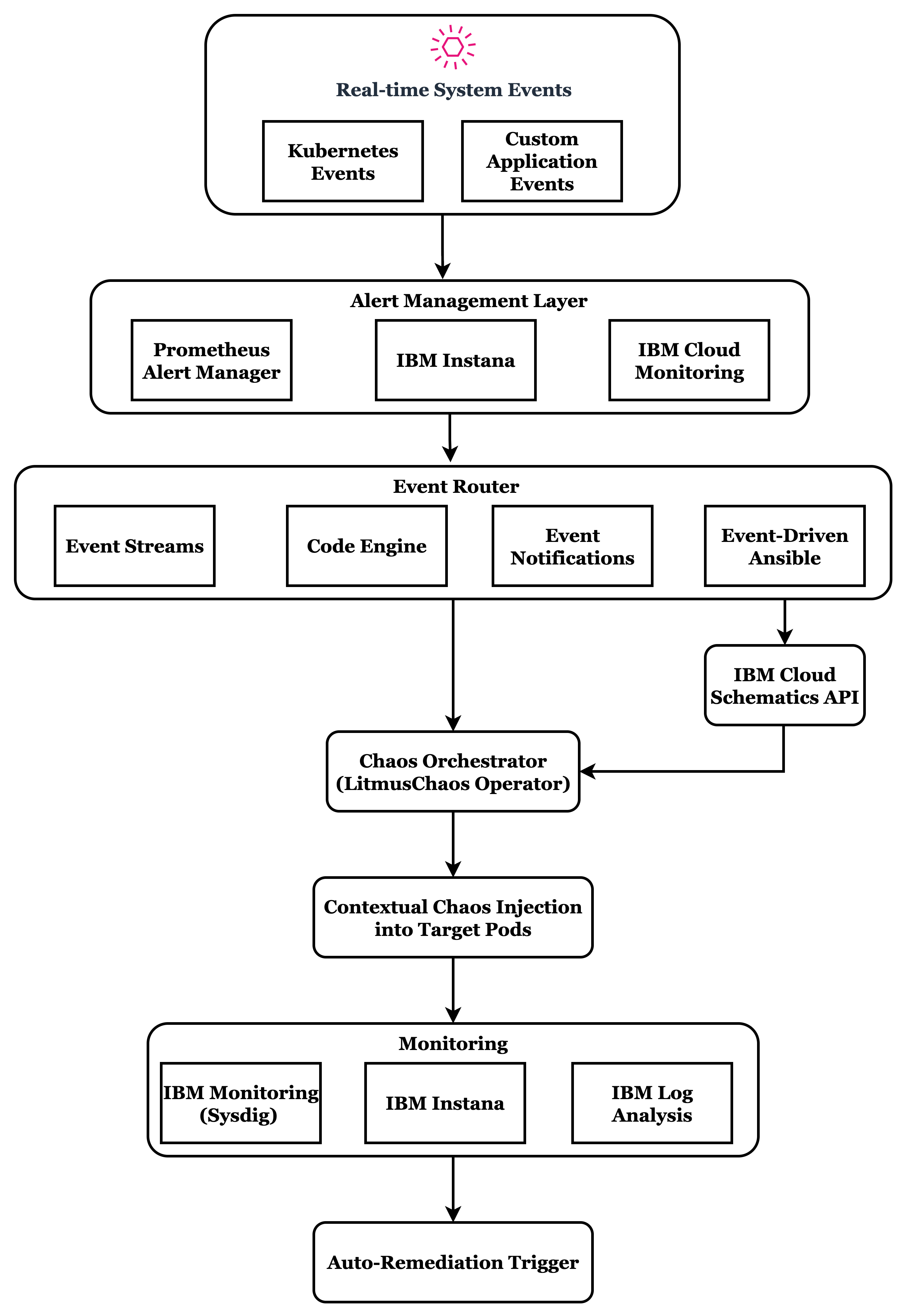
Event-Driven Chaos in Production or Stage?
Event-driven chaos engineering can be done in both staging and production, but with different levels of risk tolerance, controls, and objectives:
In Staging Environments
Purpose
- To simulate failures safely before they reach production
- To test the resilience of new features, service deployments, or architectural changes
Advantages
- Low risk to users or revenue
- Allows aggressive fault scenarios
- Helps prepare SRE and DevOps teams for possible production incidents
In Production Environments
Purpose
- To validate real-world system resilience under live traffic
- To test auto-recovery, failovers, and alerting mechanisms
Prerequisites
- Strong observability (metrics, traces, logs)
- Circuit breakers, retries, and rate limiting are in place
- Blast radius control (e.g., targeting only a small percentage of pods or users)
Approaches
- Scoped experiments (e.g., targeting one region or AZ)
- Canary or shadow deployments combined with chaos triggers
- Time-bound experiments with rollback policies
Fine-Grained Controlled Chaos Engineering Using Feature Flags
Feature flags play a crucial role in chaos engineering, especially as teams adopt progressive delivery, event-driven chaos, and auto-remediation. They provide fine-grained control, safe experimentation, and rollback mechanisms that align perfectly with chaos goals: resilience without fear.
Here’s how feature flags contribute to effective chaos engineering practice:
- Controlled chaos activation – Enables gradual rollout and rollback of chaos scenarios.
- Dynamic scope control (blast radius) – Prevents uncontrolled experiments in sensitive systems. Dynamically limit which services are targeted, how long chaos runs, what type of failure is injected, etc.
- Progressive delivery + chaos –Test resilience of new versions without affecting all users.
- Safe auto-remediation – Prevents auto-recovery from interfering with intentional chaos.
- Experiment lifecycle management – Gives developers, SREs, or even product teams runtime control. Use flags to start/stop experiments from a dashboard, integrate with A/B testing, enable chaos only during SLO burn rate, etc.
Checklist for Safe Production-Based Chaos Engineering
Pre-Experiment Readiness
- Define clear objectives: What are you validating (e.g., failover, autoscaling, alerting)?
- Establish a baseline: Know normal system behaviour (latency, throughput, availability).
- Set a blast radius: Limit impact to specific pods/nodes/regions, a subset of users, or a low % of traffic.
- Stakeholder alignment: Inform SREs, product owners, and incident response teams.
- Ensure pre-chaos alerting is in place: Alerts must notify the appropriate teams when triggering the experiment to detect unintended impact early and confirm the system is working as intended.
Observability and Monitoring
- Real-time metrics and dashboards: Tools like Prometheus, Grafana, IBM Instana
- Distributed tracing: Enables root-cause analysis post-experiment
- Log aggregation: Centralized logs for impacted services
- Alerting: Alerts tied to SLO breaches (e.g., CPU > 90%, error rate > threshold)
Guardrails and Safety Mechanisms
- Circuit breakers and rate limiters: To protect downstream systems
- Auto-healing configured: Ensure Kubernetes, auto-scaling groups, or workflows can self-recover
- Rollback mechanisms in place: Feature flags, canary deployment, or blue-green rollback support
- Manual abort option: Chaos controller should support stopping an experiment in real time
Experiment Control
- Event trigger policies: Chaos triggers only under defined conditions (e.g., deployment event, CPU > 80%)
- Timebox the experiment: Duration of the test is limited (e.g., 5–10 mins)
- Audit logs enabled: Track who triggered what chaos and when
Post-Experiment Review
- Analyze the impact: Did the system degrade gracefully or fail catastrophically?
- Validate alerts and auto-heal: Did the alerting system notify the right team? Did the service recover?
- Document learnings: Share incident timeline, mitigation steps, and new action items
- Update runbooks/playbooks: Incorporate new failure modes or detection patterns
Optional Enhancements
- Simulate real user load: Use tools like k6, Locust, or JMeter during the chaos test.
- Feature flag isolation: Isolate test features from production traffic using IBM Cloud App Configuration or LaunchDarkly.
- Run in shadow mode first: Run chaos logic, but don’t actually inject failures — observe what would happen.
Best Practices for Event-Driven Chaos Engineering
The following are the best practices for event-driven chaos engineering to ensure it’s safe, effective, and improves system resilience without unintended disruptions:
- Start small and controlled: Begin with non-critical services or lower environments (staging/dev).
- Integrate with real-time observability: Use tools like Prometheus, Grafana, Instana, or OpenTelemetry.
- Define clear triggering conditions: Set precise event-based rules for initiating chaos (e.g., CPU > 85% for 5 mins, pod crash loops).
- Reproduce realistic failures: Use fault types that match historical incidents or common failure patterns.
- Implement guardrails and safety nets: Ensure easy manual rollback or shutdown of chaos injection.
- Close the feedback loop: Feed findings back into runbooks, incident response playbooks, and SRE practices.
- Codify experiments and triggers: Use Chaos-as-Code tools (like LitmusChaos, ChaosMesh, or custom YAML specs).
- Measure and report resilience improvements: Map results to SLOs, error budgets, and MTTR improvements.
- Foster a culture of controlled failure: Educate teams on the purpose of chaos. Treat failures during chaos as insights, not blame points.
Conclusion: Adapting Chaos to a Dynamic World
As systems become increasingly distributed, automated, and event-driven, our approach to resilience must evolve as well. Traditional chaos engineering has laid the groundwork for uncovering weaknesses, but it often falls short in capturing the real-time complexity of today’s environments.
Event-driven chaos engineering modernizes this discipline by making resilience testing adaptive, intelligent, and continuous. By tying fault injection to actual system events, organizations can validate their self-healing capabilities, detect weak links early, and respond faster to unknowns, without waiting for failure to strike first.
Opinions expressed by DZone contributors are their own.
Comments