Model Serving: Stream Processing vs. RPC/REST With Java, gRPC, Apache Kafka, TensorFlow
We take a look at these popular technologies, and see how they compare to stream processing when working with model serving.
Join the DZone community and get the full member experience.
Join For FreeMachine Learning/Deep Learning models can be used in different ways to do predictions. My preferred way is to deploy an analytic model directly into a stream processing application (like Kafka Streams or KSQL). You could, for example, use the TensorFlow for Java API. This allows for better latency and independence of external services. Several examples can be found in my GitHub project: Model Inference within Kafka Streams Microservices using TensorFlow, H2O.ai, Deeplearning4j (DL4J).
However, direct deployment of models is not always a feasible approach. Sometimes it makes sense or is needed to deploy a model in another serving infrastructure like TensorFlow Serving for TensorFlow models. Model Inference is then done via RPC/Request Response communication. Organizational or technical reasons might force this approach. Or you might want to leverage the built-in features for managing and versioning different models in the model server.
So you combine stream processing with the RPC/Request-Response paradigm. The architecture looks like the following:

Pros of an external model serving infrastructure like TensorFlow Serving:
- Simple integration with existing technologies and organizational processes.
- Easier to understand if you come from the non-streaming world.
- Later migration to real streaming is also possible.
- Model management built-in for different models and versioning.
Cons:
- Worse latency as remote call instead of local inference.
- No offline inference (devices, edge processing, etc.).
- Coupling the availability, scalability, and latency/throughput of your Kafka Streams application with the SLAs of the RPC interface.
- Side-effects (e.g. in case of failure) not covered by Kafka processing (e.g. Exactly Once).
Combination of Stream Processing and Model Server Using Apache Kafka, Kafka Streams, and TensorFlow Serving
I created the GitHub Java project "TensorFlow Serving + gRPC + Java + Kafka Streams" to demo how to do model inference with Apache Kafka, Kafka Streams, and a TensorFlow model deployed using TensorFlow Serving. The concepts are very similar for other ML frameworks and Cloud Providers, e.g. you could also use Google Cloud ML Engine for TensorFlow (which uses TensorFlow Serving under the hood) or Apache MXNet and AWS model server.
Most ML servers for model serving are also extendible to serve other types of models and data, e.g. you could also deploy non-TensorFlow models to TensorFlow Serving. Many ML servers are available as cloud service and for local deployment.
TensorFlow Serving
Let's discuss TensorFlow Serving quickly. It can be used to host your trained analytic models. Like with most model servers, you can do inference via a request-response paradigm. gRPC and REST/HTTP are the two common technologies and concepts used.
The blog post "How to deploy TensorFlow models to production using TF Serving" is a great explanation of how to export and deploy trained TensorFlow models to a TensorFlow Serving infrastructure. You can either deploy your own infrastructure anywhere or leverage a cloud service like Google Cloud ML Engine. A SavedModel is TensorFlow's recommended format for saving models, and it is the required format for deploying trained TensorFlow models using TensorFlow Serving or deploying on Google Cloud ML Engine.
The core architecture is described in detail in TensorFlow Serving's architecture overview:
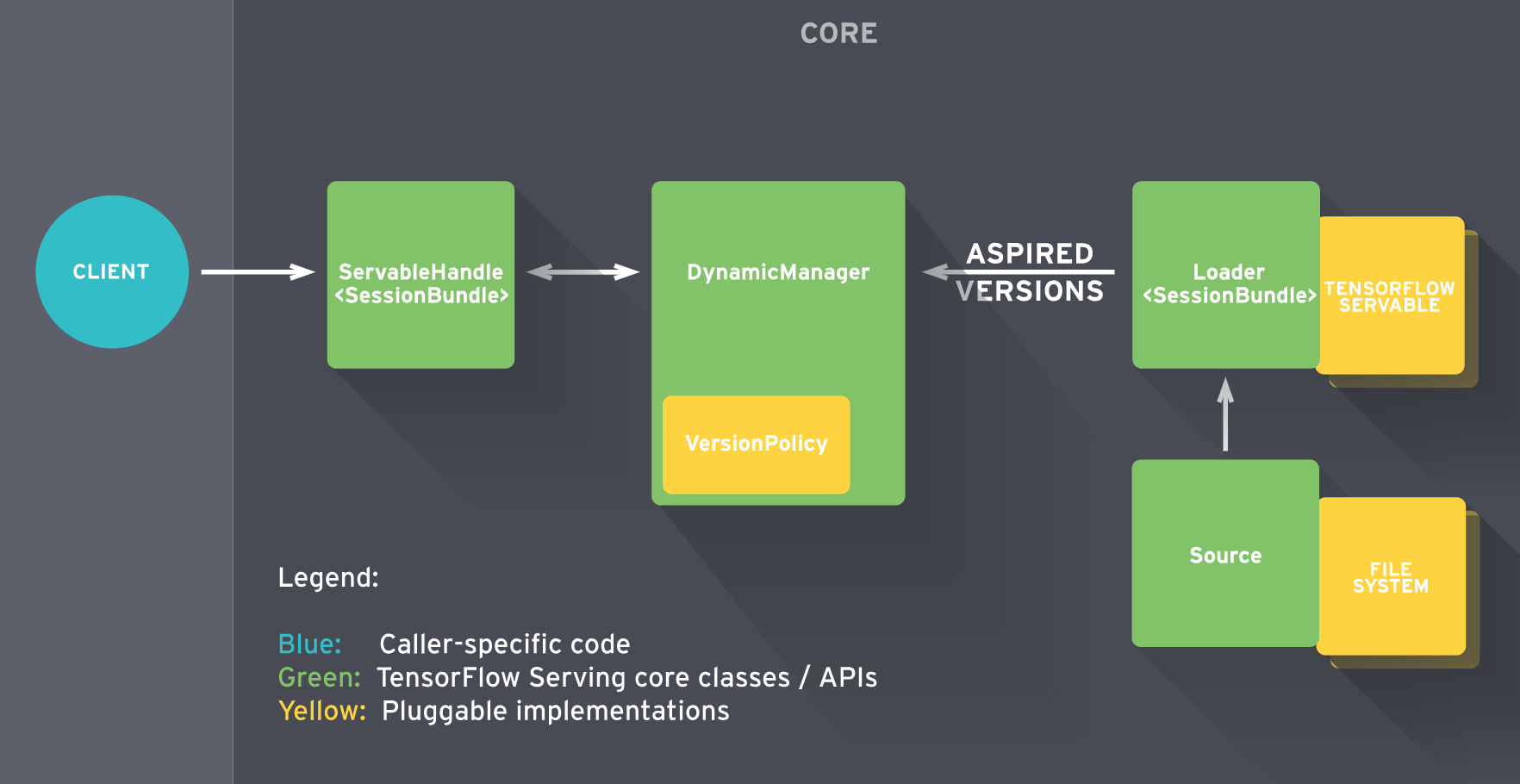
This architecture allows deployment and management of different models and versions of these models including additional features like A/B testing. In the following demo, we just deploy one single TensorFlow model for Image Recognition (based on the famous Inception neural network).
Demo: Mixing Stream Processing With RPC: TensorFlow Serving + Kafka Streams
Disclaimer: The following is a shortened version of the steps to follow. For full examples, including source code and scripts, please go to my GitHub project, "TensorFlow Serving + gRPC + Java + Kafka Streams."
Things to Do
- Install and start an ML Serving Engine.
- Deploy a prebuilt TensorFlow Model.
- Create a Kafka Cluster.
- Implement a Kafka Streams application.
- Deploy the Kafka Streams application (e.g. locally on a laptop or to a Kubernetes cluster).
- Generate streaming data to test the combination of Kafka Streams and TensorFlow Serving.
Step 1: Create a TensorFlow Model and Export it to the 'SavedModel' Format
I simply added an existing, pre-trained Image Recognition model built with TensorFlow. You just need to export a model using TensorFlow's API and then use the exported folder. TensorFlow uses Protobuf to store the model graph and adds variables for the weights of the neural network.
Google ML Engine shows how to create a simple TensorFlow model for predictions of census using the "ML Engine getting started guide." In a second step, you can build a more advanced example for image recognition using Transfer Learning, following the guide "Image Classification using Flowers dataset."
You can also combine cloud and local services, e.g. build the analytic model with Google ML Engine and then deploy it locally using TensorFlow Serving as we do.
Step 2: Install and Start TensorFlow Serving Server + Deploy Model
Different options are available. Installing TensforFlow Serving on a Mac is still a pain in the middle of 2018. apt-get works much easier on Linux operating systems. Unfortunately, there is nothing like a 'brew' command or simple zip file you can use on Mac. Alternatives:
- You can build the project and compile everything using Bazel build system - which literally takes forever (on my laptop), i.e. many hours.
- Install and run TensorFlow Serving via a Docker container. This also requires building the project. In addition, documentation is not very good and outdated.
- The preferred option for beginners => Use a prebuilt Docker container with TensorFlow Serving. I used an example from Thamme Gowda. Kudos to him for building a project which not just contains the TensorFlow Serving Docker image, but also shows an example of how to do gRPC communication between a Java application and TensorFlow Serving.
If you want to your own model, read the guide "Deploy TensorFlow model to TensorFlow serving." Or to use a cloud service, e.g. take a look at "Getting Started with Google ML Engine."
Step 3: Create Kafka a Cluster and Kafka Topics
Create a local Kafka environment (Apache Kafka broker + Zookeeper). The easiest way is the open source Confluent CLI - which is also part of Confluent Open Source and Confluent Enterprise Platform. Just type confluent start kafka.
You can also create a cluster using Kafka as a Service. The best option is Confluent Cloud - Apache Kafka as a Service. You can choose between Confluent Cloud Professional for "playing around" or Confluent Cloud Enterprise on AWS, GCP, or Azure for mission-critical deployments including 99.95% SLA and very large scale up to 2 GB/second throughput. The third option is to connect to your existing Kafka cluster on-premise or in the cloud (note that you need to change the broker URL and port in the Kafka Streams Java code before building the project).
Next create the two Kafka topics for this example ('ImageInputTopic' for URLs to the image and 'ImageOutputTopic' for the prediction result):
Step 4: Build and Deploy a Kafka Streams App + Send Test Messages
The Kafka Streams microservice (i.e. Java class) "Kafka Streams TensorFlow Serving gRPC Example" is the Kafka Streams Java client. The microservice uses gRPC and Protobuf for request-response communication with the TensorFlow Serving server to do model inference to predict the content of the image. Note that the Java client does not need any TensorFlow APIs, but just gRPC interfaces.
This example executes a Java main method, i.e. it starts a local Java process running the Kafka Streams microservice. It waits continuously for new events arriving at 'ImageInputTopic' to do a model inference (via gRCP call to TensorFlow Serving) and then sending the prediction to 'ImageOutputTopic' - all in real time within milliseconds.
In the same way, you could deploy this Kafka Streams microservice anywhere - including Kubernetes (e.g. on-premise OpenShift cluster or Google Kubernetes Engine), Mesosphere, Amazon ECS or even in a Java EE app - and scale it up and down dynamically.
Now send messages, e.g. with kafkacat, and use kafka-console-consumer to consume the predictions.
Once again, if you want to see source code and scripts, then please go to my GitHub project "TensorFlow Serving + gRPC + Java + Kafka Streams."
Published at DZone with permission of Kai Wähner. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments