Monoliths, Cookie-Cutter or Microservices
Join the DZone community and get the full member experience.
Join For Freerecently some pwc tech supremos wrote an article: agile coding in enterprise it: code small and local .
subsections:
- moving away from the monolith
- why microservices?
- msa: a think-small approach for rapid development
- thinking the msa way: minimalism is a must
- where msa makes sense
- in msa, integration is the problem, not the solution
- conclusion
msa is short for microservices architecture(s), in the above article.
the article posits that microservices is the antidote to monoliths. it doesn’t mention cookie cutter scaling at all, which is another antidote to monoliths, with the right build infrastructure and devops. here’s a view of hypothetical architecture a company could deploy if they were doing microservices:
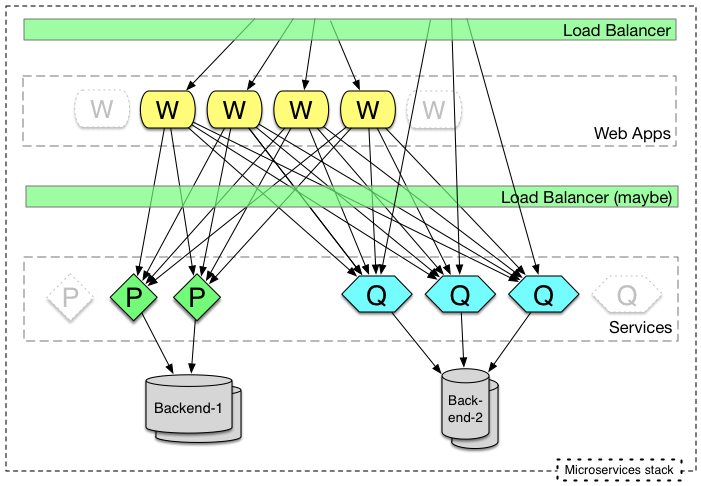
w is web server. p and q don’t stand for anything in particular.
here’s the same solution as cookie-cutter scaling, and the alternate (historical) choice of monolith to the right of it:
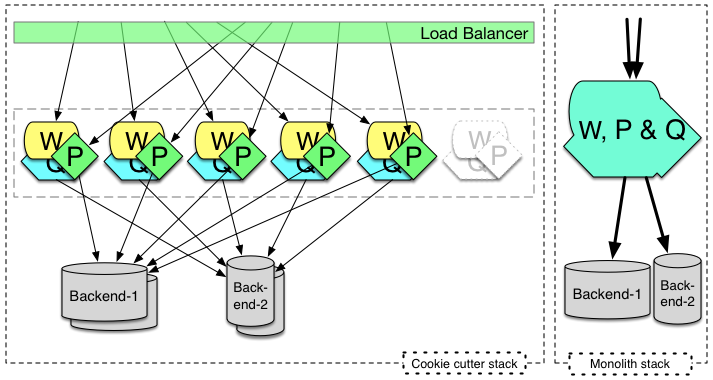
the cookie cutter approach will often leverage components that are dependency injected into each other, and though monoliths might be the same today, pre 2004 they were probably hairballs of singletons (the design patten, not the springframework idiom).
continuous delivery, agile?
here’s one excerpt that confuses me:
" … makes no sense to design and develop software over an 18-month process to accommodate all possible use cases when those use cases can change unexpectedly and the life span of code modules might be less than 18 months….
as i recall, the 18 month-delay problem was solved previously. agile methodologies principally, and continuous delivery/deployment in more recent times. it does not matter whether you’re compiling a monolith, a cookie-cutter solution, old soa services, or microservices, the 18-month fear isn’t real if you’re doing agile and/or cd. agile and cd were increasing the release cadence, and allowing the organization to pivot faster before microservices. it doesn’t matter whether you’ve got a monolith, something cookie-cutter scaled, or soa (micro or not), you’re going to be able to benefit from agile practices and devops setup that facilitates cd. in something like 30 thoughtworks client engagements since 2002, i have not seen the 18-month process at all. in fact i last encountered it in 1997 on an as/400 project, which was the last time i saw a waterfall process being championed.
build(s) and trunk
elsewhere there is a suggestion: “each microservice [has] its own build, to avoid trunk conflict”. that isn’t unique to microservices, of course. component based systems today also have a multiple build file (module) structure in a source tree. hopefully “trunk” mentioned is alluding to trunk based development, as i would recommend.
build technologies
this is a expansion on the above, and you can skip this paragraph if you want.
hierarchical build systems like maven has allow you to have one build file per module (whether that’s a service or a simple jar destined for the classpath of a bigger thing). buck has a build grammar that allows for a build to grow/shrink/change based on what is being built (from implicitly shared source). maven is for the java ecosystem, while buck promises to be multi-language. both are doing multi-module builds for the sake of a composed or servicified deployment. both maven and buck are presently competing to draw the most reduced set of compile/test/deploy operations for the changes since last build for a hierarchy of modules.
anyway, what is it we are striving for?
what we want is to develop cheaply, and to deploy smoothly and often, without defect. we want the ability to deploy without large permanent or temporary headcount overseeing or participating in deployment. aside from development costs, and support/operation, deployment costs are a potentially big factor in total cost of ownership.
what i like about cookie-cutter is the uniformity of the deployable things. the team size for deployment of such a thing doesn’t grow with the numbers of nodes that binary is being deployed to. at least, if you’re able to automate the deployment to those nodes, and have a strategy for handling the users connected to the stack at redeployment time somehow (sessions or stateless). the uniformity of the deployment is a cheapener, i think.
when you have a number of dissimilar services, you might be able to minimize release personnel if you’re only doing one service. if more than one service is being updated in a particular deployment, you’re going to have to concentrate to make sure you don’t experience a multiplier effect for the participants. it is possible of course, to keep the headcount small, but the practice needed beforehand is bigger, which in turn allows for some calmness around the actual deployment. if we’ve stepped away from the project management office thinking that suggests three buggy releases a year (which is more usual than 18 month schedules of old), then we can employ continuous deployment to further eliminate personnel costs around going live. this is something that microservices does well at, but because the most adept proponents design forwards & backwards compatibility into the permutations most likely to co-exist in production. it is at least much quicker to redeploy and bounce one small service, n times than the the cookie-cutter uniform deployment.
Published at DZone with permission of Paul Hammant. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments