Beyond Fuzzy Matching: Engineering a Multi-Signal ML Pipeline for CRM Deduplication
This article explores using blocking, fuzzy matching, geo proximity, and a Random Forest classifier to streamline records.
Join the DZone community and get the full member experience.
Join For FreeThe CRM Problem We All Face
Almost every CRM platform struggles with duplicate customer records because the data is a messy mix flowing in from too many places — web forms, call centers, imports from ERP, partner feeds, and even legacy systems from multiple business units. The exact same company can pop up under slightly different names, with spelling variations, inconsistent addresses, or missing suite numbers. A simple single-rule fuzzy match isn't enough to connect these dots.
To truly fix this, we need something smarter: a multi-signal pipeline. This means using a blocking layer to speed up things, checking fuzzy name and address similarity, using geographic distance as a reality check, and implementing a small machine learning classifier to weigh all the evidence and decide if two records should be merged.
This article walks through a compact version of the pipeline, built in Python using rapidfuzz, geopy, and a Random Forest classifier. You can run everything locally and extend it however you want.
The Multi-Signal ML Pipeline Architecture
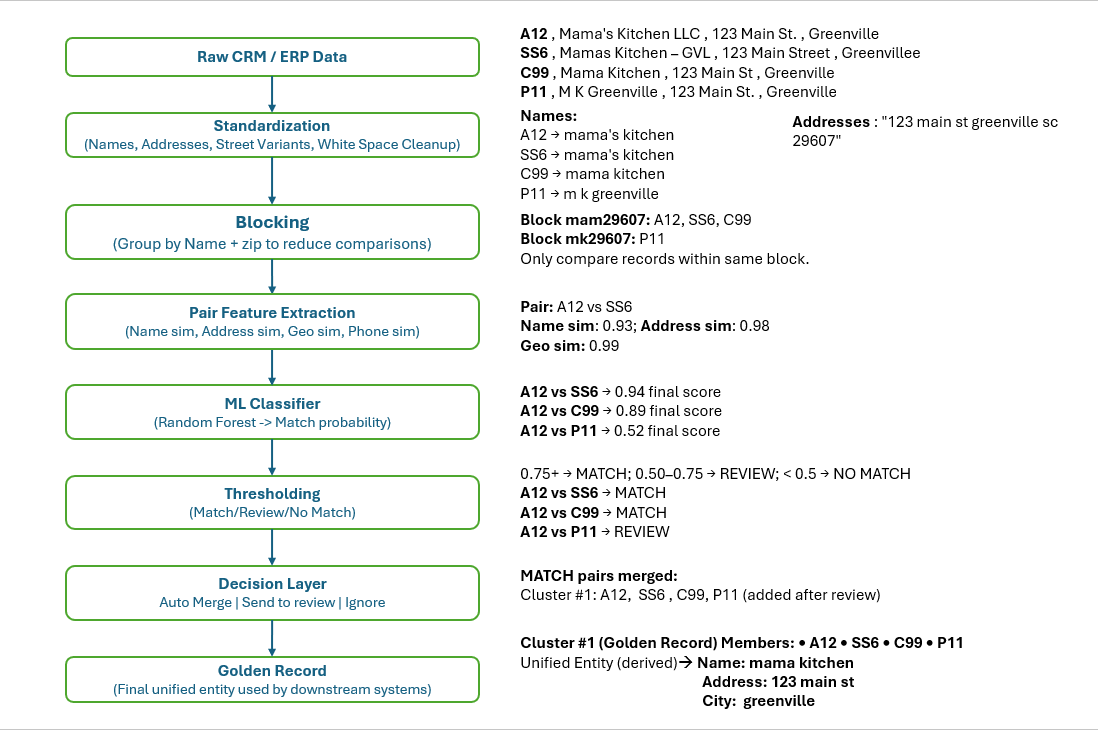
1. Starting with Messy Data
Let's look at a typical real-world example. Here are four records that are clearly connected, but a standard system might not see the relationship.
| ID | Name | Address | ZIP | Lat/Lon |
|---|---|---|---|---|
| A12 | Mama's Kitchen LLC | 123 Main St | 29607 | close coords |
| SS6 | Mamas Kitchen – Greenville | 123 Main St Ste A | 29607 | close coords |
| C99 | Mama Kitchen | 123 Main Street | 29607 | close coords |
| P11 | M K Greenville | 123 Main St | 29607 | nearly identical co-ords |
2. Standardize the Mess
Most of the magic in matching begins with the boring work: normalize the things humans enter inconsistently.
We don’t need heavy NLP; just a simple clean up of lowercase, stripping punctuation, and compressing whitespaces helps fuzzy matching become stable. For example, this takes all the versions of the above customer names and turns those into consistent strings like mamas kitchen and mk greenville.
import re
import pandas as pd
def normalize(text):
if not text:
return ""
text = text.lower()
text = re.sub(r"[^\w\s]", " ", text)
text = re.sub(r"\bstreet\b", "st", text)
text = re.sub(r"\s+", " ", text)
return text.strip()
df["name_std"] = df["name"].apply(normalize)
df["addr_std"] = df["address"].apply(normalize)
3. Blocking: The Step That Saves Everything (Including Your CPU)
This is a very simple but critical point: Comparing every record to every other record will result in O(N²) complexity. To avoid that, we derive a block key:
block_key = first 3 letters of normalized name + zip.
For our example records, this groups A12, SS6, C99 --> mam29607 and P11 --> mk29607.
from itertools import combinations
def block_key(row):
return row["name_std"][:3] + "_" + row["ZIP"]
df["block"] = df.apply(block_key, axis=1)
# The critical step—generating pairs only within the same block.
all_pairs = []
for block_id, block_data in df.groupby("block"):
# The index of the DataFrame (df.index) should be the record ID (e.g., A12, SS6)
record_ids = block_data.index.tolist()
# Generate all unique combinations of IDs within the block
pairs_in_block = list(combinations(record_ids, 2))
all_pairs.extend(pairs_in_block)
print(f"Total pairs generated after blocking: {len(all_pairs)}")
Running pairwise comparisons only within each block keeps the pipeline fast, even with millions of CRM records. P11 falls into a separate block, but we’ll revisit it because geo proximity tells a different story.
4. Feature Engineering: Extracting the Real Signals
For each pair inside a block, we compute:
- Name similarity (token sort ratio or similar)
- Address similarity
- Geo distance converted into a similarity (1.0 when extremely close)
Critical insight: On real CRM data, geo_sim is the single most powerful differentiator.
from rapidfuzz import fuzz
from geopy.distance import geodesic
import numpy as np
# We'll assume the input records are indexed in the DataFrame 'df'
def extract_features(a, b):
A, B = df.loc[a], df.loc[b]
# 1. Name and Address Similarity (Fuzzy Matching)
name_sim = fuzz.token_sort_ratio(A["name_std"], B["name_std"]) / 100
addr_sim = fuzz.token_sort_ratio(A["addr_std"], B["addr_std"]) / 100
# 2. Geo Proximity (Physical Distance)
d = geodesic((A["lat"], A["lon"]), (B["lat"], B["lon"])).meters
# geo_sim is 1.0 when extremely close, degrading towards 0.
[span_24](start_span)geo_sim = max(0, 1 - d / 500) # anything within ~0–500m is highly likely same operator[span_24](end_span)
# 3. Structural Cues
zip_match = int(A["ZIP"] == B["ZIP"])
prefix_match = int(A["name_std"][:4] == B["name_std"][:4])
return [name_sim, addr_sim, geo_sim, zip_match, prefix_match]
# Code to extract features for all generated pairs (X)
X_features = []
pair_indices = []
for idx_a, idx_b in all_pairs:
features = extract_features(idx_a, idx_b)
X_features.append(features)
pair_indices.append((idx_a, idx_b))
# Convert to a format ready for the ML model
X = np.array(X_features)
print(f"X array shape: {X.shape}")
5. A Tiny ML Model to Tie It All Together
Rather than adding more handcrafted rules, we let a small Random Forest combine the features and estimate the probability of a match.
The Training Data Challenge
To train this model, we need a manually labeled dataset: pairs of records that are known matches (1) and known non-matches (0). Since labeling millions of pairs is impossible, we typically:
- Label a small, diverse sample (e.g., 5,000 pairs).
- Use hard-coded rules to auto-label the highest confidence matches and non-matches, feeding these into the training set.
This ensures the model learns which features are truly indicative of a duplicate.
from sklearn.ensemble import RandomForestClassifier
# For a real-world system, you would train this model on a labeled dataset (X_train, y_train)
# model.fit(X_train, y_train)
model = RandomForestClassifier(
n_estimators=70, max_depth=6, random_state=42
)
# Note: You can use logistic regression, but forests are surprisingly good here because the
# [span_26](start_span)interactions between features (like geo + fuzzy differences) behave a bit non-linear[span_26](end_span).
# Assuming the model is trained, use it to predict the match probability on all generated pairs (X)
probabilities = model.predict_proba(X)[:, 1]
# Now, match the probabilities back to the pair IDs for the Decision Layer
results = pd.DataFrame({
'Pair_A': [p[0] for p in pair_indices],
'Pair_B': [p[1] for p in pair_indices],
'Match_Probability': probabilities
})Why not logistic regression? You can — but forests are surprisingly good here because the interactions between features (like geo + fuzzy differences) behave a bit non-linear.
Here’s how the model scores our earlier pairs:
A12 vs SS6 → 0.94
A12 vs C99 → 0.89
A12 vs P11 → 0.52 (cross-block check because geo_sim was high)
That last one is the interesting case: the name doesn’t match at all, but the records lie practically on top of each other on the map.
6. The Decision Layer (Where Humans Still Matter)
Based on the confidence scores, we apply thresholds:
- 0.75+ --> MATCH (Auto-Merge)
- 0.50–0.75 --> REVIEW (Send to Human-in-the-Loop)
- 0.50 --> NO MATCH (Ignore)
So, the three “mama kitchen” variants merge automatically, but P11 doesn’t. But when a human sees the same coordinates, the same address, and recognizes “M K” as an abbreviation of “Mama Kitchen,” they can approve the merge.
It sounds small, but adding humans only for this narrow band dramatically reduces errors in CRMs where sales crediting depends on correct customer identity.
7. Building the Final Unified Customer
We derive the golden record by taking the densest cluster of matched records and using the metadata that appears most consistently after normalization.
Cluster#1 : A12,SS6,C99,P11 (P11 added after review)
Unified Name (Derived): mama kitchen
Unified Address (Derived): 123 main st, greenville sc 29607
P11 folds into the cluster after review, bringing its metadata with it.
8. Why This Works Better Than Pure Fuzzy Matching
Because in real-world enterprise systems, data is messy. For a single physical customer, records are maintained across multiple systems. A name may be very different, but the coordinates are identical. Addresses may be formatted in three different ways, but point to the same building. Sometimes, category metadata (if available) adds to these.
Hard-coded rules struggle with these overlaps, often requiring huge, complex, and high-maintenance rule sets. But a small ML model, powered by a multi-signal approach, can handle these nonlinear relationships well and solve the core data quality issues with minimal human effort.
Opinions expressed by DZone contributors are their own.
Comments