Leveraging Apache Airflow on AWS EKS (Part 2): Implementing Data Orchestration Solutions
In part two of this series, take an in-depth look at Apache Airflow, and how it can address the problem of orchestrating cloud-based data.
Join the DZone community and get the full member experience.
Join For FreeIn contrast to existing studies, this series of articles systematically addresses the integration of Apache Airflow on AWS EKS, delving into enhancing process capability with Snowflake, Terraform, and Data Build Tool to manage cloud data workflows. This article aims to fill this void by providing a nuanced understanding of how these technologies synergize.
1. Setting up Apache Airflow on AWS EKS
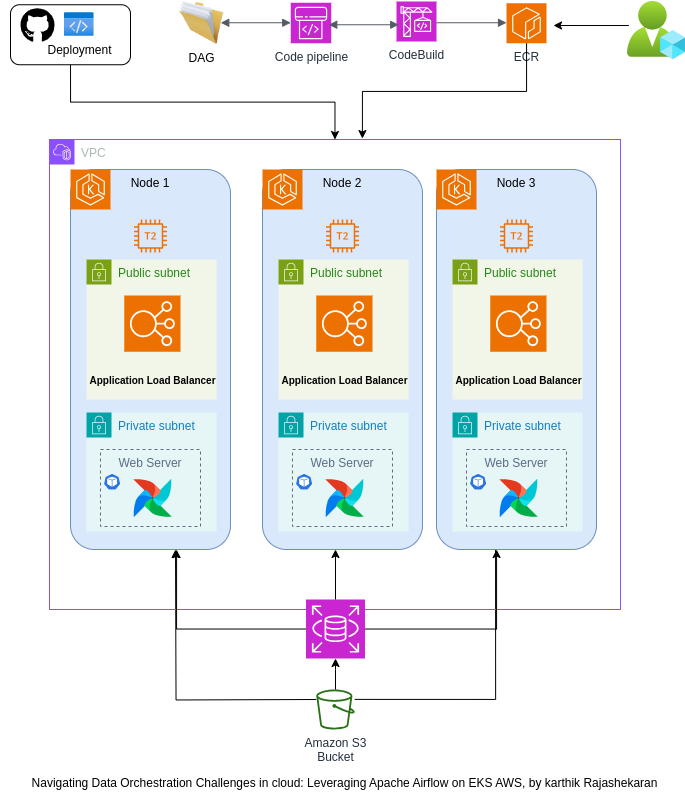
Figure 1: Architectural overview of Apache Airflow on AWS EKS
At the end of this section, we should archive the architecture overview designed above. The first thing to do is to get our Apache Airflow up and running with the helm.
2. Deploying Apache Airflow on AWS EKS With Helm
Helm is the Kubernetes package manager. It helps to deploy applications or services in Kubernetes, and manage complex Kubernetes applications by providing a templating system for defining, installing, and upgrading even the most intricate Kubernetes manifests.
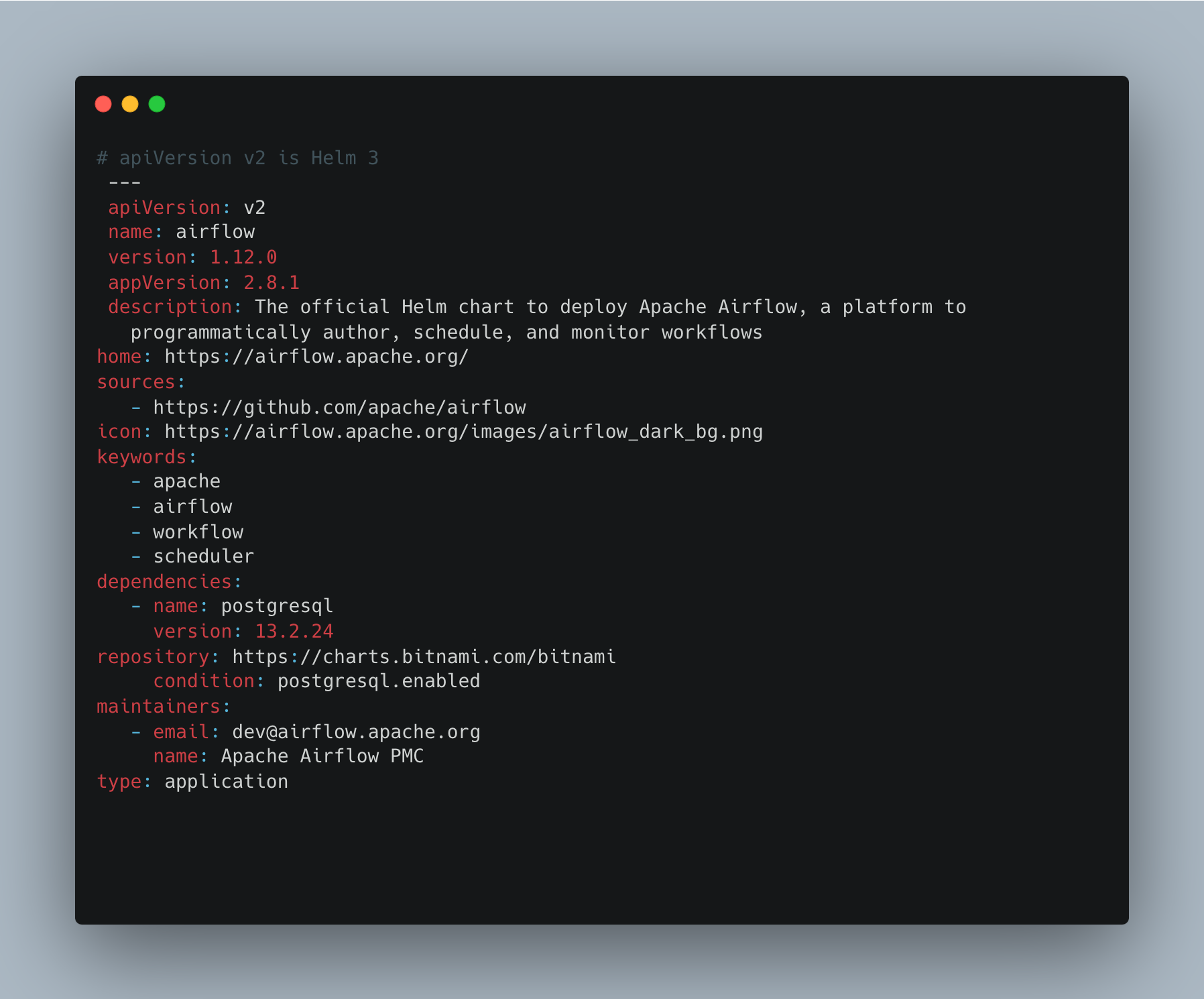
To deploy Apache Airflow on the EKS cluster, we will use a curated Helm chart provided by the Apache Airflow project. This chart encapsulates the necessary configurations and resources for deploying Airflow components like the web server, scheduler, and workers. In this article, we only use the official Helm chart from Airflow.
