Scaling ML Experiments: The High-Throughput Playbook
Learn why A/B testing is vital for product decisions and how overlapping experiments boost speed, reduce bias, and scale learning across teams.
Join the DZone community and get the full member experience.
Join For FreeFrom Guesswork to Growth: Why A/B Testing Is Non-Negotiable
Every product decision is a bet under uncertainty. A/B testing turns those bets into measurable, causal learning.
By randomly assigning users to control versus treatment, you create two groups that are — on average — identical. Any difference in conversion, retention, revenue, or latency can be attributed to the change, not to seasonality, campaigns, or shifting user mix. Randomization gives you a credible counterfactual.
The Payoff: What Teams Actually Gain
- Confidence, not consensus. Decisions anchor on causal evidence, not the loudest opinion.
- Faster iteration. Ship small changes, measure impact, keep what works, revert what doesn’t.
- Built-in risk management. Guardrails and staged rollouts limit downside while you learn.
- Clear ROI focus. Metrics quantify business impact to prioritize the roadmap.
- A scientific rhythm. Hypothesis, test, learn, and repeat becomes the operating loop.
As organizations scale, the question evolves from “Can we test this?” to “How do we test everything?” — ranking models, retrieval, pricing, notifications, performance flags, and UI — in parallel. That’s where a more sophisticated approach is essential.
The Velocity Problem: Why You Need Overlapping Experiments
Running one experiment at a time throttles learning. High-traffic surfaces like your homepage or search results page sit underutilized while teams wait for a single test to reach significance. Roadmaps back up, and external factors like holidays skew results.
The solution is overlapping experimentation, where many teams learn in parallel on the same surface.
We’ve established why A/B testing is the decision contract and why velocity demands overlap. The next step is operational: how to run many experiments in parallel without breaking causal validity.
A Blueprint for Concurrent Experiments
A practical blueprint (in the spirit of Google’s overlapping infrastructure):
- Isolate with namespaces. Group experiments by domain (e.g., search, ads, checkout) to prevent cross-domain interference.
- Randomize by layer. Assign users orthogonally (independently) within layers such as ranking, ads, and UI. A user can be in one experiment per layer.
- Merge and prioritize at request time. Combine parameter writes from all active experiments; if multiple tests set the same key, a priority order determines the winner (per-parameter).
- Log the result. Persist the final effective parameter map and override reasons — this is the source of truth for analysis.
- Use mutual exclusion sparingly. Reserve “exclusion groups” for a few contention-prone entry points where running side-by-side is unacceptable.
Overlap boosts throughput — but it also creates conflict. Let’s define it precisely so we can neutralize it.
Untangling the Overlap: What Is a “Conflicting Experiment”?
A conflict is any interaction where concurrent treatments interfere, making at least one experiment’s estimate biased, diluted, or operationally risky:
- Parameter collisions: Two tests set the same key (e.g., ranking.max_results, ui.title_color) on the same request.
- Shared-surface constraints: Treatments compete for finite pixels, latency budgets, or ad slots on a high-reach surface/entry point.
- Trigger/eligibility interactions: Targeting/enrollment rules for one test influence who can enter another, breaking orthogonality.
- Upstream-to-downstream dependency: Upstream ranking shifts introduce interference in downstream measurements.
- Carryover effects: Earlier exposure persists and alters later behavior.
Conflicts aren’t failures — they’re design constraints your platform should handle systematically.
To reconcile throughput with causal validity, use these five patterns as standard guardrails.
Five Proven Ways to Resolve Conflicts
1. Domain and Namespace Partitioning
Think of namespaces as digital fences. This method splits your traffic into completely separate, non-overlapping universes based on product areas such as search, ads, or checkout. All randomization and parameters for a team live securely within their own namespace. It’s a simple mental model that often mirrors your company’s organizational chart, providing strong, clean isolation. The main drawback is its rigidity; it doesn’t solve conflicts within a single domain, and running site-wide experiments can be awkward.
2. Mutual-Exclusion Groups
This is the brute-force solution for guaranteed collisions. When you have two high-stakes tests that would clearly clash (like competing homepage redesigns), you can place them in a mutual-exclusion group. This creates a shared pool where any given user is assigned to at most one of the experiments. While this approach is statistically pristine and easy to reason about, it imposes a “throughput tax” by intentionally limiting concurrency. It requires manual curation and should be reserved for your biggest, most disruptive ideas.
3. Layered Allocation With Priority Rules (The Workhorse)
This is the key to achieving maximum concurrency. Inside a namespace, you organize experiments into ordered layers, such as:
1. Ranking → 2. Ads → 3. UI
Users are assigned to a variant independently in each layer. When a user qualifies for multiple tests that modify the same parameter, a simple priority rule kicks in: the higher layer always wins. This gives teams autonomy and allows priorities to change without re-randomizing users. The critical watch-out is that upstream changes can bias the results of lower-layer tests. You can mitigate this by logging the final “effective” parameter map for every request and using the higher-layer assignments as covariates during analysis.
4. Conditional Eligibility and Triggering
This method offers surgical control over who enters an experiment. Instead of randomizing everyone, you use explicit eligibility rules (based on attributes like location, device, or even membership in another test) and event-based triggers (like enrolling a user only after they fire an add_to_cart event). This approach is precise, auditable, and dynamic, making it perfect for enforcing business policies or targeting specific user journeys.
However, complex rules can easily introduce sampling bias, so they require strong governance and constant monitoring.
5. (Fractional) Factorial Designs
Instead of avoiding interactions, this advanced method measures them directly. By intentionally crossing variants from different experiments (e.g., in a 2x2 design), you can estimate the main effect of each change and their interaction effect — whether they have positive synergy or negative antagonism. This is incredibly powerful when a decision hinges on how features combine, like testing a new pricing model with a new page layout. The trade-off is complexity; factorial designs create more experimental cells and demand significantly more traffic to achieve statistical power.
We just defined overlap and the five resolution patterns. This is the operational blueprint that enforces them at runtime — so you get throughput without sacrificing causal validity.
Architecture View by Incorporating the Above Concepts
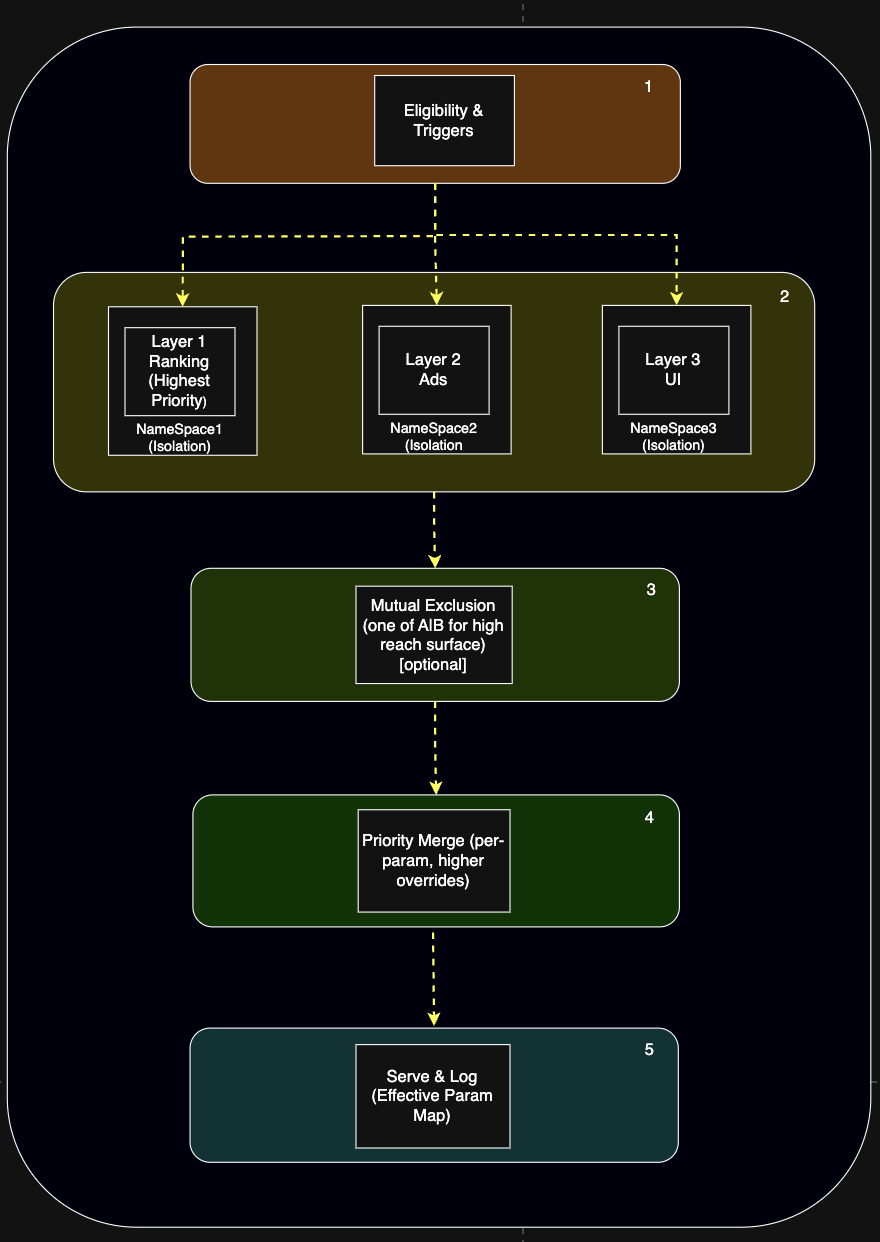
Here’s the high-level architecture, distilled and easy to scan. The system moves from broad isolation to fine-grained rules, so conflicts are handled predictably at each step.
1. Namespace Selection (Broad Isolation)
2. Mutual-Exclusion Checks (Safety Valve)
3. Eligibility and Triggers (Targeting)
4. Independent Per-Layer Assignment (Orthogonality)
5. Per-Parameter Priority Merge (Deterministic Resolution)
6. Serve and Log (Observability)
Simple Comparison Table
| Approach | Best for | How it resolves conflicts | Pros | Watch-outs |
|---|---|---|---|---|
| Namespaces | Cross-domain isolation | Hard boundary by product area | Simple, org-aligned | Doesn’t fix intra-domain contention |
| Mutual exclusion | Certain clashes on one surface | Only one conflicting test per user | Statistically clean | Slows velocity; manual curation |
| Layered allocation | Many teams on one surface | Priority wins per parameter | Max throughput; flexible | Bias risk for lower layers; needs logging |
| Eligibility/triggering | Surgical control | Explicit rules & event-based entry | Granular; auditable | Sampling bias; rule sprawl |
| (Fractional) factorials | Learning interactions | Cross variants; model interactions | Synergy insight | More cells; more traffic; complexity |
View the raw file here, or conflict_resolution_table.md hosted by GitHub.
Code Block to Run Conflict-Aware Assignments
This single block wires together stable hashing, namespaces, independent per-layer assignment, mutual exclusion, eligibility/triggering, per-parameter priority merge, and effective-parameter logging.
# conflict-aware assignment for overlapping A/B tests.
# Compatible with Python 3.7+ (uses Optional[List[Dict]] instead of "|" and built-in generics).
from __future__ import annotations
from typing import Dict, List, Optional, Tuple, Any
import hashlib
from uuid import uuid4
# ---------- Core hashing ----------
def hash_to_bucket(user_id: str, salt: str, modulo: int = 10_000) -> int:
return int(hashlib.sha256(f"{salt}:{user_id}".encode()).hexdigest()[:8], 16) % modulo
def in_allocation(user_id: str, salt: str, pct: float) -> bool:
return hash_to_bucket(user_id, salt) < round(pct * 100)
# ---------- Mutual exclusion (pick one per group) ----------
def choose_exclusive(user_id: str, group_id: str, members: List[Dict[str, Any]]) -> Optional[str]:
total = sum(m.get("weight", 0) for m in members)
if total <= 0:
return None
cut = hash_to_bucket(user_id, f"excl:{group_id}", total)
acc = 0
for m in members:
acc += m["weight"]
if cut < acc:
return m["experiment"]
return None
# ---------- Targeting rules (simple) ----------
def eval_rule(rule: Dict[str, Any], ctx: Dict[str, Any]) -> bool:
# ctx: {"assignments": set[str], "attrs": dict, "triggers": set[str]}
if not rule: return True
if "all" in rule: return all(eval_rule(r, ctx) for r in rule["all"])
if "any" in rule: return any(eval_rule(r, ctx) for r in rule["any"])
if "not" in rule: return not eval_rule(rule["not"], ctx)
if "attrEq" in rule:
k, v = rule["attrEq"]["key"], rule["attrEq"]["val"]
return ctx["attrs"].get(k) == v
if "triggered" in rule: return rule["triggered"] in ctx["triggers"]
if "hasExp" in rule: return rule["hasExp"] in ctx["assignments"]
if "notInExp" in rule: return rule["notInExp"] not in ctx["assignments"]
return True
# ---------- Per-parameter priority merge (higher layers win) ----------
def merge_by_priority(layer_order: List[str], params_by_layer: Dict[str, Dict[str, Any]]
) -> Tuple[Dict[str, Any], List[Dict[str, str]]]:
effective: Dict[str, Any] = {}
overrides: List[Dict[str, str]] = []
for i, layer in enumerate(layer_order): # high -> low
for k, v in (params_by_layer.get(layer) or {}).items():
if k in effective:
winner = next(L for L in layer_order[:i] if k in (params_by_layer.get(L) or {}))
overrides.append({"param": k, "winner_layer": winner, "loser_layer": layer})
continue
effective[k] = v
return effective, overrides
# ---------- Serve path (one request) ----------
def serve_request(user_id: str, namespace_id: str, ctx: Dict[str, Any], cfg: Dict[str, Any]) -> Dict[str, Any]:
ns = next(ns for ns in cfg["product"]["namespaces"] if ns["id"] == namespace_id)
layers: List[str] = ns["layers"] # e.g., ["ranking","ads","ui"]
exps = [e for e in cfg["product"]["experiments"] if e["namespace"] == namespace_id]
groups = [g for g in cfg["product"]["exclusion_groups"] if g["namespace"] == namespace_id]
# 1) Assignment per experiment (after eligibility + trigger)
assignments: Dict[str, str] = {}
for e in exps:
c = {"assignments": set(assignments.values()),
"attrs": ctx.get("attrs", {}), "triggers": set(ctx.get("triggers", []))}
eligible = eval_rule(e.get("eligibility", {}), c)
triggered = (e.get("trigger") in c["triggers"]) if e.get("trigger") else True
if not eligible:
assignments[e["id"]] = "ineligible"
elif not triggered:
assignments[e["id"]] = "none"
else:
salt = f"exp:{e['id']}"
variant = "treatment" if in_allocation(user_id, salt, e["allocation_pct"]) else "control"
assignments[e["id"]] = f"{e['id']}:{variant}"
# 2) Mutual exclusion (keep chosen; mark others excluded)
for g in groups:
chosen = choose_exclusive(user_id, g["id"], g["members"])
if chosen:
for m in g["members"]:
eid = m["experiment"]
if assignments.get(eid, "").startswith(eid) and eid != chosen:
assignments[eid] = "excluded"
# 3) Build params per layer from final assignments
params_by_layer: Dict[str, Dict[str, Any]] = {L: {} for L in layers}
for e in exps:
a = assignments[e["id"]]
if not a.startswith(e["id"]): # ineligible/none/excluded
continue
vname = "treatment" if a.endswith(":treatment") else "control"
for pkey, opts in e.get("parameters", {}).items():
params_by_layer[e["layer"]][pkey] = opts[vname]
# 4) Priority merge + compact exposure log
effective, overrides = merge_by_priority(layers, params_by_layer)
return {
"request_id": str(uuid4()),
"namespace": namespace_id,
"assignments": assignments,
"effective_params": effective,
"override_details": overrides
}How to use: Load a single config (namespaces, layers in priority order, parameters with owners, experiments, exclusion groups). Call serve_request (user_id, “search”, ctx, conf) where ctx contains attributes (e.g., {“device”:”ios”}) and fired triggers (e.g., {“first_search”,”add_to_cart”}). You’ll get the per-experiment assignments, the effective parameter map after conflict resolution, and a structured log record.
Key Takeaways
- Make ownership explicit. One owner layer per parameter; lint configs for duplicate writers.
- Orthogonal assignment. Independent salts per layer/experiment to avoid accidental correlations.
- Log what shipped. Store the effective parameter map (post-merge) on every request; it’s the backbone for correct attribution.
- Use mutual exclusion sparingly. Reserve for a few contention-prone, high-reach surfaces or entry points.
- Mind selection effects. Eligibility/trigger rules are powerful — and can bias samples. Keep them auditable.
- Have a single source of truth for metrics. Consistent definitions prevent confusion when many tests overlap.
References and Further Reading
- Google – Tang, D., Agarwal, A., O’Brien, D., Meyer, M. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. KDD 2010.
- Meta/Facebook – Bakshy, E., et al. Designing and Deploying Online Field Experiments (PlanOut).
- LinkedIn – XLNT Platform engineering posts (targeting, segments, assignment at scale).
- DoorDash – Improving Online Experiment Capacity by 4× with Parallelization and Increased Sensitivity.
- Booking.com – Democratizing Online Controlled Experiments (culture, scale, meta-experiments).
- Airbnb – Minerva: Metric Consistency (single source of truth across experiments).
- Microsoft – Deng, A., et al. CUPED: A Practical Method for Reducing Variance in A/B Testing. WSDM 2013.
Published at DZone with permission of Arun Thomas. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments