Navigating the CAP Theorem: In Search of the Perfect Database
This article debunks the myth of a perfect database, explaining that no type can fully achieve Consistency, Availability, and Partition Tolerance at once. "
Join the DZone community and get the full member experience.
Join For FreeThe CAP Theorem is a foundational concept in the world of distributed computing, particularly for databases. Developed by Eric Brewer, it challenges us to understand that in any network of databases, we can’t have the perfect combination of three key features at the same time: Consistency (all nodes show the same data), Availability (every request receives a response), and Partition Tolerance (the system continues to operate despite network failures).
Understanding Each Aspect of CAP
1. Consistency
This is about having the same data across all system parts at any given time.
- Strong Consistency: The system ensures every change is made across all nodes before moving forward.
- Eventual Consistency: This is less rigid. Although all nodes will eventually show the same data, they don’t do it simultaneously.
Different consistency models exist, ranging from very strict ones where data is always the same everywhere to more relaxed models where data can differ temporarily.
2. Availability
Availability means ensuring that every user request gets some kind of response, no matter what.
Systems focusing on high availability aim to be always operational, even if parts of the network fail.
The downside here is that to stay always on; these systems might give out old or not completely updated data during network problems.
3. Partition Tolerance
This refers to the system’s ability to keep running even when network issues cut off communication between different system parts.
Since network issues are a reality in distributed systems, being partition-tolerant is considered non-negotiable for distributed databases.
Database Types and the CAP Theorem
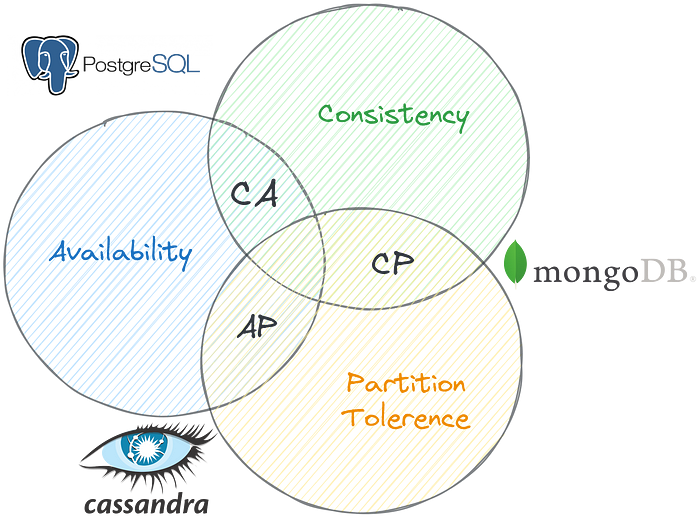
Introduction The CAP Theorem is a fundamental principle in the field of distributed databases. It posits that a database system can only excel in two out of three characteristics: Consistency ‘C,’ Availability ‘A,’ and Partition Tolerance ‘P.’ This limitation arises from the inherent constraints of networked systems and data management, where achieving perfect synchronization across all nodes (for consistency) might conflict with keeping the system always available, particularly during network failures.
If you are interested in a proof of that theorem, you can dive in here.
CA (Consistency and Availability) Databases
- Nature: Predominantly relational databases.
- Example: PostgreSQL
CA databases aim to provide both data consistency and availability under normal operating conditions. Every node in the system is both consistent with the others and available to handle requests. However, this balance is disrupted if a partition occurs. In such a scenario, a CA database cannot maintain its partition tolerance, leading to potential system failures or inaccessibility of certain nodes. Essentially, in the presence of a network partition, a CA database can no longer guarantee both consistency and availability across all nodes.
CP (Consistency and Partition Tolerance) Databases
- Nature: Often non-relational or NoSQL databases configured for strong consistency.
- Example: MongoDB is configured for strong consistency.
CP databases prioritize maintaining consistency and handling network partitions effectively. However, they need to improve on availability. In these systems, when a partition occurs between nodes, the inconsistent node (the one with possibly outdated or incorrect data) is made unavailable. This is done to maintain overall data integrity until the partition issue is resolved. Thus, CP databases ensure that the data remains accurate and synchronized across the network, but at the cost of potentially rendering parts of the system inaccessible during network disruptions.
AP (Availability and Partition Tolerance) Databases
- Nature: Typically non-relational or NoSQL databases.
- Example: Cassandra
AP databases focus on ensuring availability and handling network partitions. In the event of a partition, all nodes remain operational, but there’s a catch. Nodes on the ‘wrong’ side of the partition might serve older data. This means users can still access the database during a network partition but might not get the most recent data. Once the partition is resolved, AP databases initiate a synchronization process to rectify any inconsistencies across the system. These databases are designed to keep the system functional and accessible, even if it means temporarily compromising on having the latest data.
Conclusion
Understanding these nuances of CAP database types is crucial for architects and developers. It aids in selecting the right database type based on the specific operational needs and priorities of a system. While CP databases are ideal for scenarios where data accuracy is paramount, AP databases excel in environments where continuous operation is crucial. CA databases, meanwhile, offer a balance of consistency and availability but falter in the face of network partitions.
CAP Database Types: Aligning With Architecture and Requirements
Understanding the Relationship Choosing a database type in line with the CAP Theorem is a decision deeply rooted in the system’s architecture and its specific requirements. The architecture dictates the operational environment of the database, while the application requirements determine the necessary features and capabilities.
Architecture Considerations
The system's architecture, such as a monolithic, microservices, or hybrid structure, has a significant impact on the database choice. In a distributed setup like microservices, Partition Tolerance becomes a crucial aspect due to the likelihood of network partitions. On the other hand, in more centralized or monolithic structures, the emphasis may shift towards Consistency and Availability.
System Requirements
Different applications have varying data handling needs. Applications involving critical transactional data, like financial or inventory systems, often need databases prioritizing Consistency and Availability. Conversely, user-centric applications like social media or e-commerce platforms, where user experience depends on uninterrupted service, might find Availability and Partition Tolerance more essential.
CA Databases in Context
These databases are typically ideal for environments where data integrity is critical and network partitions are a manageable risk. They are well-suited for backend systems where scheduled downtime is acceptable and does not severely impact operations.
CP Databases in Context
CP databases shine in scenarios where maintaining data accuracy is paramount, even at the cost of temporary unavailability. They are often the choice for systems that require synchronized data across services, such as in complex transaction processing.
AP Databases in Context
AP databases are the go-to for large-scale applications where service continuity is key. They are particularly beneficial in distributed networks where the reliability of network connections might be inconsistent, ensuring the application remains operational.
Conclusion
In the world of distributed databases, the CAP Theorem teaches us an important lesson: there’s no perfect database that has it all. This means that any claim of a universal, one-size-fits-all database solution should be met with a healthy dose of skepticism.
Any claim of a universal, one-size-fits-all database solution should be met with a healthy dose of skepticism.
Every database, whether it’s CA, CP, or AP, comes with its own set of strengths and weaknesses. The CAP Theorem shows us that we can’t have total consistency, availability, and partition tolerance all at once. So, each type of database sacrifices one aspect to excel in the other two.
The job of architects and developers then becomes crucial and challenging. They need to understand the technical aspects of different databases and, more importantly, know what the application really needs. Does it need to be always on (Availability)? Does it need to have the most up-to-date information all the time (Consistency)? Or does it need to keep running no matter what happens in the network (Partition Tolerance)?
For example, a CA database might be great for systems where accurate data is crucial, and network issues are rare. On the other hand, an AP database would be better for user-facing applications where it’s more important to keep the service always running. CP databases fit well where up-to-date data is a must, even if it means some downtime.
In summary, choosing the right database is about finding the best fit for your specific situation and considering what you can or cannot compromise on. It’s about matching the database’s features with your application’s unique needs and challenges. Remember, in the world of databases guided by the CAP Theorem, being well-informed and realistic in your choices is key.
Published at DZone with permission of Pier-Jean MALANDRINO. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments