Advanced NLP-Powered Financial Ledger Reconciliation Using LangChain
This article explains how LangChain and NLP (Natural Language Processing) can help automate financial ledger reconciliation.
Join the DZone community and get the full member experience.
Join For FreeIn the world of finance, ensuring accuracy and compliance in financial records is a critical function. One of the key challenges faced by financial institutions is ledger reconciliation, which involves matching transactions across multiple data sources to detect inconsistencies, errors, and fraud. Traditional reconciliation methods, largely rule-based and manual, are often inefficient, slow, and unable to handle the vast amount of financial data generated daily.
Enter Natural Language Processing (NLP) and LangChain, a cutting-edge AI-powered framework that transforms ledger reconciliation through automation, enhanced accuracy, and anomaly detection. This article explores how LangChain leverages Large Language Models (LLMs) to improve financial ledger reconciliation, reduce manual effort, and enhance fraud detection.
The Challenge of Traditional Reconciliation
Financial reconciliation is a tedious process that requires identifying discrepancies between ledgers, bank statements, invoices, and other financial documents. Some key challenges include:
Financial records come in many different formats, such as CSV files, PDFs, emails, and databases, making it difficult to standardize and reconcile them efficiently. The lack of a common format increases complexity and slows down the reconciliation process. Additionally, transactions often have inconsistencies, such as varying descriptions, incorrect amounts, or missing details, requiring manual intervention to verify and correct the data. These discrepancies add to the overall effort needed for accurate financial reporting.
As financial data continues to grow, manual reconciliation methods become increasingly impractical, especially for large enterprises handling thousands of transactions daily. Traditional approaches struggle to scale, leading to delays and inefficiencies. Furthermore, detecting fraudulent transactions is challenging because fraudsters do not follow predictable patterns. Rule-based detection methods often fail to identify suspicious activities, making it necessary to adopt more advanced detection mechanisms.
Another major issue is the lack of context awareness in reconciliation systems. Many systems cannot fully understand the background of a transaction, leading to a high number of false positives in fraud detection. Without contextual intelligence, valid transactions are sometimes flagged as anomalies, requiring unnecessary manual reviews. These challenges highlight the need for intelligent, scalable, and context-aware reconciliation systems that can adapt to complex financial environments.
How LangChain Enhances Financial Reconciliation
LangChain is a framework designed to enhance AI-driven workflows by integrating LLMs with structured and unstructured data. It enables financial institutions to automate reconciliation with improved accuracy using retrieval-augmented generation (RAG), vector search, and LLM-powered decision-making. The following capabilities make LangChain a game-changer in financial reconciliation:
LangChain is a framework designed to enhance AI-driven workflows by integrating LLMs with structured and unstructured data. It enables financial institutions to automate reconciliation with improved accuracy using retrieval-augmented generation (RAG), vector search, and LLM-powered decision-making. The following capabilities make LangChain a game-changer in financial reconciliation:
Automated Data Extraction and Parsing
LangChain provides document loaders that ingest financial data from PDFs, emails, bank statements, and databases, converting them into structured formats for processing. It supports OCR-based extraction for scanned documents and natural language understanding (NLU) to process complex financial texts, ensuring that no critical information is missed during reconciliation.
- Multi-Format Data Processing: Supports CSV, XML, JSON, SQL, and NoSQL sources.
- Named Entity Recognition (NER): Identifies key financial entities such as vendors, amounts, and dates.
- Context-Aware Tokenization: Splits financial data into meaningful tokens for NLP-based interpretation.
- Dependency Parsing for Relation Extraction: Identifies relationships between financial entities.
- Metadata Extraction for Document Indexing: Helps in fast retrieval of relevant financial records.
Intelligent Transaction Matching
By leveraging embedding-based search, transactions can be converted into vector representations for similarity matching. Using tools like FAISS, ChromaDB, or Pinecone, LangChain enables fuzzy matching, allowing for intelligent detection of transactions with slight variations in metadata.
- Semantic Search Optimization: Uses pre-trained financial embeddings to improve transaction matching.
- Transformer-Based Similarity Matching: Applies BERT-based embeddings for contextual understanding.
- Threshold-Based Matching Strategies: Dynamically adjusts thresholds for matching confidence levels.
- Hybrid Similarity Search: Combines lexical matching with dense vector search for improved accuracy.
- Clustering-Based Anomaly Grouping: Groups similar mismatched transactions for bulk resolution.
Context-Aware Discrepancy Detection
Unlike traditional systems that rely on rigid rules, LangChain's LLMs analyze transaction context, reducing false positives and providing explanations for mismatches through retrieval-augmented generation (RAG).
- Few-Shot Learning for Classification: Trains models with minimal labeled data to adapt to reconciliation needs.
- Self-Supervised Learning Enhancements: Improves accuracy through iterative training cycles.
- Multi-Turn Question Answering: Allows interaction with reconciliation workflows for enhanced decision-making.
- Confidence-Based Discrepancy Scoring: Assigns confidence levels to mismatched records to reduce false alarms.
- Multi-Document Reconciliation: Aggregates information from multiple sources to improve resolution accuracy.
Anomaly and Fraud Detection
LangChain’s AI-driven anomaly detection assigns risk scores to transactions based on historical trends, flagging potential fraudulent activities for review.
- Time-Series Fraud Detection: Uses models like Prophet, LSTM, and Autoencoders for pattern recognition.
- Graph-Based Fraud Detection: Identifies linked transactions across multiple accounts for money laundering detection.
- Adaptive Risk Scoring: Dynamically assigns risk weights based on past fraudulent activities.
- Pattern-Based Fraud Profiling: Learns user transaction behaviors to identify deviations from normal activity.
- Blockchain-Based Integrity Checks: Ensures transaction validity by cross-referencing with distributed ledger records.
Scalability and Performance Optimization
As financial data grows exponentially, maintaining system performance is crucial. LangChain employs various techniques to optimize reconciliation at scale:
- Distributed Computing: Utilizes parallel processing frameworks like Apache Spark to handle large datasets.
- Edge AI Deployment: Runs lightweight reconciliation models on-premises to reduce cloud dependency.
- Data Stream Processing: Incorporates real-time analytics frameworks like Apache Flink for continuous reconciliation.
- Incremental Learning Pipelines: Adapts models dynamically to account for new financial patterns without retraining from scratch.
- AutoML for Model Selection: Automatically selects the best performing AI model for each reconciliation task.
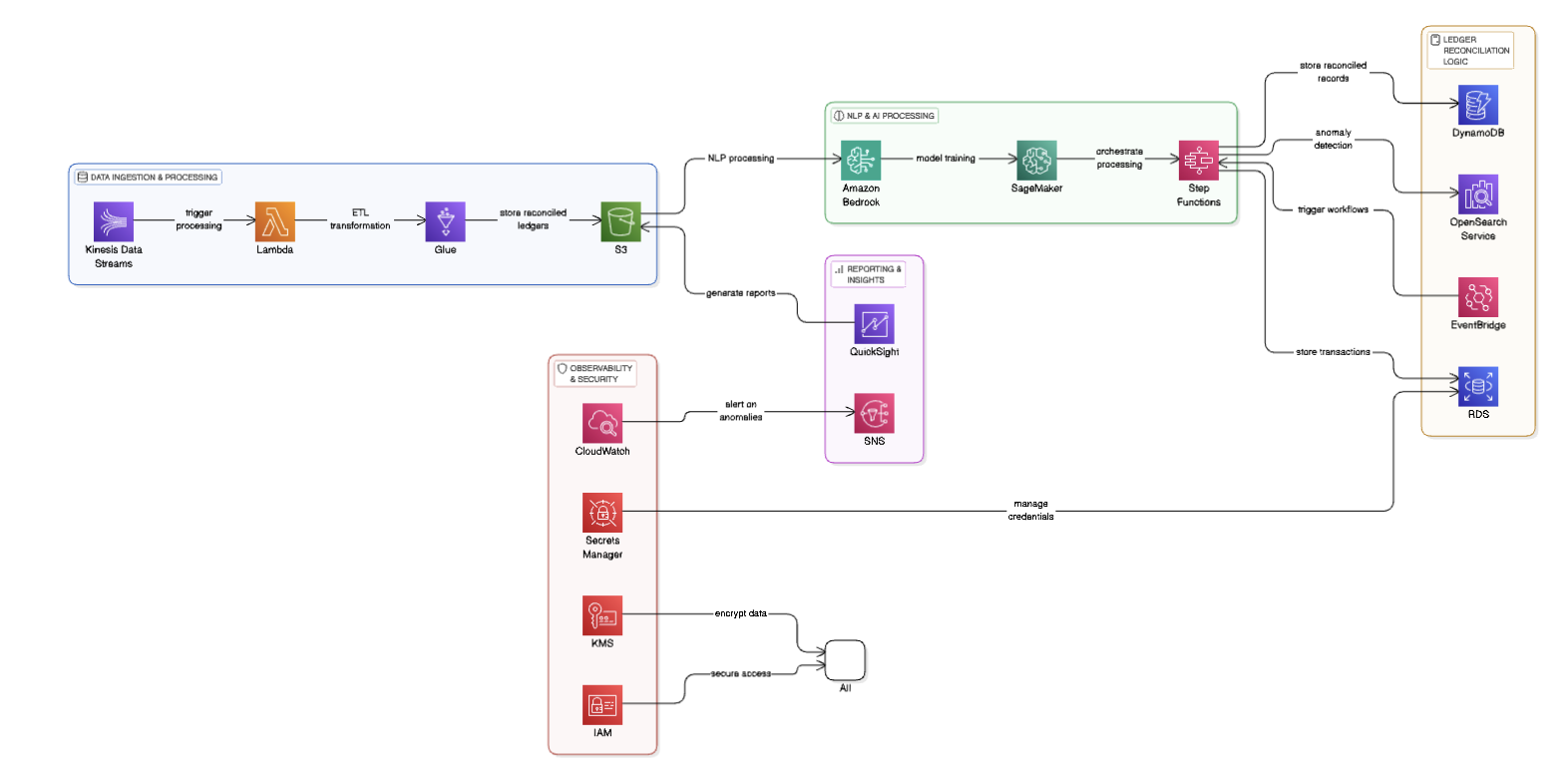
This system is designed to process and analyze financial transactions in real time using AWS services. The process begins with Kinesis Data Streams, which collects transaction data as it happens. This data is sent to AWS Lambda, a service that quickly processes small tasks. Lambda triggers AWS Glue, which cleans and organizes the data (ETL transformation) before storing it in Amazon S3. S3 acts as a storage space where all reconciled ledger records are kept safely.
Once the data is stored, it can be used for AI and machine learning processing. Amazon Bedrock processes the data using natural language models, and SageMaker trains machine learning models to detect patterns. Step Functions help to automate and manage these processes, making sure they run smoothly. This AI processing helps in identifying any unusual transactions, which could be errors or fraud.
After processing, the system stores the final reconciled data in different places based on its use. DynamoDB keeps structured records for quick access, OpenSearch is used for searching and detecting anomalies, EventBridge helps trigger automated workflows when something important happens, and RDS stores transaction details in a traditional database.
For reporting and alerts, QuickSight creates reports and dashboards so users can see financial trends and performance. If an unusual transaction is detected, SNS (Simple Notification Service) sends an alert, ensuring that issues are addressed quickly.
To keep everything secure and well-monitored, the system uses CloudWatch to track and log activities, Secrets Manager to securely store important credentials, KMS (Key Management Service) to encrypt data, and IAM (Identity and Access Management) to control who can access what. This ensures that only authorized users can view or change sensitive financial data.
