Multi-Tenant Cassandra Clusters With Spring Data Cassandra
What options does Cassandra provide for operating multi-tenant clusters? Do you have your services prepared to do the work properly? Read on to find out.
Join the DZone community and get the full member experience.
Join For FreeApache Cassandra is getting more and more popular these days. Some companies may want to operate a multi-tenant cluster. What options does Cassandra provide for this? Do you have your services prepared to do the work properly?
In this article, we will go through a practical example using Spring Boot and spring-data-cassandra.
How to Prepare Cassandra for Multitenancy
When thinking about multi-tenancy, we have to decide how to manage tenants inside our cluster. There are multiple options, each with their own pros and cons.
Row-Level Multitenancy
Each table has a tenant_id column in its partition key that determines which tenant the record belongs to.
Pros
Easy to apply, as you just have to add a new column to partition keys.
Less maintenance cost. Everything above table level looks like one single cluster.
Cons
Schema changes for tenants need to be deployed at once for all tenants.
Hard to optimize for tenant-specific usage (compaction, caching, etc.).
Cassandra doesn't allow for altering of primary keys. We can't just add this column to existing tables.
Table-Level Multitenancy
Each table hastenant_id suffix in its name. Tenants are isolated by tables.
Pros
Different table schema allowed for tenants.
- More option in fine-tuning table properties according to tenant-specific usage. You can change bloom filter settings, GC grace periods, etc. on each table.
Granting-revoking permissions on a per-table basis.
Cons
CQL commands have to be manipulated to append
tenant_idinto the table's name.Increased number of tables causes maintenance overhead. For instance, more MemTables created and maintained means that more flush operations have to be handled in the background and more random IO has to be performed.
The soft limit for number of tables inside a cluster is around 10,000.
Keyspace-Level Multitenancy
Tenants use different keyspaces. Keyspace name maps to a single tenant_id.
Pros
Different kind of replication strategies are available per tenant.
- We can control which datacenter is available for each tenant.
Cons
Similar to table-level multitenancy.
Higher-Level Multitenancy
Other levels of isolation can be introduced for better separation. For example each tenant can have it's own cluster in Cassandra. This would mean that we have to map cluster_name in cassandra.yaml to our tenant_id. With this approach only one node can belong to only one tenant. We'll skip discussing them in detail.
How to Prepare Your Services for Accessing the Cluster
We will discuss keyspace-level multitenancy in detail with Spring Data Cassandra.
The picture below shows a simplified dataflow diagram. Let's say that in this particular setup, DC1 and DC2 contain Tenant A's dataset, while DC2 and DC3 contain Tenant B's dataset. If you deploy your services to DC1 and DC3, you could just wire-in the target keyspace into the application at deployment time, as all the incoming traffic will be from the same tenant. But we might want to set up a shared datacenter for multiple tenants (like the one named DC2). We could still deploy our services by defining keyspace name at deployment time (called spring.data.cassandra.keyspace-name in the Spring Boot configuration file), but that would mean that we have to route our incoming traffic to services by considering tenant ID.
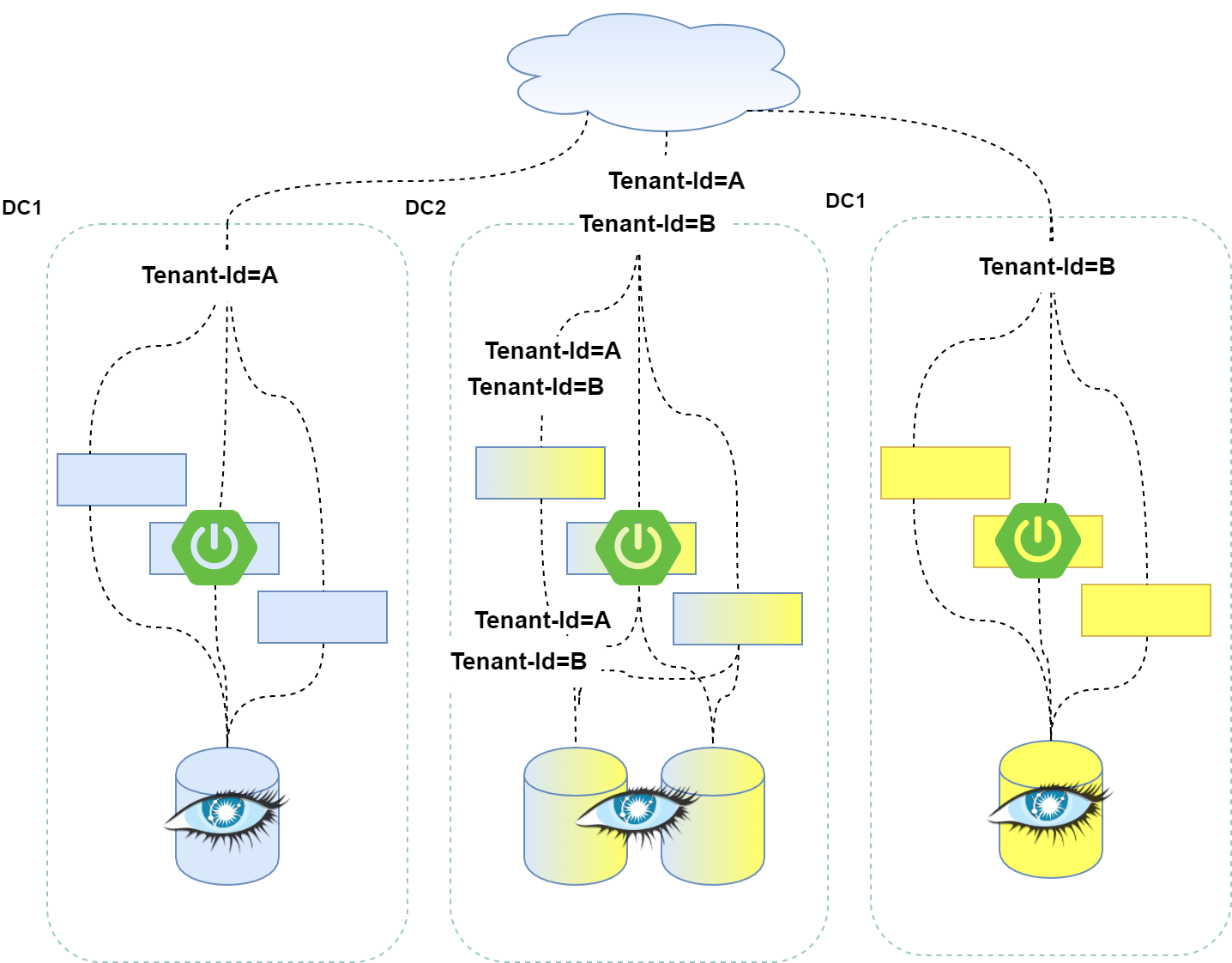
Allowing all services to be able to serve any kind of tenant-id would not only help spread the load and increase scalability but would also introduce statelessness to our services and simplify routing logic. With this approach, we can no longer define tenant-id during deployment. We have to handle tenant isolation on a per-request basis.
Requests should encapsulate tenant ID, so we'll introduce a special HTTP header for storing it.
Tenant-ID: ACMENext, we should be able to get the defined HTTP header inside our services. In Spring, we can define a request-scoped bean that will encapsulate our tenant-id and bind it to our incoming requests. This will be injected to any other Spring component that should be tenant aware.
@Component
@Scope(scopeName = "request", proxyMode= ScopedProxyMode.TARGET_CLASS)
public class TenantId {
private String tenantId;
public void set(String id) {
this.tenantId = id;
}
public String get() {
return tenantId;
}
}
We have to set the TenantId 's state in our Controllers whenever an HTTP request is handled.
@RestController
public class UserController {
@Autowired
private UserRepository userRepo;
@Autowired
private TenantId tenantId;
@RequestMapping(value = "/userByName")
public ResponseEntity<String> getUserByUsername(
@RequestHeader("Tenant-ID") String tenantId,
@RequestParam String username) {
// Setting the tenant ID
this.tenantId.set(tenantId);
// Finding user
User user = userRepo.findOne(username);
...
}
}To use TenantId in our repositories, we have to extend the existing Repository functionality in Spring Data Cassandra. We have the option to overwrite common operations that are defined in CrudRepository class like save, findOne, or findAll. We'll define our own repository extension in the Application class of Spring Boot.
@SpringBootApplication
@EnableCassandraRepositories(
repositoryBaseClass = KeyspaceAwareCassandraRepository.class)
public class DemoApplication {
...
}And we override the common operations one-by-one in our KeyspaceAwareCassandraRepository.
public class KeyspaceAwareCassandraRepository<T, ID extends Serializable>
extends SimpleCassandraRepository<T, ID> {
...
@Autowired
private TenantId tenantId;
...
@Override
public T findOne(ID id) {
injectDependencies();
CqlIdentifier primaryKey = operations.getConverter()
.getMappingContext()
.getPersistentEntity(metadata.getJavaType())
.getIdProperty().getColumnName();
Select select = QueryBuilder.select().all()
.from(tenantId.get(),
metadata.getTableName().toCql())
.where(QueryBuilder.eq(primaryKey.toString(), id))
.limit(1);
return operations.selectOne(select, metadata.getJavaType());
}
...
}Note that @Autowired is not supported in this class, as it's not container-managed. We have to get the servlet context through some static methods.
For domain-specific queries, like getting a user by name and e-mail, we have to write the opreation one-by-one for each class to be able to define keyspace in queries by our injected TenantId. For example, here's a Repository extension that will find User by username and e-mail. Note the KeyspaceAwareUserRepository that we're using as an extension for the custom operation.
public interface UserRepository
extends CrudRepository<User, String>, KeyspaceAwareUserRepository {
}public interface KeyspaceAwareUserRepository {
User findByUsernameAndEmail(String username, String email);
}In the implementation, we're writing our select with using the TenantId in our request scoped bean.
public class UserRepositoryImpl
implements KeyspaceAwareUserRepository {
@Autowired
private TenantId tenantId;
@Autowired
private CassandraOperations operations;
@Override
public User findByUsernameAndEmail(String username, String email) {
Select select = QueryBuilder.select().all()
.from(tenantId.get(),"user")
.where(QueryBuilder.eq("username", username))
.and(QueryBuilder.eq("email", email))
.limit(1);
return operations.selectOne(select, User.class);
}
}How to Ensure That Things Are Working Properly
For testing that our services are using keyspaces consistently, running a short stress-test that puts a decent load on a small cluster is fine. Make sure that there are good-enough context switches inside the Spring Boot application during test execution.
For running in production, I suggest having good monitoring in place in your Spring Boot and Cassandra instances. You should be tracing at least these metrics for each tenant:
Putting too much stress on the cluster
Exceeding quota
Exceeding table limit
Summary
In its current state, it's not easy to introduce multi-tenancy to spring-data-cassandra. The Datastax Java driver is handling all request asynchronously, so just throwing-in a USE keyspace command somewhere in our code won't do the trick. This is also explained in the official driver documentation:
"Be very careful though: if the session is shared by multiple threads, switching the keyspace at runtime could easily cause unexpected query failures. Generally, the recommended approach is to use a single session with no keyspace, and prefix all your queries."
We also have to ensure that our solution is somewhat future-proof and honors intentional extension points in Spring Data. Currently, extending repositories, according to the official reference manual, seems to be the only acceptable solid implementation for me.
Opinions expressed by DZone contributors are their own.
Comments