Metadata, Not Data Volume, Is the Real Bottleneck in Modern Data Lakes
In Apache Iceberg data lakes, growing snapshots and manifests often make metadata resolution — not data scanning — the primary performance bottleneck.
Join the DZone community and get the full member experience.
Join For FreeFor more than a decade, data engineering best practices have revolved around a single assumption: data volume is the primary scalability challenge.
We optimized Parquet sizes, tuned partitioning strategies, compressed aggressively, and scaled compute to handle terabytes and petabytes of data. As long as queries scanned fewer files and clusters had enough memory, performance generally improved.
But in modern data lakes built on Apache Iceberg, AWS Glue, Spark, and Athena, that assumption is no longer universally true.
Today, an increasing number of production performance failures occur before a single data file is read.
The real bottleneck has shifted.
It is no longer data volume.
It is metadata.
A Real-World Symptom Pattern
This issue rarely shows up as a single, obvious failure. Instead, it emerges as a pattern of small, compounding symptoms that are difficult to diagnose in isolation. Queries that once ran quickly begin to stall. Teams scale clusters, increase memory, and retry jobs, only to see inconsistent or marginal improvements. Over time, confidence in the platform erodes because performance becomes unpredictable rather than consistently slow.
In practice, this pattern looks like the following:
- Spark jobs take minutes just to reach the first stage
- Athena queries spend most of their runtime in "planning"
- Explain plans become enormous and slow to render
- Drivers fail with out-of-memory errors during query analysis
- Scaling executors or memory has little to no impact
What makes this especially frustrating is that the datasets involved are often modest in size — sometimes only a few hundred gigabytes.
From a traditional data lake perspective, nothing appears wrong.
From a metadata perspective, everything is.
How Apache Iceberg Changes the Performance Equation
Apache Iceberg fundamentally improved data lake reliability by introducing:
- ACID transactions on object storage
- Snapshot isolation and time travel
- Schema and partition evolution without rewrites
However, these capabilities are implemented through a rich metadata layer that tracks the full history and structure of a table.
An Iceberg table consists of far more than Parquet files in S3. It includes:
- Snapshots representing table states
- Manifest lists referencing manifests
- Manifests describing data files
- Partition specifications
- Schema versions
- Table-level properties and statistics
Every query engine must resolve this metadata graph before it can decide which data files to read.
As tables evolve, metadata grows independently — and often faster — than the data itself.
Where the Bottleneck Actually Lives
The following simplified architecture highlights where many queries fail:
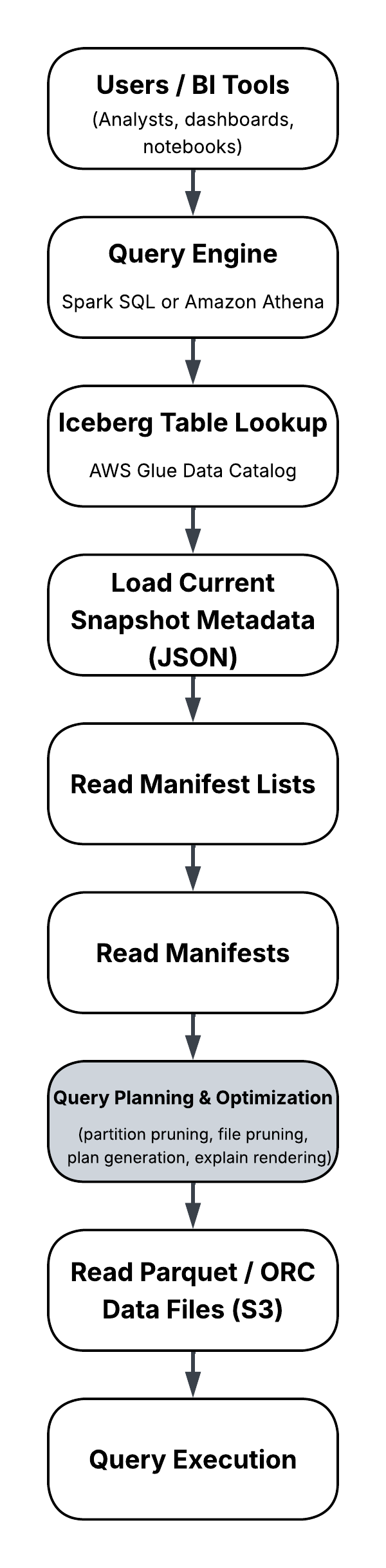
Before any Parquet files are read, Spark or Athena must resolve snapshots and manifests during query planning, which often dominates latency and becomes the primary failure point.
Critical insight:
In many real-world failures, execution never reaches the S3 data files. The query fails or stalls entirely during metadata resolution and planning.
Why Metadata Explodes in Production
Metadata growth is rarely accidental. It emerges naturally from reasonable architectural decisions:
1. Frequent Writes and Micro-Batching
Streaming pipelines and near-real-time ingestion create snapshots continuously, even when only small amounts of data are added.
2. Over-Partitioning
Partitioning by date, hour, region, channel, and device multiplies manifest count and planning complexity.
3. Schema Evolution
Each schema change introduces new schema versions that planners must reconcile.
4. Snapshot Retention Without Cleanup
Iceberg does not automatically remove old snapshots or manifests unless explicitly instructed to do so.
None of these are mistakes. Together, they create metadata accumulation over time.
Engine-Specific Behavior: Spark vs. Athena
Understanding how engines behave makes the issue clearer.
Spark
Spark performs extensive logical and physical planning on the driver. Large metadata graphs increase:
- Driver memory pressure
- Plan string generation cost
- Planning latency
In extreme cases, Spark drivers fail before execution begins, even when executors are underutilized.
Athena
Athena is more resilient but still impacted. Query planning time increases significantly as:
- Manifest counts grow
- Snapshot histories deepen
This often manifests as long "queued" or "planning" phases, even for simple queries.
In both engines, metadata — not data — dominates the critical path.
Inspecting Metadata Growth
Iceberg exposes its metadata as queryable system tables.
Snapshot Growth
SELECT
snapshot_id,
committed_at,
operation,
summary['added-data-files'] AS added_files,
summary['total-data-files'] AS total_files
FROM iceberg_demo.customer_behavior.snapshots
ORDER BY committed_at DESC;In multiple enterprise environments, it is common to find thousands of snapshots for datasets well under 1 TB, driven purely by ingestion frequency.
Manifest Count
SELECT
COUNT(*) AS manifest_count,
SUM(added_files_count) AS total_files
FROM iceberg_demo.customer_behavior.manifests;Each manifest must be read, parsed, and evaluated during query planning. As counts rise, planning time grows non-linearly.
Why More Compute Doesn’t Help
When queries slow down or fail unexpectedly, the most common reaction is to scale infrastructure. Teams increase Spark driver memory, add more executors, or provision larger clusters under the assumption that the workload is compute-bound.
In metadata-heavy Iceberg tables, this instinct often fails.
The reason is that metadata resolution is not a distributed problem in the same way that data processing is. Much of the work happens during query planning, which is frequently constrained to a single driver or coordinator node. Loading manifests, resolving snapshots, reconciling schema versions, and generating execution plans all place pressure on CPU and memory in places that additional executors cannot relieve.
As a result, teams observe a frustrating pattern: execution stages remain fast once they begin, but jobs stall or fail long before reaching them. Scaling downstream compute has little impact because the planner itself is already overwhelmed.
If the planner cannot resolve metadata efficiently, no amount of additional compute will help.
Fixing the Real Problem: Metadata Hygiene
Effective optimization focuses on metadata directly.
Expire Old Snapshots
spark.sql("""
CALL system.expire_snapshots(
table => 'iceberg_demo.customer_behavior',
older_than => TIMESTAMP '2025-01-01 00:00:00',
retain_last => 5
)
""")This removes obsolete snapshots that add planning overhead without business value.
Rewrite Manifests
spark.sql("""
CALL system.rewrite_manifests(
table => 'iceberg_demo.customer_behavior'
)
""")This consolidates fragmented manifests into fewer, larger ones, dramatically reducing planning cost.
Measured Impact in Production
| Metric | Before | After |
|---|---|---|
| Snapshots | ~3,800 | ~120 |
| Manifests | ~2,400 | ~120 |
| Query planning time | ~90 seconds | ~20 seconds |
| Execution time | Unchanged | Unchanged |
The data did not change.
Only metadata did.
Metadata Is Now an Operational Concern
For years, the "small file problem" dominated data lake discussions. Many teams have solved it through compaction and better writers.
Yet performance issues persist. That’s because small files were a data problem.
Metadata is a system problem.
Unmanaged metadata introduces:
- Unpredictable query latency
- Planner instability
- Increased failure rates
- Higher cloud costs from repeated retries
At scale, metadata becomes part of the platform's operational surface area.
Practical Operational Checklist
Teams operating Iceberg at scale should routinely:
- Monitor snapshot and manifest counts
- Schedule snapshot expiration jobs
- Run manifest rewrite jobs after heavy ingestion periods
- Review partitioning strategies annually
- Treat metadata growth as a first-class SLO
Ignoring metadata is no longer an option.
Connecting Back to Intelligence Lakes
In a previous article, I introduced the concept of Intelligence Lakes, where metadata is enriched using generative AI to provide semantic understanding, governance, and discovery.
That vision remains critical.
But intelligent metadata must also be manageable metadata.
AI-enriched catalogs, embeddings, and semantic tags all add value — and all rely on a healthy metadata foundation. Without disciplined metadata hygiene, intelligence layers risk amplifying an already fragile system.
Conclusion
If your data lake feels slow, brittle, or unpredictable despite reasonable data volumes, the issue may not be your data at all.
It is likely your metadata.
Modern data platforms succeed not only by storing more data, but by managing metadata as an operational asset. Teams that recognize this shift build systems that scale gracefully. Teams that don’t end up fighting invisible bottlenecks that no amount of compute can fix.
In modern data lakes, metadata is no longer just descriptive.
It is operational infrastructure.
Opinions expressed by DZone contributors are their own.
Comments