From Solr Master-Slave to the (Solr)Cloud
If you're moving to Solr's distributed search system, there's a lot to keep in mind ranging from indexing differences to testing procedures to keeping ZooKeeper working.
Join the DZone community and get the full member experience.
Join For FreeNowadays, there are more and more organizations searching for fault-tolerant and highly available solutions for various parts of their infrastructure, including search, which evolved from merely a “nice to have” feature to the first-class citizen and a “must have” element.
Apache Solr is a mature search solution that has been available for over a decade now. Its traditional master-slave deployment has been available since 2006, while the fully distributed deployment known as SolrCloud has been available for only a few years now. Thus, naturally, many organizations are in the process of migrating from Solr master-slave to SolrCloud, or are at least thinking about the move. In this article, we will give you an overview of what’s needed to be done for the migration to SolrCloud to be as smooth as it can be.
Step One: Hardware
The first thing that you need to think about when migrating from an old master-slave environment is the hardware. You may wonder why the hardware should be different from what you have right now. There are a few reasons:
- You want to keep the current production while migrating to the new solution to avoid service interruption. Doing that will also let you test the new SolrCloud cluster and rollback to the old Solr master-slave if something goes awry. It is also a good idea to run various performance tests before going to production, so having a separate hardware for the SolrCloud cluster may be a very good idea if you can afford it.
- You will want to prepare the infrastructure for your new search setup so that it can handle the load for the next N months, or even a few years, so you don’t have to change the architecture or infrastructure again in the near future.
- If your data is changing rapidly, with SolrCloud, you will index the data to all nodes at the same time, not only to the master servers. This may require more resources on the nodes. More disk I/O will be needed. Because of constant data indexing, data will also be indexed on the replicas, so you need to account for that.
- If you plan to have replicas, keep in mind they will do the same operations as the leader shards, so having more replicas means not only more storage requirements, but also more resources like CPU and memory.
- Finally, you will need ZooKeeper ensemble to be working. SolrCloud uses ZooKeeper to make itself fully configurable. We talk about this in the next point.
Keep all of the above in mind when choosing your final hardware. If you don’t, you’ll run into situations where you will need to adjust your provisioned machines in the near future, and that requires the thing we tend to have the least of – time.
Step Two: Solr Setup