Before we move ahead from this point, take a look at the GitHub repository for the Apache Airflow helm chart.
All files here are “.yaml” files, the “chart.yaml” is an important file stating the version and the requirement which the installation will satisfy.
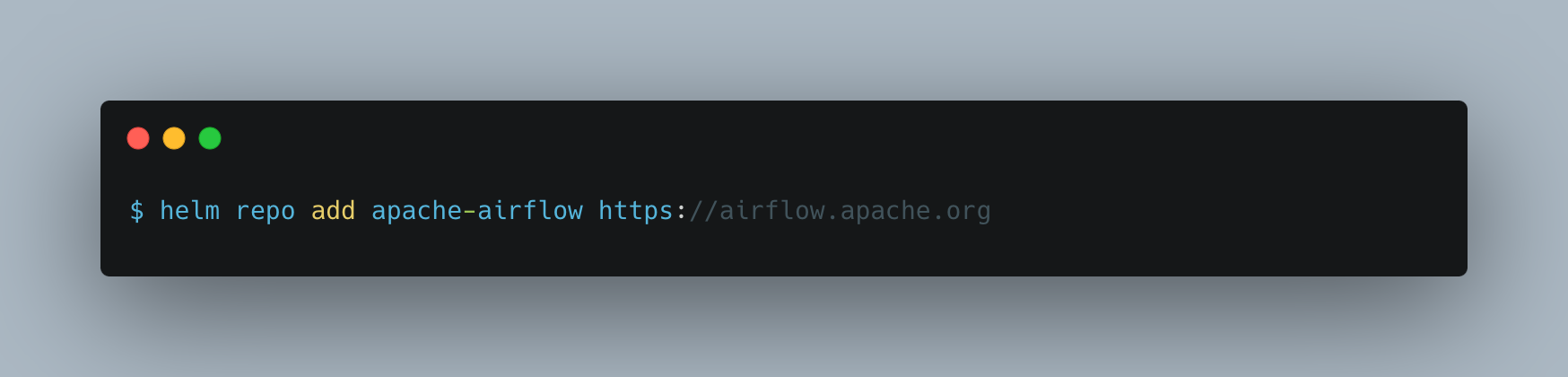
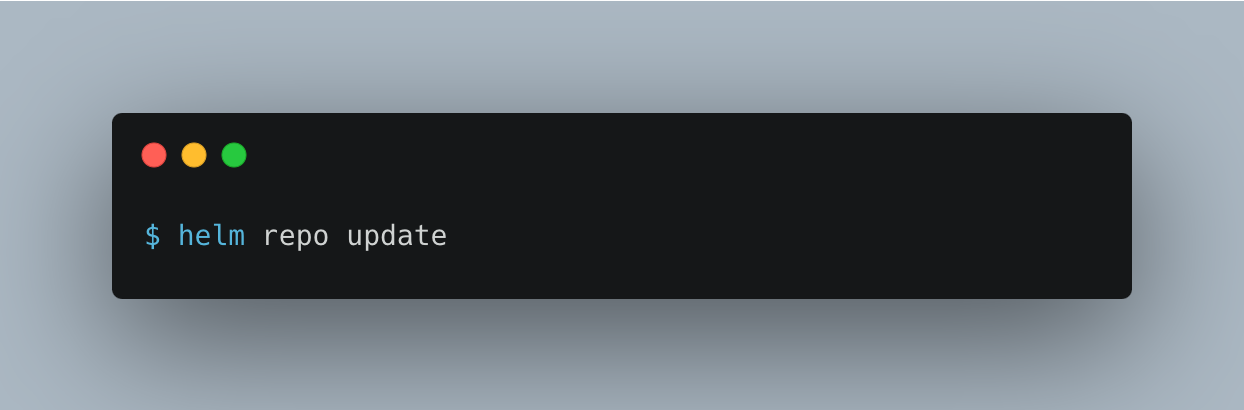
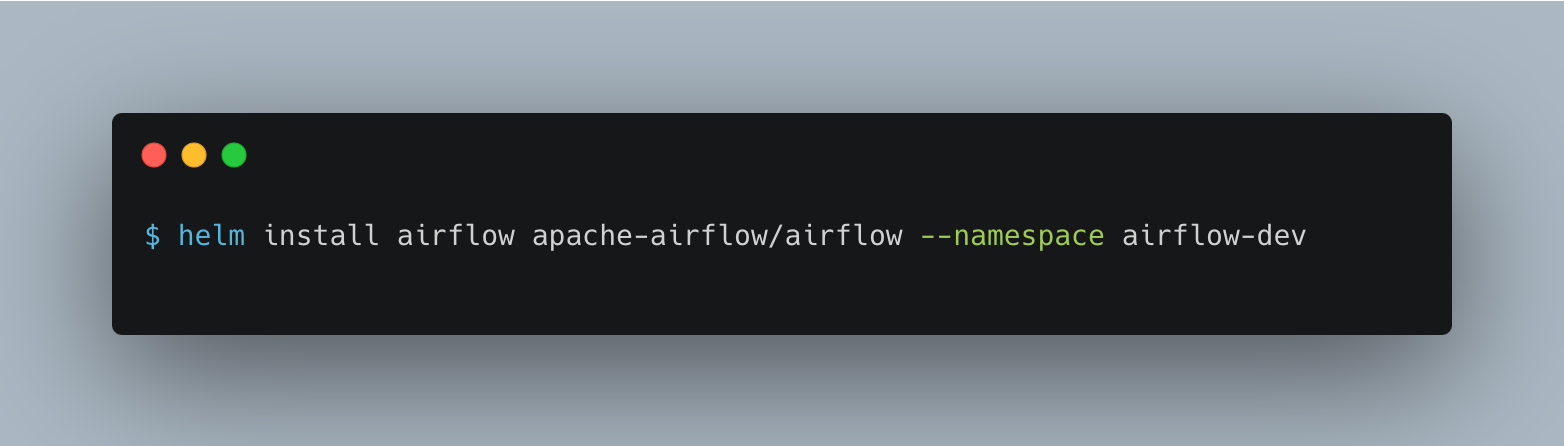
The following command will deploy Airflow on the EKS cluster with the default configuration of the official Airflow helm chat.
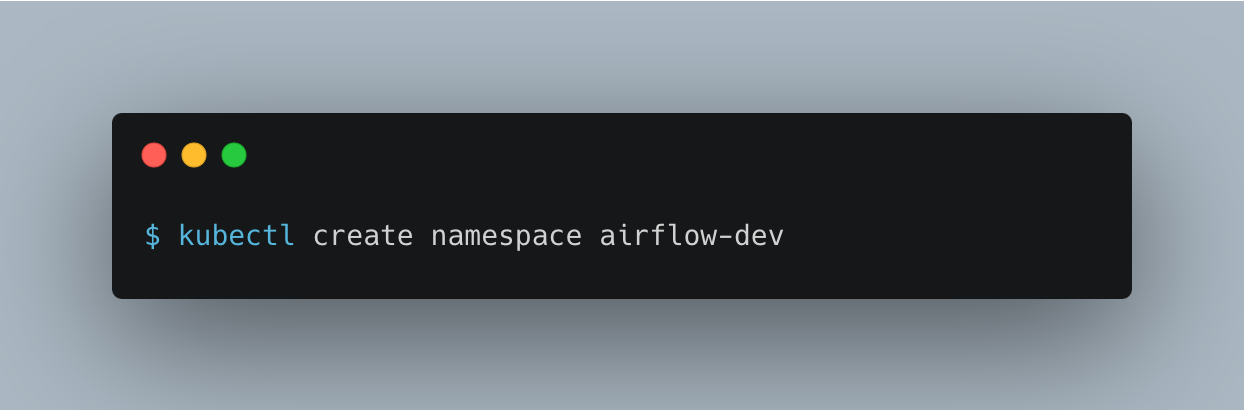
Installing Apache Airflow now, we have the command below, the “airflow-dev” is the namespace where the deployment will reside.
3. Integration of Snowflake With Apache Airflow on EKS
Combining Snowflake with Apache Airflow and Kubernetes (EKS or any Kubernetes frameworks) is a strong foundation for adopting data workflows by providing robust and scalable solutions. This integration makes it possible for you to automate, schedule, and monitor all data-related operations, including loading of data into Snowflake, data transformation, as well as other data pipeline tasks. Read on for a brief rundown of how you can go about getting both to work together.
Snowflake is a cloud-based data warehouse that is designed to take care of many data handling and analysis side functions that do not have to be done manually so that the system will be scalable and efficient. It delivers a service in the cloud with the advantage of the ability to store, process, and analyze data hardly demanding on-premises infrastructure. Snowflake processes data the same way other relational databases do utilizing databases, schemas, tables, and stages.
Data has a form that could be configured either structured or semi-structured preferably because most of the formats can be used with JSON, Avro, and Parquet, among others. Snowflake is one of the preferred analytics tools for companies who intend to avail the advantage of cloud-based analytics.
3.1. Setting up Snowflake Connection in Apache Airflow
By integrating Snowflake with Apache Airflow, you create a powerful data orchestration solution that combines the strengths of a cloud-native data warehouse with flexibility and scalability in running and monitoring the status of SQL queries, loading, and exporting data.
To set up a Snowflake connection in Apache Airflow, we need to define a connection in the Airflow UI or use the Airflow CLI. Here is a guide on how to set up a Snowflake connection using the Airflow UI:
Navigate to the Airflow web interface.
- Go to the "Admin" tab and select "Connections."
- Click on the "Create" button to add a new connection.
Fill in the connection details:
- Conn Id: Provide a unique identifier for the connection (e.g. snowflake_conn).
- Conn Type: Select Snowflake.
- Host: Your Snowflake account URL.
- Login: Your Snowflake username.
- Password: Your Snowflake password.
- Schema: Default Snowflake schema.
- Database: Your Snowflake database.
- Warehouse: Your Snowflake warehouse.
Save the connection.
Setting up the following requires you to have a Snowflake account, role, Database, and Warehouse.
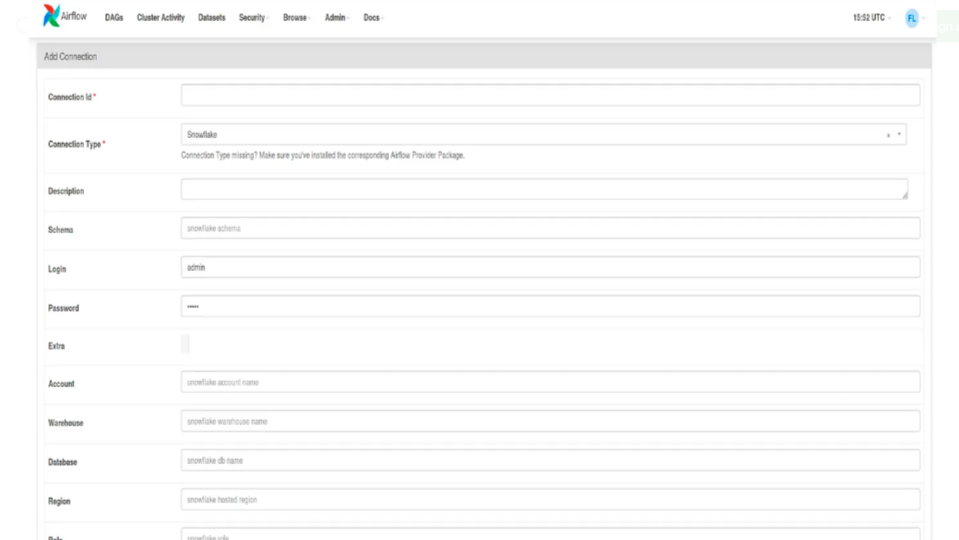
Figure 2: Snowflake account, role, Database, and Warehouse.
3.2. Benefits of Connecting Snowflake With Apache Airflow
Using Snowflake in AWS EKS provides several advantages, leveraging both technologies' strengths. Here are the key advantages of utilizing Snowflake in this specific environment:
- Integration with AWS Services: Snowflake is set up and works with multiple AWS services in a smooth and trouble-free mode. This integration is comprised of Amazon S3 for data storage, AWS IAM for security purposes, and AWS KMS technology for encryption.
- Scalability and Elasticity: Snowflake scalability supports the fact that the scalability of AWS is elastic. Users can easily scale compute resources up or down in line with the workload conditions thus efficiency in resource utilization while performance is high is guaranteed.
- Managed service: Snowflake is a fully managed data warehousing solution. This means that AWS customers can leverage Snowflake without the need to manage the underlying infrastructure. This reduces the operational burden on teams and allows them to focus on data analytics and insights.
- Multi-Availability Zone (Multi-AZ) Deployment: Snowflake is promoted to automatically replicate in additional availability zones at each region of the AWS. The SS allows to correct errors, increases the availability, and manages to tolerate the problems and network downtimes. Snowflake deploys used in numerous zones in every region of AWS.
- Data sharing and collaboration: The data-sharing feature of Snowflake which is ideal for collaborative data analytics makes it possible for data analysts to share and analyze data in real-time. It empowers the public and simple sharing of data among different Snowflake subscribers and thus organizations can work as one entity on analytics without losing any piece of information.
- Security and compliance: Snowflake uses AWS security features and also strengthens those by providing end-to-end encryption, role-based access control (RBAC), and audit trails. Through this, it becomes an apt one to be used by organizations with extremely rigorous security and compliance specifications.
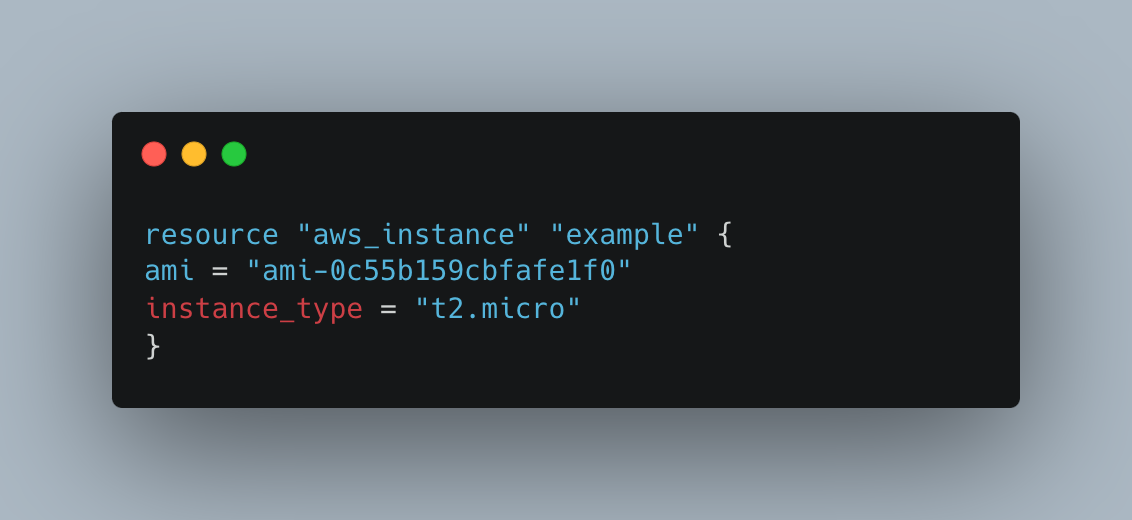
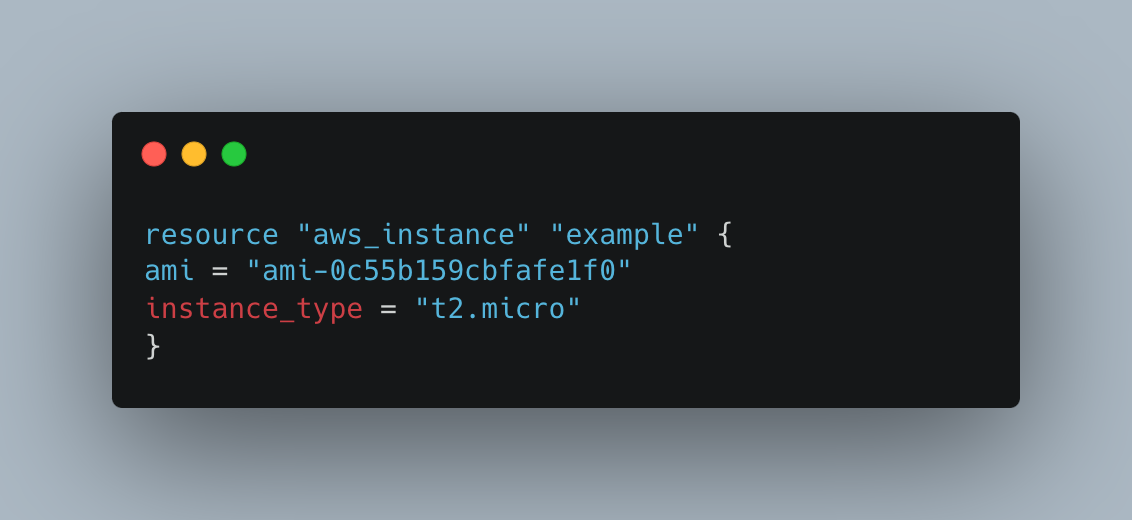
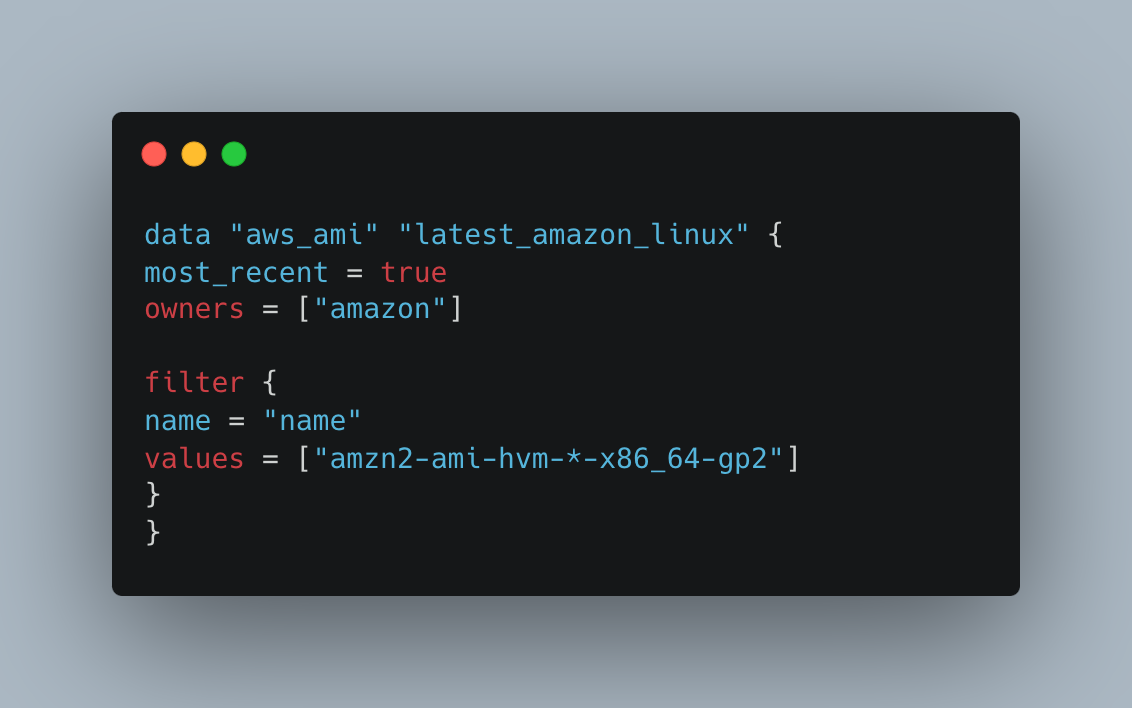
4. Terraform for EKS Infrastructure
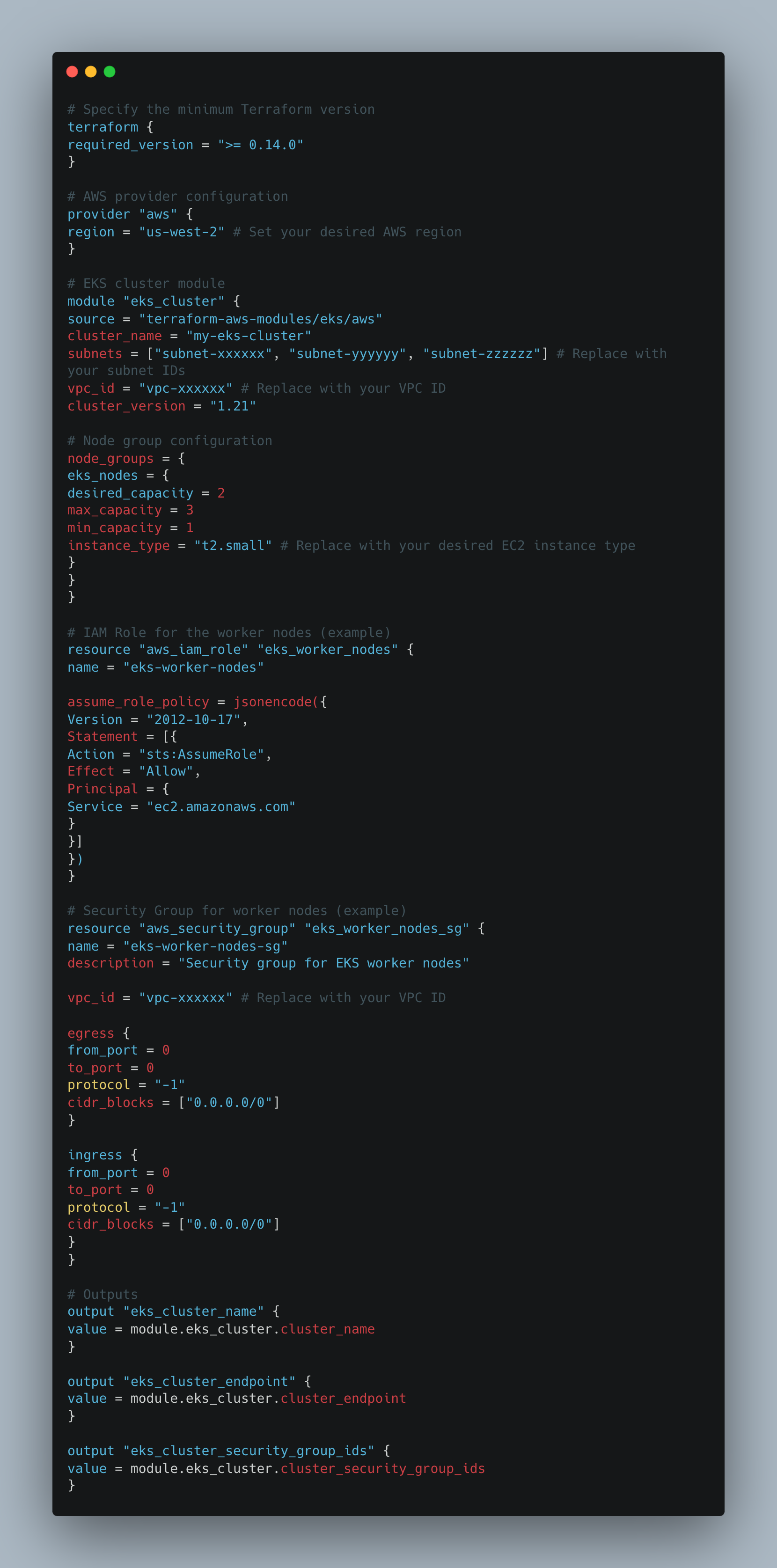
Terraform is a configuration management tool using the Infrastructure as Code (IaC) paradigm, so it lets you define, provision, and manage your infrastructure resources in a declarative way. What is amazing about Amazon EKS (Elastic Kubernetes Service) and Terraform is that the former can be employed for automated provisioning of the infrastructure components needed while the latter can inform the latter to declare the whole Infrastructure as a code that can be easily deployed on any other platform without missing the same process. The Terraform code below is used to create an infrastructure for EKS (Elastic Kubernetes Service) on AWS. In the example, their creation of an EKS cluster including worker nodes and necessary networking solutions was done.
 The fundamental idea of the Terraform workflow consists of several major steps such as digitizing infrastructures in form of the codes, making changes, applying them, and lifecycle state change management.
The fundamental idea of the Terraform workflow consists of several major steps such as digitizing infrastructures in form of the codes, making changes, applying them, and lifecycle state change management.

Figure 3: Source:https://k21academy.com/
- Configuration language: Terraform utilizes HashiCorp Config Language (HCL) to define Infrastructure as Code laying out relations and dependencies. HCL is a human-readable language, which makes it a lot easier to express the desired situation within the infrastructure.
- Terraform configuration file (*.tf): Infrastructure means structuring in the configuration file which is declared with Terraform at least once. These files with a .tf extension (which goes for resource definitions, provider configurations, and others) most of the time are the ones used.
- Provider configuration: For Terraform to work with different cloud or infrastructure providers (e.g., AWS, Azure, GCP), it uses providers. The way configurations are set up by the provider specifies the necessary authentication and settings for the provider.

- Resource declarations: Resources mean infrastructure resources (such as virtual machines, and databases) that are administered by Terraform. Users invent resources and their configurations in the Terraform configuration plain-text files.
- Variables and input parameters: The users may adapt their parameters through the use of variables, broadening the range of possibilities. Also, Terraform uses input variables that can be defined and then provided values when running the Terraform commands.
- Initializing Terraform: Users must initialize the working directory via the Terraform init command before using a Terraform configuration. This downloads the required provider plugins and begins working director.
- Executing Terraform commands: Key Terraform commands include:
terraform plan: Generates an execution plan describing what Terraform will do without making any changes.terraform apply: Applies the changes described in a Terraform execution plan.terraform destroy: Destroys the infrastructure managed by Terraform.- State management: Terraform maintains a state file (terraform.tfstate) that records the current state of the infrastructure. This file is critical for tracking resources, and dependencies, and preventing conflicts.
- Output values: Output blocks contain values to be passed as a reference or parameter to some external process. These are outside of the Terraform configuration. Some of the examples of the values that might be gathered include IP addresses, DNS names, and other data that can be further collected.
- Plan: This terraform command plan checks the present configuration, compares it with the state file, and then proposes what are its execution steps. The plan consists of the planned activities that Terraform will apply to reach the desired state.
- Apply: The terraform apply command is used to execute the changes proposed in the plan. It modifies the infrastructure to match the desired state.
- Destroy: The Terraform destroys command is used to get rid of the defined resources in line with the Terraform configuration. It is a way of avoiding penalties and eliminating the emergence of extraneous costs.
- Modules: Modules are a way to organize and encapsulate Terraform configurations. They allow you to create reusable components that can be used across different projects.
- Remote State: Remote state allows you to store the state file remotely, making it accessible to a team. This is useful for collaboration and maintaining a shared state.
These concepts collectively form the Terraform workflow, providing a structured and repeatable approach to managing infrastructure across different cloud platforms.
5. DBT (Data Build Tool)
Data Build Tool takes center stage in the sphere of data transformation as an open-source software that is focused on revolutionizing data warehouse transformation by blending effectiveness and cooperation DBT is a command line tool that imparts higher efficiency of data transformation among analysts and engineers of the warehouses. It works especially well in coordination with data storage solutions such as Snowflake, BigQuery, Redshift, and Azure.
Here are key aspects of DBT's role in data transformation:
- Modularization and reusability: DBT allows you to modularize your transformation logic into reusable units known as DBT models. These models are SQL-based and represent transformations on your raw data, providing a clear separation between the raw data layer and the transformed data layer.
- Transformations as code: DBT is designed around SQL for describing transformations so it is convenient for those who know SQL which is used for the roles like engineers or data analysts. Rewriting will be conducted against your codebase that stores all the versions, which binds teamwork and commits for code review.
- Dependency management: One of the DBT model's working models can be tightly related to other models. This guarantees pathways and entails that every transformation is done in the right order which reduces the risk of data accumulation problems. One feature of DBT models can correspond to another model or method. This saves "the day" and does not allow lineage confusion, also there is no chance of incorrect ordering, and as a result data integrity issues are minimized.
- Incremental processing: DBT allows you to implement an incremental process, which is beneficial in that you only need to rebuild the new or modified parts of your data. As a result, thereof, the whole processing time is reduced as well the system maintains certain efficiency standards.
- Documentation and metadata: DBT automatically generates documentation for your data transformations, providing insights into the purpose and logic of each transformation. This promotes transparency and knowledge sharing within the team.
- Testing and validation: DBT, in addition to the feature mentioned earlier, contains a testing infrastructure that makes it possible to write unit and end-to-end tests for your data models to confirm that the transformations are correct. This aspect comes in handy since it helps in identifying mistakes in the earlier stages of the design.
- Collaboration and version control: DBT integrates with version control systems like Git and fosters a collaborative development environment. Teams can watch the transition processes, go back to previous versions, and work on the evolution of data transformations jointly.
- Execution and orchestrations: The DBT run command executes the defined transformations in your models, applying the logic to your raw data, and producing the transformed results in your data warehouse.
- Community and ecosystem: DBT counts as a thriving community and ecosystem. Developers can share DBT packages (user-defined collections of models), leveraging best practices and pre-built logic, which are deployed on the cloud and get exposed as web services to be consumed by any client that deems appropriate.
DBT becomes a very useful tool to change and organize data in a data warehouse. It calls for relationships, repeatability, and best practices while data transformation workflows, thereby being a great tool for data teams involved in analytics and reports.
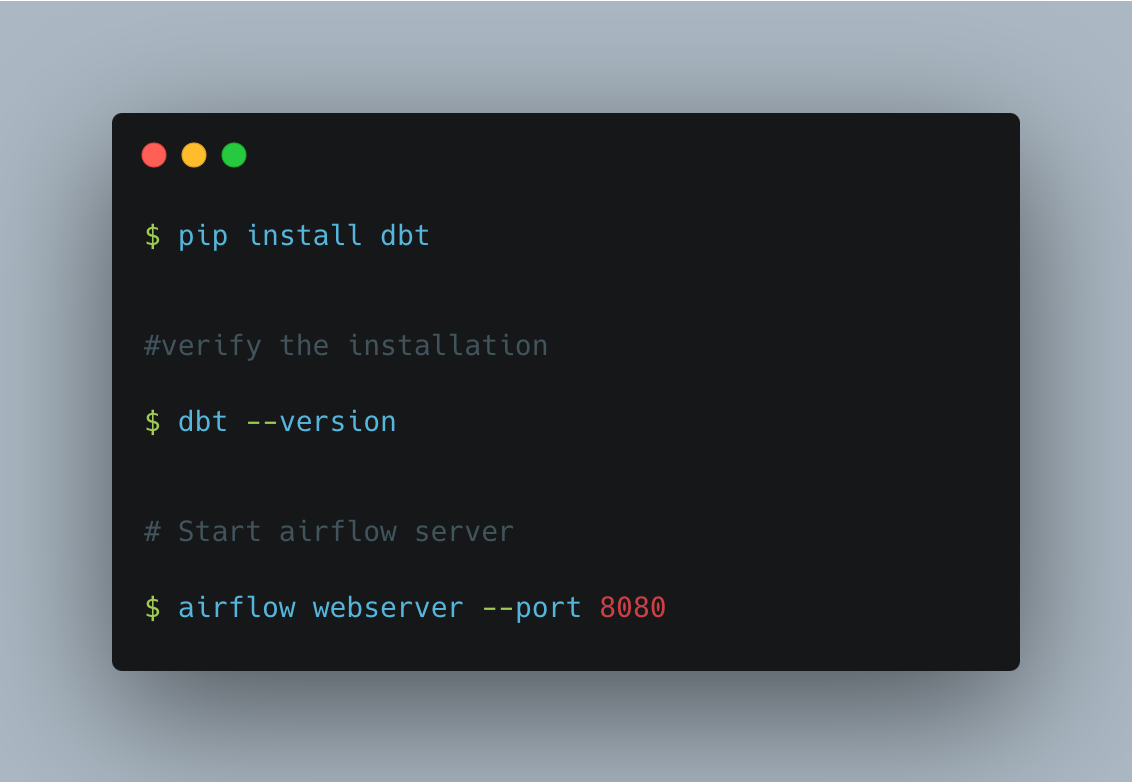
5.1. Integration of DBT with Apache Airflow on EKS
Implementing the DBT (Data Build Tool) with Apache Airflow is one of the approaches that will help you enhance the data orchestration and workflow management. Apache Airflow becomes the scheduler, monitor, and executing tool for your DBT runs, making the whole pipeline more coordinated and working together. Here we will provide a brief introduction to how you can implement DBT with Apache Airflow, you have Apache Airflow installed already. A further step is to install DBT as follows.
From the Apache Airflow web interface.
Navigate to Connections:
Click on the "Admin" tab in the top navigation bar.
Select "Connections" from the drop-down menu.
Add a New Connection:
Click on the "Create" button to add a new connection.
Fill in Connection Details:
Set the following connection parameters:
- Conn Id: A unique identifier for the connection e.g., “dbt_conn”.
- Conn Type: Choose the appropriate connection type e.g. “HTTP”.
- Host: The host or endpoint of your data warehouse.
- Login: Your data warehouse username.
- Password: Your data warehouse password or API token.
Additionally, you might need to specify other parameters based on your data warehouse type and specific requirements.
Click the "Save" button to save the new connection. By following these steps, you have successfully set up your environment installing dbt and connecting with Airflow.
6. Best Practices for Using DBT in Cloud-Based, EKS Cluster
One of the key practices is to stay lean and focused and to maintain collaboration for the section to be accomplished. I have utilized phrases such as “the shared view of the experienced DBT users about its applicability in the analytics work” to emphasize this point. The following offers some ways of implementing dbt in a cloud data warehouse such as Snowflake.
6.1. Project Organization
- Modularization with folders and subfolders: This is a usual practice to organize your dbt project into folders and subfolders to group related models together. This helps maintain a clear and logical structure.
- Use version control: Store your dbt project in a version control system (e.g., Git). This enables collaboration, code reviews, and the ability to roll back changes if needed.
- Environment variables: Utilize environment variables for configuration parameters that may vary across environments, enhancing flexibility and security.
6.2. Modeling Best Practices
- Atomic models: Follow the principle of atomic modeling, where each DBT model represents a single logical transformation. This promotes reusability and clarity.
- Incremental models: Large datasets slow down the performance, hence using incremental processing will increase the efficiency. It means that only the data, which was changed while keeping all the unchanged data, is replaced instead of recomputing the whole thing.
- Documentation: You have to document your dbt models thoroughly. Use descriptions, tags, and tests to provide context and information for other users.
- Testing: Ensure accuracy by implementing tests for your transformed instances. Here, such tests include a schema test, data validation test, and custom tests according to your business rules. Identify the correctness of your transformations by running the tests.
6.3. Dependency Management
- Explicit dependencies: Specify explicit dependencies between models using the ref function. This ensures that models are built in the correct order, minimizing errors.
- Use source freshness: Leverage source freshness tests to ensure that your dbt models are not built on stale data.
6.4. Security
- Secure credential handling: Handle credentials securely. Avoid hardcoding credentials in your models. Instead, use DBT's built-in credential management or other secure methods provided by your cloud platform.
- Role-based access control: Leverage the role-based access control mechanisms provided by your data warehouse to restrict access to data based on user roles.
6.5. Performance Optimization
- Use materializations wisely: Choose the appropriate materialization strategy (e.g., view, table) based on the use case and data volume. Views are more suitable for small datasets, while tables are more performant for larger ones.
- Optimize for cloud warehouse: Consider cloud warehouse-specific optimizations. For example, leverage Snowflake's clustering keys or BigQuery's partitioned tables for better performance.
6.6. Monitoring and Logging
- Integrate with logging services: Integrate DBT with logging services to monitor and log transformations. This can help in identifying issues, analyzing performance, and tracking changes.
- Airflow integration: Integrate DBT runs into Airflow DAGs for centralized management and monitoring.
6.7. Continuous Integration (CI) and Continuous Deployment (CD)
- CI/CD Pipelines: Implement CI/CD pipelines for your dbt project. Automate testing and deployment processes to ensure consistent and reliable releases.
- Use DBT Cloud (Optional): Consider using DBT Cloud for managed DBT runs, scheduling, and collaboration. It provides a centralized platform for managing DBT in the cloud.
6.8. Community Involvement
- Leverage DBT Community: Engage with the DBT community for support, best practices, and sharing knowledge. The DBT community is active and can provide valuable insights.
Following these best practices, you can maximize the benefits of using dbt in a cloud-based environment, ensuring a robust and scalable data transformation process.
7. Conclusion
In conclusion, a cloud-run space environment that combines different data management and transformation tools is powerful since it allows for data workflows to be handled efficiently. Installation of Apache Airflow on AWS EKS expedites and standardizes the workflow management process, whereas the application of Terraform ensures programmatic provisioning of infrastructure objects needed for it. Making use of Airflow of Snowflake, the cloud-based analytics are made scalable and efficient together with the consolidation of data.
In addition, DBT gives rise to a powerful transformation tool that provides four major benefits, such as modularization, collaboration, and best practice. Through the integration of DBT with Apache Airflow on EKS, there is an addition to the data orchestration capabilities which ultimately brings about a smooth workflow from data ingestion to transformation and analysis. Inheriting these best practices, for instance, project organization, modeling efficiency, modeling dependency, and security, guarantees the robustness and scalability of data pipelines.
Continuous monitoring, logging, and integration of CI/CD pipelines perfect the data workflow, so it stays consistent and credible during the data transformation processes. Collectively, these tools, alongside the establishment of the best practice standards help organizations deliver the cloud-based infrastructure in an interactive, scalable, and granular way.
References
- A. Cepuc, R. Botez, O. Craciun, I. -A. Ivanciu and V. Dobrota, "Implementation of a Continuous Integration and Deployment Pipeline for Containerized Applications in Amazon Web Services Using Jenkins, Ansible, and Kubernetes," 2020 19th RoEduNet Conference: Networking in Education and Research (RoEduNet), Bucharest, Romania, 2020, pp. 1-6, doi: 10.1109/RoEduNet51892.2020.9324857.
- Finnigan, L., & Toner, E. “Building and Maintaining Metadata Aggregation Workflows Using Apache Airflow” Temple University Libraries Code4Lib, 52. (2021).
- K. Allam, M. Ankam, and M. Nalmala, “Cloud Data Warehousing: How Snowflake Is Transforming Big Data Management”, International Journal of Computer Engineering and Technology (IJCET), Vol.14, Issue 3, 2023.
- DBT Lab In, “Best practices for workflows | DBT Developer Hub.” Accessed: 2024-02-15 12:25:55
- Amazon Web Services, “What Is Amazon Managed Workflows for Apache Airflow? - Amazon Managed Workflows for Apache Airflow." Accessed: 2024-02-15 01:08:48 [online]
- The Apache Software Foundation, “What is Airflow™? — Airflow Documentation.” Accessed: 2024-02-15 01:10:52 [online]
- Baskaran Sriram, “Concepts behind pipeline automation with Airflow and go through the code..” Accessed: 2024-02-15 [online].
- Medium, “Airflow 101: Start automating your batch workflows with ease.” Accessed: 2024-02-15 [online].
- Astronomer, “Install the Astro CLI | Astronomer Documentation.” Accessed: 2024-02-15 12:12:28 [online]
- Amazon Web Services, “Creating an Amazon EKS cluster - Amazon EKS.” Accessed: 2024-02-15 12:25:17 [online]
- “Create a Snowflake Connection in Airflow | Astronomer Documentation.” Accessed:2024-02-15 01:07:15 [online]
- “Airflow Snowflake Integration Guide — Restack.” Accessed:2024-02-15 [online]
- Dhiraj Patra “(27) Data Pipeline with Apache Airflow and AWS | LinkedIn.” Accessed: 2024-02-15 01:09:37 [online]
Opinions expressed by DZone contributors are their own.
Comments