This architecture allows us to process financial transactions quickly, detect errors or fraud automatically, and securely store all records, making financial reconciliation easier and more efficient.
use polars::prelude::*;
use rand::Rng;
use plotly::{Plot, Scatter, Bar};
use std::collections::HashMap;
fn main() -> PolarsResult<()> {
// Generate sample financial ledger data
let mut rng = rand::thread_rng();
let transaction_ids: Vec<i32> = (1..=20).collect();
let descriptions = vec![
"Payment to Vendor A", "Refund from Vendor B", "Salary Payout", "Bonus Allocation"
].iter().cycle().take(20).map(|s| s.to_string()).collect::<Vec<String>>();
let amounts: Vec<i32> = (0..20).map(|_| rng.gen_range(-10000..10000)).collect();
let transaction_types: Vec<String> = (0..20).map(|i| {
if i % 2 == 0 { "Credit".to_string() } else { "Debit".to_string() }
}).collect();
let mut account_balance = Vec::new();
let mut cumulative_sum = 0;
for _ in 0..20 {
let balance_change = rng.gen_range(-5000..5000);
cumulative_sum += balance_change;
account_balance.push(cumulative_sum);
}
// Create DataFrame
let df = df!(
"Transaction_ID" => &transaction_ids,
"Description" => &descriptions,
"Amount" => &amounts,
"Transaction_Type" => &transaction_types,
"Account_Balance" => &account_balance
)?;
// Function to analyze financial transactions
let df = analyze_transactions(df)?;
// Plot 1: Account Balance Over Transactions
plot_account_balance(&df)?;
// Plot 2: Transaction Amounts (Bar Chart)
plot_transaction_amounts(&df)?;
// Plot 3: Anomaly Detection Visualization
plot_anomaly_detection(&df)?;
// Display final financial ledger analysis
println!("Final Financial Ledger Analysis:");
println!("{:?}", df);
Ok(())
}
// Function to analyze financial transactions and detect anomalies
fn analyze_transactions(mut df: DataFrame) -> PolarsResult<DataFrame> {
let anomalies: Vec<&str> = df.column("Amount")?
.i32()?
.into_iter()
.map(|amount| if let Some(a) = amount { if a < -5000 { "Yes" } else { "No" } } else { "No" })
.collect();
df.with_column(Series::new("Anomaly", anomalies))?;
Ok(df)
}
// Function to plot account balance over time
fn plot_account_balance(df: &DataFrame) -> PolarsResult<()> {
let transaction_ids = df.column("Transaction_ID")?.i32()?.into_no_null_iter().collect::<Vec<_>>();
let account_balance = df.column("Account_Balance")?.i32()?.into_no_null_iter().collect::<Vec<_>>();
let trace = Scatter::new(transaction_ids, account_balance)
.mode(plotly::common::Mode::LinesMarkers)
.name("Account Balance");
let mut plot = Plot::new();
plot.add_trace(trace);
plot.show();
Ok(())
}
// Function to plot credit vs debit transactions
fn plot_transaction_amounts(df: &DataFrame) -> PolarsResult<()> {
let transaction_ids = df.column("Transaction_ID")?.i32()?.into_no_null_iter().collect::<Vec<_>>();
let amounts = df.column("Amount")?.i32()?.into_no_null_iter().collect::<Vec<_>>();
let transaction_types = df.column("Transaction_Type")?.utf8()?.into_no_null_iter().collect::<Vec<_>>();
let mut type_map: HashMap<&str, Vec<i32>> = HashMap::new();
for (i, t_type) in transaction_types.iter().enumerate() {
type_map.entry(*t_type).or_insert(Vec::new()).push(amounts[i]);
}
let mut plot = Plot::new();
for (t_type, values) in type_map {
let trace = Bar::new(transaction_ids.clone(), values).name(t_type);
plot.add_trace(trace);
}
plot.show();
Ok(())
}
// Function to plot anomaly detection
fn plot_anomaly_detection(df: &DataFrame) -> PolarsResult<()> {
let transaction_ids = df.column("Transaction_ID")?.i32()?.into_no_null_iter().collect::<Vec<_>>();
let amounts = df.column("Amount")?.i32()?.into_no_null_iter().collect::<Vec<_>>();
let anomalies = df.column("Anomaly")?.utf8()?.into_no_null_iter().collect::<Vec<_>>();
let colors: Vec<&str> = anomalies.iter().map(|&a| if a == "Yes" { "red" } else { "green" }).collect();
let trace = Scatter::new(transaction_ids, amounts)
.mode(plotly::common::Mode::Markers)
.marker(plotly::common::Marker::new().color(colors))
.name("Anomaly Detection");
let mut plot = Plot::new();
plot.add_trace(trace);
plot.show();
Ok(())
}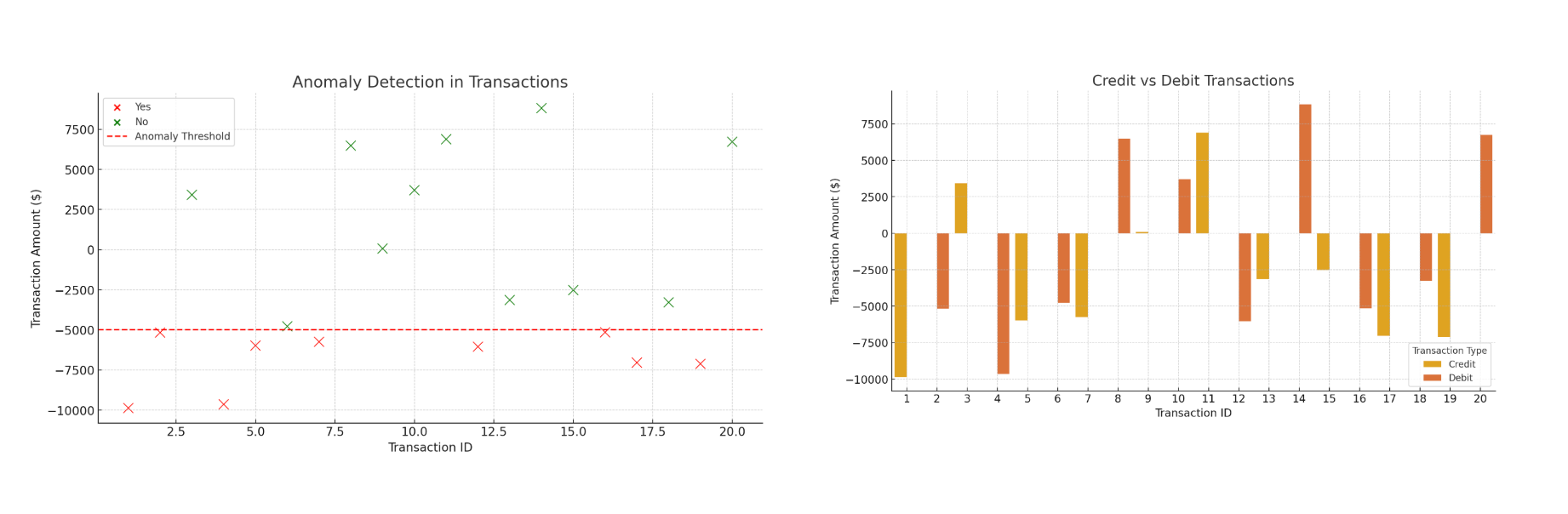
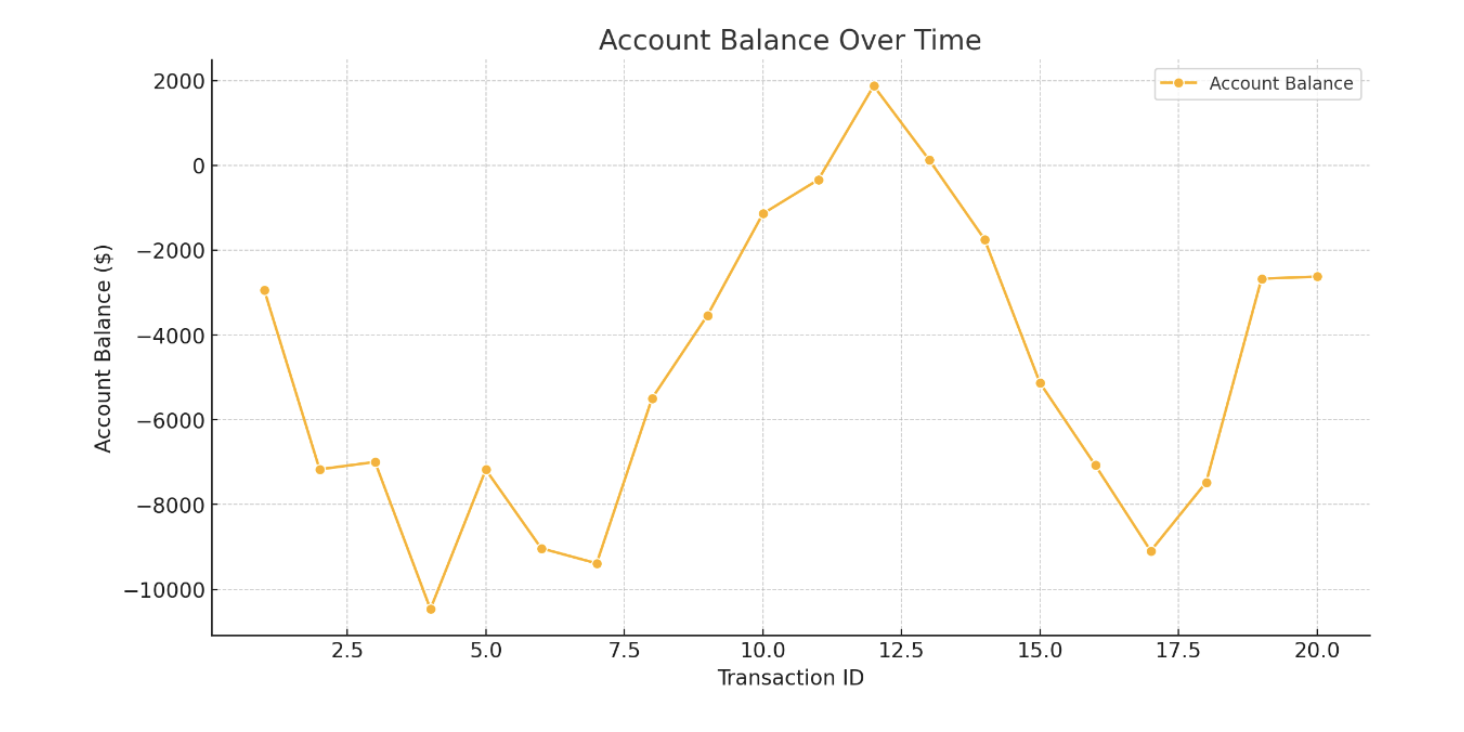
This program analyzes financial transactions by generating sample data, detecting anomalies, and creating visualizations. It uses the polars crate for handling DataFrames (like Pandas in Python) and plotly for making interactive charts. The program first creates 20 transactions with random values, including Transaction_ID, Description, Amount, Transaction_Type (Credit/Debit), and Account_Balance, using the rand crate to generate random amounts and balances. It then runs an anomaly detection function that checks if any transaction has an Amount below -5000 and marks it as an anomaly. The program has three visualization functions:
- Account Balance Line Chart: Plots
Transaction_IDon the x-axis and Account_Balance on the y-axis to show how balance changes over time. - Credit vs Debit Bar Chart: Groups transactions by type (Credit or Debit) and shows them as bars to compare transaction amounts.
- Anomaly Detection Scatter Plot: Marks normal transactions in green and anomalies in red, with a dashed threshold line at
-5000.
Each function extracts data from the DataFrame, processes it, and creates a plotly chart. The code is modular, meaning each function does one job, making it easier to modify. Rust ensures memory safety and performance, making this program efficient for large-scale financial data analysis.
Opinions expressed by DZone contributors are their own.
Comments