Setting up SolrCloud is a bit different than setting up Solr master-slave architecture. First of all, you will need a working Apache ZooKeeper ensemble. SolrCloud uses ZooKeeper to store collections configuration, collections state, keeping track of nodes, for leader election, and so on. In general, ZooKeeper is critical for SolrCloud — it’s like a heart of a SolrCloud cluster. When Zookeeper is not available, no indexing operation will be successful, some queries may b—e – up to a point, where something happens to the cluster.
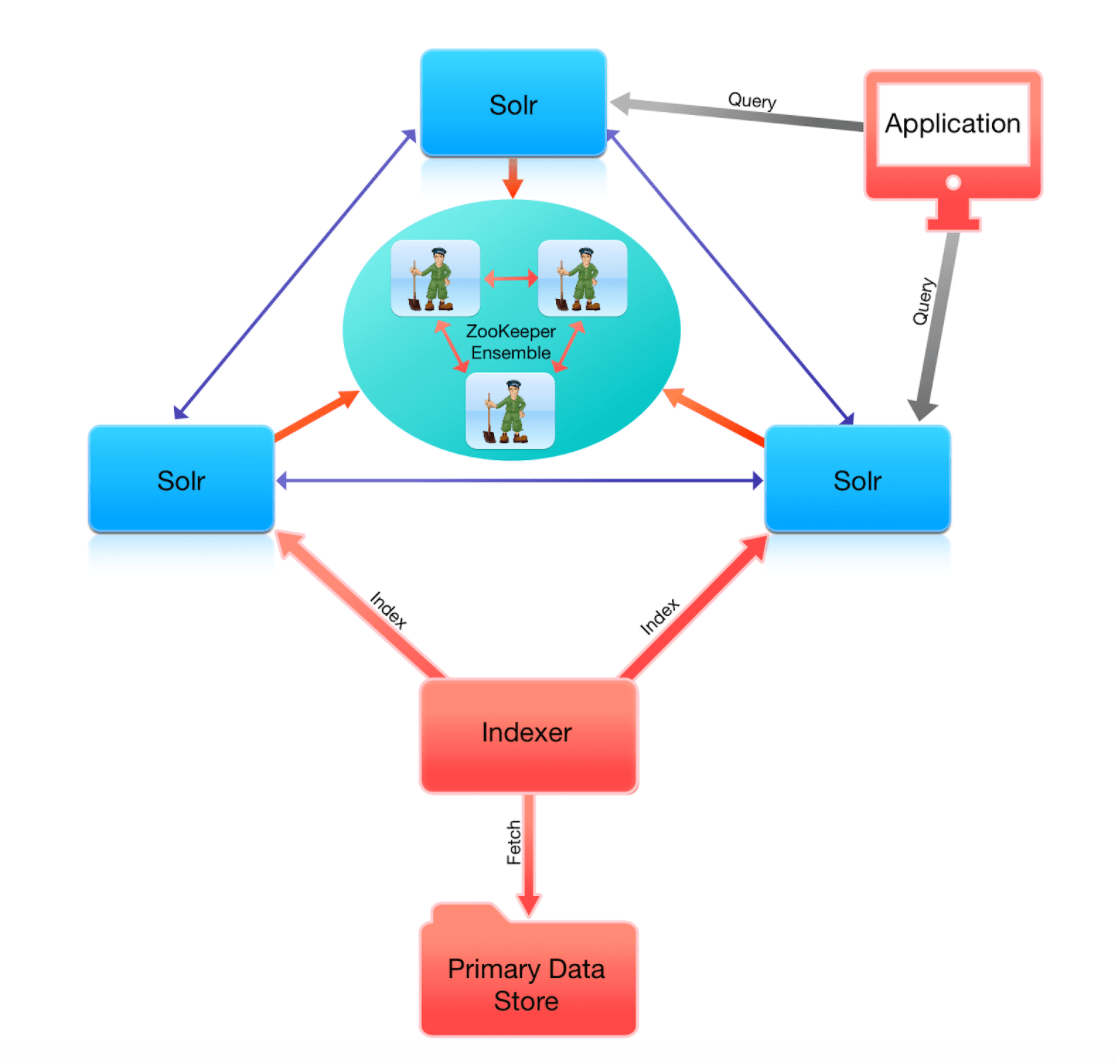
In order to set up a highly available and fault-tolerant ZooKeeper ensemble, you need at least three instances. That allows for a single instance of ZooKeeper to go down and have the ensemble running. The basic idea is that you need to have at least 50% + 1 nodes to be operational in ZooKeeper ensemble for it to be running properly. So when you have three nodes, you need at least two, and when you have five nodes, you need at least three, and so on.
It is also a very good idea to point all SolrCloud instances to all ZooKeeper nodes, not just one of them. That will mean that the ZK_HOST property in your solr.in.sh will look something like this:
ZK_HOST=10.0.0.1:2181,10.0.0.2:2181,10.0.0.3:2181Of course, you may wonder why we need a standalone ZooKeeper instance when SolrCloud provides an embedded ZooKeeper version — when run with -c switch without ZK_HOST specified (or without -z switch). At the time of this writing, the embedded ZooKeeper has not been designed for production deployments in mind. One of the reasons is that it can’t be used in a distributed mode, and having a single Zookeeper instance running inside the same JVM as SolrCloud node is asking for trouble. Imagine JVM going out of memory or SolrCloud node being restarted — the embedded ZooKeeper would go down as well, which means that the cluster would lose its heart for some time. This is something we want to avoid.
Step Three: Migrating the Configuration
The next step in your migration from Solr master-slave to SolrCloud will be preparing the configuration files. There are at least two files – the schema.xml and solrconfig.xml that you need to take care of.
Note that there can also be additional files that might be required or may need to be removed, depending on the configuration changes. We think that removing all the unneeded configuration files is a good idea because that avoids confusion in the future.
One big thing to remember — if you are migrating to Solr 6, Java 8 is a must. Since support for Java 7 has ended, you should use a later version of Java everywhere.
What About Schema.xml?
Depending on your current setup, you should check which field types were removed, which have been deprecated, what filters are no longer available, and so on.
The general idea we suggest is that you start with the schema.xml file from the new Solr version, the one that you will be migrating to. So if you plan to migrate to Solr 6.3, take the example schema.xml file from there and adjust it to your needs.
Here are a few things to keep in mind:
- Old numeric fields have been long gone, so field types like solr.IntField or solr.FloatField should be replaced by solr.TrieIntField and solr.TrieFloatField.
- If you want to search on numeric fields, you should use types like tint, tlong and so on — the ones with the higher precisionStep property.
- Use doc values (docValues="true") for non-analyzed and for numeric fields on which you plan on faceting or sorting. This will reduce the memory footprint and let the JVM garbage collector do less work at the cost of a slightly larger index.
- Once again, rethink what fields you need to store and which fields should be indexed. Maybe you can remove some fields from your index so that the index can be smaller.
- Keep your schema.xml as small as possible to avoid upgrade issues in the future. You will probably upgrade and switch between major Solr versions in the future, so it is worth spending the time on making the schema.xml as clean as possible now. That will minimize headaches in the future.
- Starting from Solr 4.8, the <fields> and <types> sections are deprecated. The definition of types and fields should go directly to the schema.xml file allowing mixing of sections like field definition, type definition, copy fields and dynamic fields together.
What About Solrconfig.xml?
Again, similar to schema.xml file, we will need to update the solrconfig.xml file. It is a very good idea to start from scratch, from a minimal example, and go from there, extending the configuration to match your needs.
Keep in mind that when migrating from Solr master-slave to SolrCloud, the configuration will be different. First of all, all the nodes in the cluster will have the same configuration, no more separate solrconfig.xml files. No more pointing the /replication handler to the master manually, Solr will do everything for us.
Here are a few things to keep in mind:
- Solr distribution doesn’t ship a separate WAR file anymore.
- Starting from Solr 4.0, the old <indexDefaults> and <mainIndex> sections are deprecated and replaced with a single <indexConfig> section.
- Remember that the update request parameter to choose the Update Request Processor Chain has been renamed from update.processor to update.chain.
- Collections should be created only using the Collections API.
- New bin/solr script has been added, allowing various operations with the Solr server, like starting, stopping, or uploading data to ZooKeeper.
- The checkIntegrityAtMerge option has been removed from solrconfig.xml and is now done automatically.
- Admin handlers are deprecated and handlers like /get, /replication and all */admin/** are automatically added.
- The <nrtMode> configuration option has been removed.
- The DefaultSimilarityFactory has been renamed to ClassicSimilarityFactory, and the new default similarity for Solr 6 is BM25SimilarityFactory.
- You should properly set the type of data when sending data to Solr using the content-type HTTP header.
- The <mergePolicy> configuration element is deprecated and is replaced by <mergePolicyFactor> configuration option. The <mergeFactor> and <maxMergeDocs> elements were also deprecated.
- You should migrate your update handlers configuration according to the example configuration provided with Solr package.
Of course, please remember that these is not the full list of changes that have been in Solr recently and the best thing to do is start from scratch and create a new configuration or, if you really want to be thorough and understand all changes, go through all the changes listed in Solr release notes, which may not be a very easy and pleasant task
Step Four: Data Migration
In most cases, when you migrate data from an old Solr version to a new one, like upgrading your SolrCloud between major versions, it is possible to avoid data re-indexing. However, in this case, when we migrate from the Solr master-slave environment to SolrCloud, it is tricky and usually not worth it.
There are multiple things you should think about when handling data migration or thinking whether you should go for one. For example, just installing and trying to run SolrCloud on top of existing Solr master-slave installation is not very straightforward — you will need to manually upload data to proper directories. You may not be able to do that if you are migrating from a very old Solr — like from Solr 3 to Solr 5 or from Solr 3 or 4 to Solr 6. Running a multi-master Solr master-slave installation in most cases means a no-go for migration and requires re-indexing. Finally, if you would like to be able to roll back in case something goes terribly wrong – you may want to re-index and use a separate set of servers, instead of going for the same hardware.
What Could Go Wrong?
Well, pretty much everything. We suggest testing, testing, and testing. And after you are done with tests, go through the configuration, index your data and test once again. If you have a test version of your applications that use Solr, test them with SolrCloud. Remember that there are still certain features that do not work in general SolrCloud deployments — like grouping by function queries (unless you have all the data from the given group in a single shard). That’s why testing is so important.
And the last thing — performance. Keep in mind that if you were running a Solr master-slave configuration the SolrCloud, performance may be slightly different. With SolrCloud, you are running a fully distributed environment, and that doesn’t come for free. You may have replicas, all your Solr nodes may now be indexing data, and, finally, the queries may hit multiple shards, so there will be more steps needed to gather the data. So basically, do the homework and do the tests just to be sure that everything works and there is nothing or close to nothing that may result in a nasty surprise.
Published at DZone with permission of Rafał Kuć. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments