8 Challenges in Multimodal Training Data Creation
Creating high-quality multimodal training data is essential yet complex, involving challenges in synchronization, scalability, context capture, and tooling.
Join the DZone community and get the full member experience.
Join For FreeMultimodal AI processes multiple forms of data, like images, sounds, and words, all at once, to empower your applications to not just listen to our voice or read text but also pick up facial expressions and the details around us. This technology is rapidly making our daily interactions easier and natural, and when using applications with which you can communicate, it feels almost as if you are chatting with your friends.
The first multimodal large language model that handled both text and images effectively was GPT-4 in 2023. The most recent multimodal model, GPT-4o Vision, is equipped to create interactions that are incredibly lifelike.
No wonder the Multimodal AI Market’s size was valued at USD 1.2 billion in 2023 and is expected to grow at a CAGR of over 30% between 2024 and 2032.
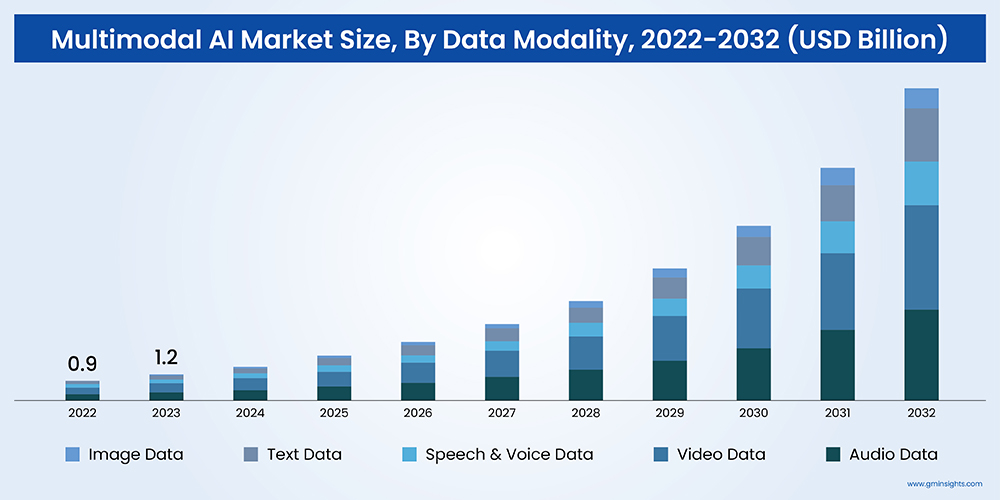
But at the heart of this significant growth lies a crucial dependency: training data. The accuracy, robustness, and adaptability of these models depend largely on the quality, diversity, and synchronization of the datasets on which they are trained. Precision in cross-data type labeling, alignment of multisensory inputs, and contextual sentiment annotation are foundational to these datasets. The complexity of building AI-ready datasets is often underestimated.
Unlike single-modality data, multimodal datasets encompass a lot of hidden challenges, including temporal alignment issues to inter-modal context preservation. These challenges degrade model performance if not addressed. So, let’s check out the eight core challenges that AI teams face when creating multimodal training data.
8 Key Challenges in Creating Multimodal Training Data
Understanding and addressing multimodal training data challenges in a timely manner will help you build scalable, high-fidelity data pipelines that power the next generation of multimodals.
Challenge 1: Data Heterogeneity and Standardization
Multimodal datasets comprise a wide variety of data/information such as structured text, unstructured images, time-series audio, and raw sensor streams. These data types are in distinct formats, encodings, resolutions, and metadata, and create significant pitfalls in the path of building unified data pipelines. AI models cannot leverage these modalities directly without normalization, and readily available tools often lack the flexibility and features to handle such diverse inputs in a synchronized manner.
This heterogeneity negatively impacts every layer of the pipeline. It makes schema definitions inconsistent, data ingestion logic becomes brittle, and storage architectures struggle to scale across incompatible formats. Without standardization, coordination across modalities becomes unreliable, directly affecting training outcomes. Source
One needs to hire a purpose-built service provider who can normalize, align, and annotate multimodal inputs to address the challenges of data heterogeneity. Resorting to cross-data type labeling and AI-ready diverse dataset services helps you convert raw, heterogeneous data into structured, machine-consumable formats. This basic data exercise is mandatory for creating robust multimodal AI pipelines and operating at scale.
Challenge 2: Inter-Modal Synchronization and Alignment
Precise alignment of text, audio, images, and sensor signal data streams across time and space guarantees effective multimodal learning. Classic examples include synchronizing dialogue with facial expressions in video or mapping LIDAR data to vehicle telemetry in robotics. Misalignments can misrepresent an AI model’s perception and damage performance.
Varying capture rates, latency offsets, and the accurate reconciliation of asynchronous signal streams amplify this challenge. Even minor desynchronization breaks the context and compromises downstream tasks. Robust alignment of multisensory inputs, backed with synchronized multi-sensor tagging, will ensure temporal and spatial coherence, enable consistency, and high-fidelity cross-modal training.
Challenge 3: Contextual Nuances and Ambiguity
Tone, facial expression, and phrasing are not only a part of human communication but also convey more than words alone. It is a difficult task to capture these nuanced signals across modalities. Sarcasm detection is a classic example of it. It requires interpreting lexical content alongside vocal inflection and visual cues.
This complexity is known to bring in subjectivity in sentiment analysis, emotion recognition, and intent prediction. A lack of standardized interpretation leads to inconsistent labeling and hence reduced model reliability.
Expert teams providing contextual sentiment annotation services with cross-data type labeling help you address this issue. These service providers ensure that inter-modal signals are accurately captured, and the semantic depth needed for reliable multimodal learning is well preserved. Source
Challenge 4: Scalability and Volume Management
Massive by nature, multimodal datasets comprise mainly high-resolution images, lengthy audio streams, and extensive text annotations of which quickly compound into terabytes of data. This immense data complexity requires appropriate infrastructure and workflows to handle.
AI and ML companies understand that these challenges are multifaceted. Storing heterogeneous data efficiently, transmitting large files without latency bottlenecks, and scaling annotation efforts without compromising accuracy are no walks in the park. Managing data versioning and accommodating incremental updates adds to the complications of managing a stable multimodal data pipeline.
Scalable storage and computing, streamlined annotation processes, and tooling optimized for multimodal workflows prove to be a smart move in managing this challenge. Without these, building production-grade AI-ready datasets becomes unsustainable at scale.
Challenge 5: Quality Assurance and Consistency
Maintaining the quality of annotations across modalities is a challenge; however, it becomes a bigger challenge when it comes to creating multimodal training data. A single instance of mislabeling in one modality is capable of distorting the alignment and misleading contextual interpretation of the entire training dataset.
The interplay between data types plays a hurdle in establishing consistent guidelines for multimodal tasks. Attaining high inter-annotator agreement (IAA) requires deep expertise and training, backed with validation workflows that span text, audio, image, and sensor data, where each of them has distinct metrics and failure modes.
Delivering reliable, AI-ready, diverse datasets demands specialized capabilities in cross-modal fusion and rigorous QA pipelines designed to catch errors before they reach downstream models.
Challenge 6: Data Privacy and Ethical Considerations
Sensitive personal information, like faces in videos, identifiable speech, or biometric sensor data captured for creating multimodal training datasets, raises serious privacy and ethical concerns, particularly when human subjects are involved.
Organizations, in order to stay compliant with GDPR, HIPAA, or CCPA regulations, must implement strict anonymization protocols, manage informed consent, and ensure secure data handling across the pipeline. This is also necessary, as unaddressed biases in training data are capable of amplifying discrimination in deployed models, making ethical diligence non-negotiable.
These compliance requirements bring in operational and technical complexity and warrant disciplined workflows and annotation practices where privacy, transparency, and fairness are a priority, and dataset utility or fidelity are not compromised.
Challenge 7: Tooling and Platform Limitations
Unlike a few, most of the annotation tools are built for single modalities like image, video, or text. This uniqueness makes them incapable of meeting the complex demands of multimodal workflows. The number of platforms that are capable of synchronously handling and displaying diverse data types is either limited or under development.
This situation leads to a fragmented workflow, where annotators are required to switch between systems, manually synchronize inputs, and reconcile outputs. This obviously results in inefficiencies, annotation delays, and higher error rates, becoming a bottleneck as dataset complexity increases.
Robust, unified annotation environments purpose-built for text, image, and audio fusion, and cross-data type labeling in real time, are a mandate for building accurate multimodal datasets.
Challenge 8: Expertise and Resource Availability
A fine blend of domain expertise, data science literacy, and proficiency in handling diverse data types through advanced annotation platforms is the essence of multimodal annotation. Finding and training data, image, video, or audio annotation to interpret emotional tone in speech paired with facial expression is absolutely not as easy as it may sound.
AI and ML companies regularly face missed project deadlines and compromised annotation quality due to a shortage of specialized human intelligence. Overcoming this challenge demands dedicated training pipelines, QA oversight, and access to a well-managed pool of multidisciplinary annotation talent.
Conclusion
Producing excellent multimodal training data is complicated, but critical to developing AI systems that really get context, intent, and subtlety across a variety of inputs. From modality synchronization to semantic coherence preservation, every step is fraught with technical and operational issues that cannot be ignored.
For organizations looking to drive context-aware, human-centered AI, collaborating with a dedicated multimodal annotation provider is not a choice, but it's a strategic imperative. With the right people, equipment, and approach, these collaborations deliver scalable, high-accuracy, ethically responsible data pipelines that fuel the next wave of smart, multimodal AI solutions.
Opinions expressed by DZone contributors are their own.
Comments