Utilizing Multiple Vectors and Advanced Search Data Model Design for City Data
Learn how to build, architect, and design complex unstructured data applications for vector databases utilizing Milvus, GenAI, LangChain, YoLo, and more.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we will build an advanced data model and use it for ingestion and various search options. For the notebook portion, we will run a hybrid multi-vector search, re-rank the results, and display the resulting text and images.

- Ingest data fields, enrich data with lookups, and format: Learn to ingest data including JSON and images, format and transform to optimize hybrid searches. This is done inside the streetcams.py application.
- Store data into Milvus: Learn to store data in Milvus, an efficient vector database designed for high-speed similarity searches and AI applications. In this step, we are optimizing the data model with scalar and multiple vector fields — one for text and one for the camera image. We do this in the streetcams.py application.
- Use open source models for data queries in a hybrid multi-modal, multi-vector search: Discover how to use scalars and multiple vectors to query data stored in Milvus and re-rank the final results in this notebook.
- Display resulting text and images: Build a quick output for validation and checking in this notebook.
- Simple Retrieval-Augmented Generation (RAG) with LangChain: Build a simple Python RAG application (streetcamrag.py) to use Milvus for asking about the current weather via Ollama. While outputing to the screen we also send the results to Slack formatted as Markdown.
Summary
By the end of this application, you’ll have a comprehensive understanding of using Milvus, data ingest object semi-structured and unstructured data, and using open source models to build a robust and efficient data retrieval system. For future enhancements, we can use these results to build prompts for LLM, Slack bots, streaming data to Apache Kafka, and as a Street Camera search engine.
Milvus: Open Source Vector Database Built for Scale
Milvus is a popular open-source vector database that powers applications with highly performant and scalable vector similarity searches. Milvus has a distributed architecture that separates compute and storage, and distributes data and workloads across multiple nodes. This is one of the primary reasons Milvus is highly available and resilient. Milvus is optimized for various hardware and supports a large number of indexes.
You can get more details in the Milvus Quickstart.
For other options for running Milvus, check out the deployment page.
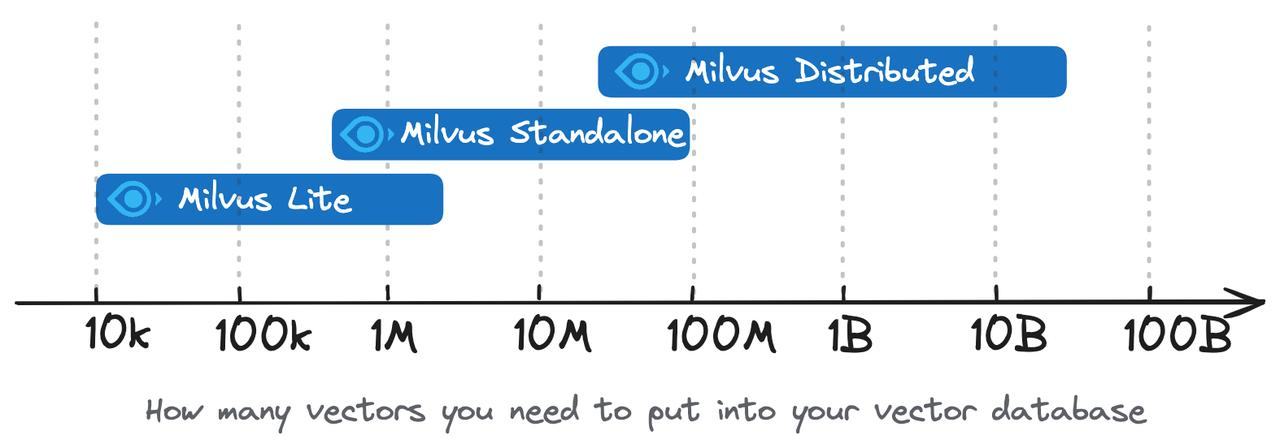
New York City 511 Data
- REST Feed of Street Camera information with latitude, longitude, roadway name, camera name, camera URL, disabled flag, and blocked flag:
{
"Latitude": 43.004452, "Longitude": -78.947479, "ID": "NYSDOT-badsfsfs3",
"Name": "I-190 at Interchange 18B", "DirectionOfTravel": "Unknown",
"RoadwayName": "I-190 Niagara Thruway",
"Url": "https://nyimageurl",
"VideoUrl": "https://camera:443/rtplive/dfdf/playlist.m3u8",
"Disabled":true, "Blocked":false
}- We then ingest the image from the camera URL endpoint for the camera image:

- After we run it through Ultralytics YOLO, we will get a marked-up version of that camera image.

NOAA Weather Current Conditions for Lat/Long
We also ingest a REST feed for weather conditions meeting latitude and longitude passed in from the camera record that includes elevation, observation date, wind speed, wind direction, visibility, relative humidity, and temperature.
"currentobservation":{
"id":"KLGA",
"name":"New York, La Guardia Airport",
"elev":"20",
"latitude":"40.78",
"longitude":"-73.88",
"Date":"27 Aug 16:51 pm EDT",
"Temp":"83",
"Dewp":"60",
"Relh":"46",
"Winds":"14",
"Windd":"150",
"Gust":"NA",
"Weather":"Partly Cloudy",
"Weatherimage":"sct.png",
"Visibility":"10.00",
"Altimeter":"1017.1",
"SLP":"30.04",
"timezone":"EDT",
"state":"NY",
"WindChill":"NA"
}Ingest and Enrichment
- We will ingest data from the NY REST feed in our Python loading script.
- In our streetcams.py Python script does our ingest, processing, and enrichment.
- We iterate through the JSON results from the REST call then enrich, update, run Yolo predict, then we run a NOAA Weather lookup on the latitude and longitude provided.
Build a Milvus Data Schema
- We will name our collection: "nycstreetcameras".
- We add fields for metadata, a primary key, and vectors.
- We have a lot of varchar variables for things like
roadwayname,county, andweathername.
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='latitude', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='longitude', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='name', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='roadwayname', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='directionoftravel', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='videourl', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='url', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='filepath', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='creationdate', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='areadescription', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='elevation', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='county', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='metar', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='weatherid', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='weathername', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='observationdate', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='temperature', dtype=DataType.FLOAT),
FieldSchema(name='dewpoint', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='relativehumidity', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='windspeed', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='winddirection', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='gust', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='weather', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='visibility', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='altimeter', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='slp', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='timezone', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='state', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='windchill', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name='weatherdetails', dtype=DataType.VARCHAR, max_length=8000),
FieldSchema(name='image_vector', dtype=DataType.FLOAT_VECTOR, dim=512),
FieldSchema(name='weather_text_vector', dtype=DataType.FLOAT_VECTOR, dim=384)The two vectors are image_vector and weather_text_vector, which contain an image vector and text vector. We add an index for the primary key id and for each vector. We have a lot of options for these indexes and they can greatly improve performance.
Insert Data Into Milvus
We then do a simple insert into our collection with our scalar fields matching the schema name and type. We have to run an embedding function on our image and weather text before inserting. Then we have inserted our record.
We can then check our data with Attu.
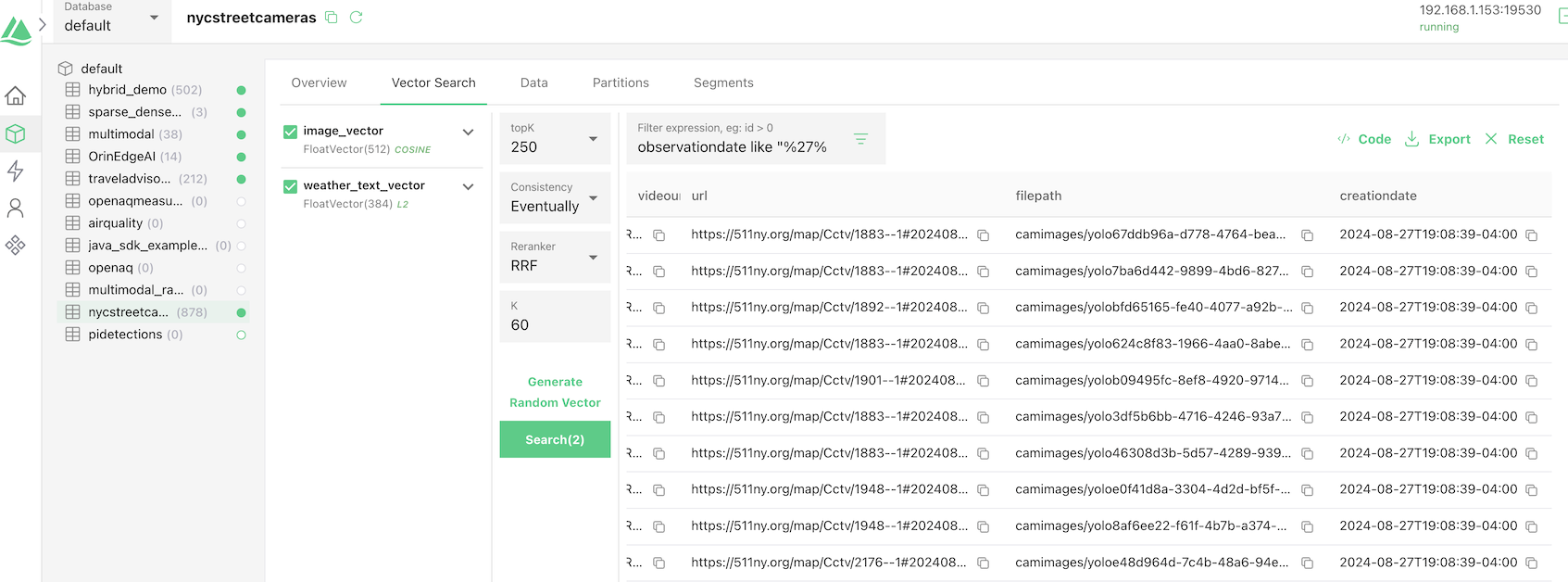
Building a Notebook for Report
We will build a Jupyter notebook to query and report on our multi-vector dataset.
Prepare Hugging Face Sentence Transformers for Embedding Sentence Text
We utilize a model from Hugging Face, "all-MiniLM-L6-v2", a sentence transformer to build our Dense embedding for our short text strings. This text is a short description of the weather details for the nearest location to our street camera.
Prepare Embedding Model for Images
We utilize a standard resnet34 Pytorch feature extractor that we often use for images.
Instantiate Milvus
As stated earlier, Milvus is a popular open-source vector database that powers AI applications with highly performant and scalable vector similarity search.
- For our example, we are connecting to Milvus running in Docker.
- Setting the URI as a local file, e.g.,
./milvus.db, is the most convenient method, as it automatically utilizes Milvus Lite to store all data in this file. - If you have a large scale of data, say more than a million vectors, you can set up a more performant Milvus server on Docker or Kubernetes. In this setup, please use the server URI, e.g.
http://localhost:19530, as your uri. - If you want to use Zilliz Cloud, the fully managed cloud service for Milvus, adjust the URI and token, which correspond to the Public Endpoint and API key in Zilliz Cloud.
Prepare Our Search
We are building two searches (AnnSearchRequest) to combine together for a hybrid search which will include a reranker.
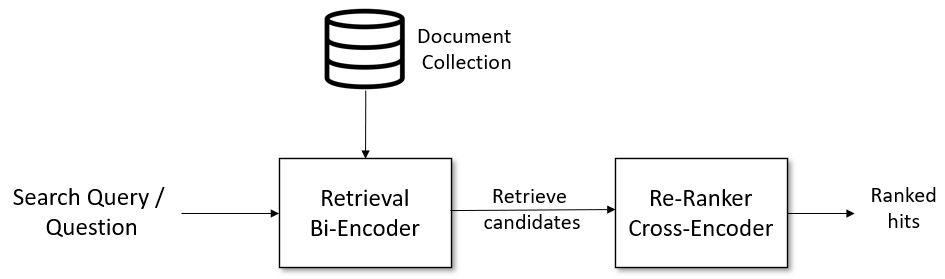
Display Our Results
We display the results of our re-ranked hybrid search of two vectors. We show some of the output scalar fields and an image we read from the stored path.
The results from our hybrid search can be iterated and we can easily access all the output fields we choose. filepath contains the link to the locally stored image and can be accessed from the key.entity.filepath. The key contains all our results, while key.entity has all of our output fields chosen in our hybrid search in the previous step.
We iterate through our re-ranked results and display the image and our weather details.

RAG Application
Since we have loaded a collection with weather data, we can use that as part of a RAG (Retrieval Augmented Generation). We will build a completely open-source RAG application utilizing the local Ollama, LangChain, and Milvus.
- We set up our
vector_storeas Milvus with our collection.
vector_store = Milvus(
embedding_function=embeddings,
collection_name="CollectionName",
primary_field = "id",
vector_field = "weather_text_vector",
text_field="weatherdetails",
connection_args={"uri": "https://localhost:19530"},
)- We then connect to Ollama.
llm = Ollama(
model="llama3",
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
stop=["<|eot_id|>"],
)- We prompt for interacting questions.
query = input("\nQuery: ")- We set up a
RetrievalQAconnection between our LLM and our vector store. We pass in ourqueryand get theresult.
qa_chain = RetrievalQA.from_chain_type(
llm, retriever=vector_store.as_retriever(collection = SC_COLLECTION_NAME))
result = qa_chain({"query": query})
resultforslack = str(result["result"])- We then post the results to a Slack channel.
response = client.chat_postMessage(channel="C06NE1FU6SE", text="",
blocks=[{"type": "section",
"text": {"type": "mrkdwn",
"text": str(query) +
" \n\n" }},
{"type": "divider"},
{"type": "section","text":
{"type": "mrkdwn","text":
str(resultforslack) +"\n" }}]
)Below is the output from our chat to Slack.
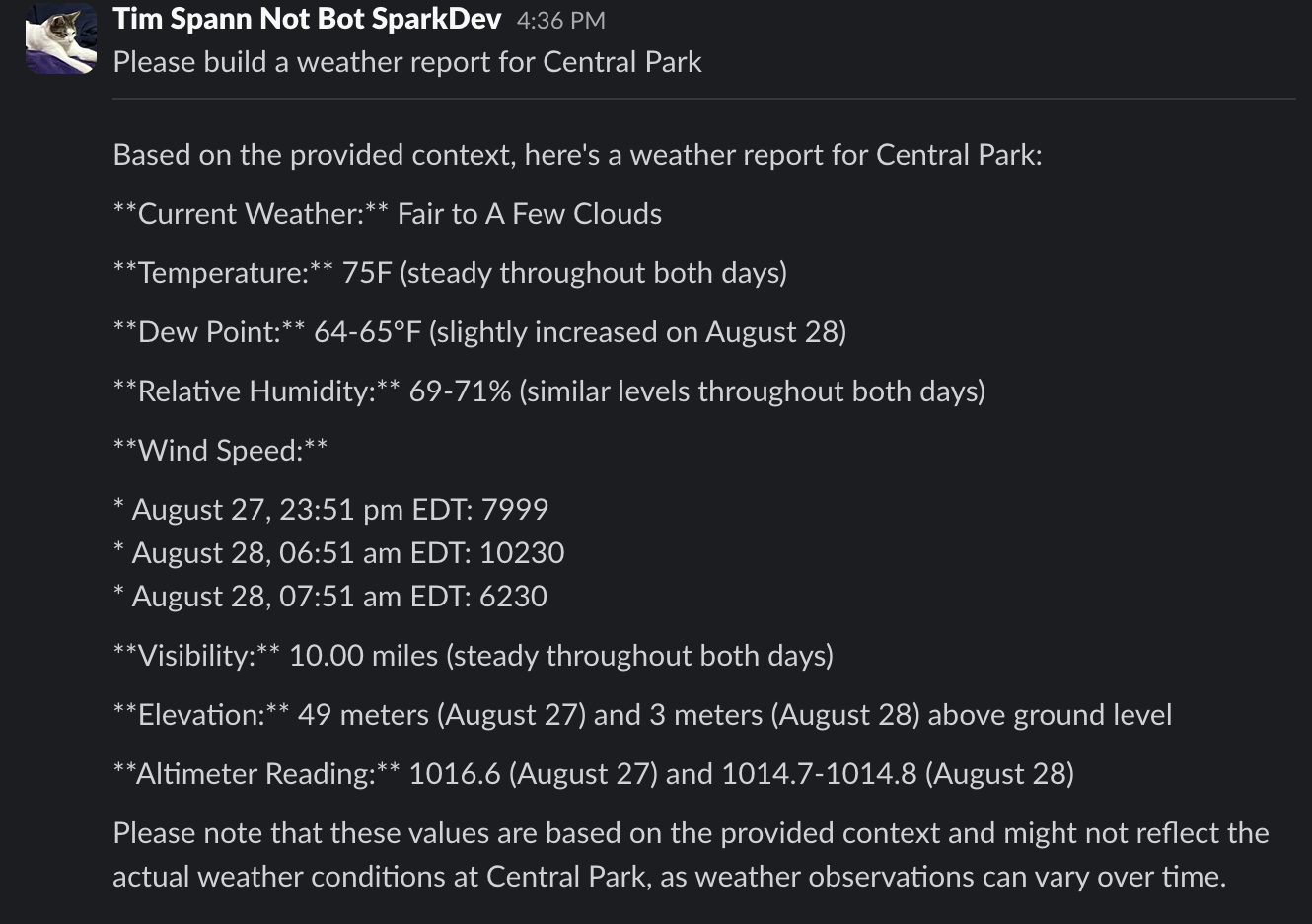
You can find all the source code for the notebook, the ingest script, and the interactive RAG application in GitHub below.
Conclusion
In this notebook, you have seen how you can use Milvus to do a hybrid search on multiple vectors in the same collection and re-ranking the results. You also saw how to build a complex data modal that includes multiple vectors and many scalar fields that represent a lot of metadata related to our data.
You learned how to ingest JSON, images, and text to Milvus with Python.
And finally, we built a small chat application to check out the weather for locations near traffic cameras.
To build your own applications, please check out the resources below.
Resources
In the following list, you can find resources helpful in learning more about using pre-trained embedding models for Milvus, performing searches on text data, and a great example notebook for embedding functions.
- Milvus Reranking
- Milvus Hybrid Search
- 511NY: GET api/GetCameras
- Using PyMilvus's Model To Generate Text Embeddings
- HuggingFace: sentence-transformers/all-MiniLM-L6-v2
- Pretrained Models
- Milvus: SentenceTransformerEmbeddingFunction
- Vectorizing JSON Data with Milvus for Similarity Search
- Milvus: Scalar Index
- Milvus: In-memory Index
- Milvus: On-disk Index
- GPU Index
- Not Every Field is Just Text, Numbers, or Vectors
- How good is Quantization in Milvus?
Opinions expressed by DZone contributors are their own.
Comments