NoSQL Data Modeling Mistakes That Kill Performance
Even if you adopt the fastest database on powerful infrastructure, you won’t be able to tap its full potential unless you get your data modeling right.
Join the DZone community and get the full member experience.
Join For FreeGetting your data modeling wrong is one of the easiest ways to ruin your performance. And it’s especially easy to screw this up when you’re working with NoSQL, which (ironically) tends to be used for the most performance-sensitive workloads. NoSQL data modeling might initially appear quite simple: just model your data to suit your application’s access patterns. But in practice, that’s much easier said than done.
Fixing data modeling is no fun, but it’s often a necessary evil. If your data modeling is fundamentally inefficient, your performance will suffer once you scale to some tipping point that varies based on your specific workload and deployment. Even if you adopt the fastest database on the most powerful infrastructure, you won’t be able to tap its full potential unless you get your data modeling right.
This article explores three of the most common ways to ruin your NoSQL database performance, along with tips on how to avoid or resolve them.
Not Addressing Large Partitions
Large partitions commonly emerge as teams scale their distributed databases. Large partitions are partitions that grow too big up to the point when they start introducing performance problems across the cluster’s replicas.
One of the questions that we hear often – at least once a month – is, “What constitutes a large partition?” Well, it depends. Some things to consider:
- Latency expectations: The larger your partition grows, the longer it will take to be retrieved. Consider your page size and the number of client-server round trips needed to fully scan a partition.
- Average payload size: Larger payloads generally lead to higher latency. They require more server-side processing time for serialization and deserialization and also incur a higher network data transmission overhead.
- Workload needs: Some workloads organically require larger payloads than others. For instance, I’ve worked with a Web3 blockchain company that would store several transactions as BLOBs under a single key, and every key could easily get past 1 megabyte in size.
- How you read from these partitions: For example, a time series use case will typically have a timestamp clustering component. In that case, reading from a specific time window will retrieve much less data than if you were to scan the entire partition.
The following table illustrates the impact of large partitions under different payload sizes, such as 1, 2, and 4 kilobytes.
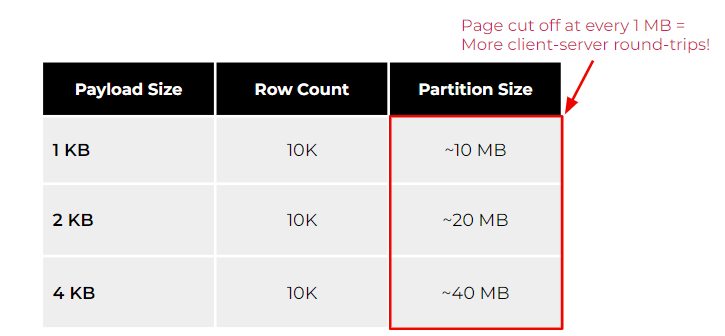
As you can see, the higher your payload gets under the same row count, the larger your partition is going to be. However, if your use case frequently requires scanning partitions as a whole, then be aware that databases have limits to prevent unbounded memory consumption. For example, ScyllaDB cuts off pages at every 1MB to prevent the system from potentially running out of memory. Other databases (even relational ones) have similar protection mechanisms to prevent an unbounded bad query from starving the database resources. To retrieve a payload size of 4KB and 10K rows with ScyllaDB, you would need to retrieve at least 40 pages to scan the partition with a single query. This may not seem a big deal at first. However, as you scale over time, it could affect your overall client-side tail latency.
Another consideration: With databases like ScyllaDB and Cassandra, data written to the database is stored in the commit log and under an in-memory data structure called a "memtable."
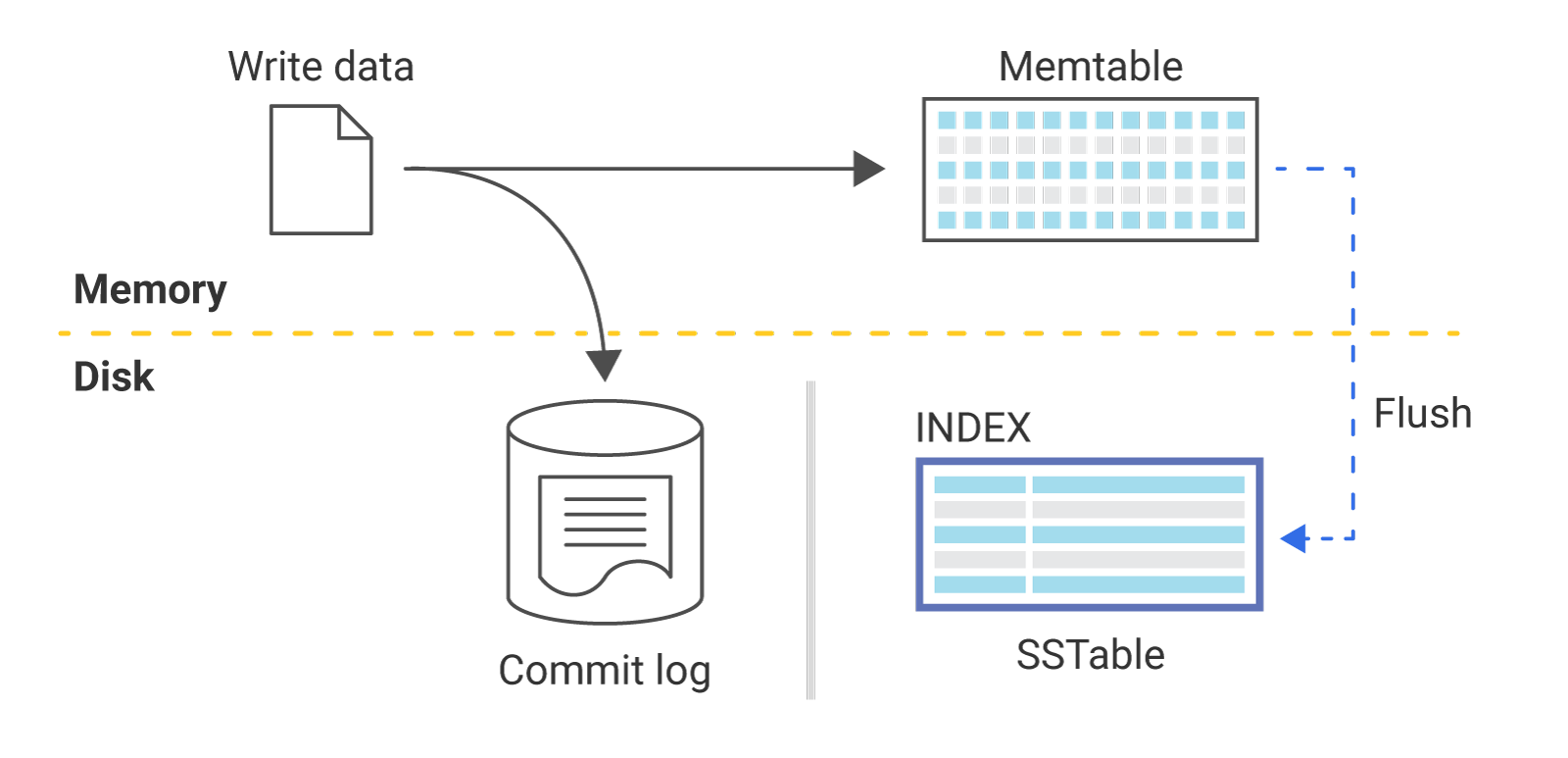
The commit log is a write-ahead log that is never really read from, except when there’s a server crash or a service interruption. Since the memtable lives in memory, it eventually gets full. To free up memory space, the database flushes memtables to disk. That process results in SSTables (sorted strings tables), which is how your data gets persisted.
What does all this have to do with large partitions? Well, SSTables have specific components that need to be held in memory when the database starts. This ensures that reads are always efficient and minimizes wasting storage disk I/O when looking for data. When you have extremely large partitions (for example, we recently had a user with a 2.5 terabyte partition in ScyllaDB), these SSTable components introduce heavy memory pressure, therefore shrinking the database’s room for caching and further constraining your latencies.
How do you address large partitions via data modeling? Basically, it’s time to rethink your primary key. The primary key determines how your data will be distributed across the cluster, which improves performance as well as resource utilization. A good partition key should have high cardinality and roughly even distribution. For example, a high cardinality attribute like User Name, User ID or Sensor ID might be a good partition key. Something like State would be a bad choice because states like California and Texas are likely to have more data than less populated states such as Wyoming and Vermont.
Or consider this example. The following table could be used in a distributed air quality monitoring system with multiple sensors:
CREATE TABLE air_quality_data (
sensor_id text,
time timestamp,
co_ppm int,
PRIMARY KEY (sensor_id, time)
);With time being our table’s clustering key, it’s easy to imagine that partitions for each sensor can grow very large, especially if data is gathered every couple of milliseconds. This innocent-looking table can eventually become unusable. In this example, it takes only ~50 days.
A standard solution is to amend the data model to reduce the number of clustering keys per partition key. In this case, let’s take a look at the updated `air_quality_data` table:
CREATE TABLE air_quality_data (
sensor_id text,
date text,
time timestamp,
co_ppm int,
PRIMARY KEY ((sensor_id, date), time)
);After the change, one partition holds the values gathered in a single day, which makes it less likely to overflow. This technique is called bucketing, as it allows us to control how much data is stored in partitions.
Bonus: See how Discord applies the same bucketing technique to avoid large partitions.
Introducing Hot Spots
Hot spots can be a side effect of large partitions. If you have a large partition (storing a large portion of your data set), it’s quite likely that your application access patterns will hit that partition more frequently than others. In that case, it also becomes a hot spot.
Hot spots occur whenever a problematic data access pattern causes an imbalance in the way data is accessed in your cluster. One culprit is when the application fails to impose any limits on the client side and allows tenants to potentially spam a given key. For example, think about bots in a messaging app frequently spamming messages in a channel. Hot spots could also be introduced by erratic client-side configurations in the form of retry storms. That is, a client attempts to query specific data, times out before the database does, and retries the query while the database is still processing the previous one.
Monitoring dashboards should make it simple for you to find hot spots in your cluster. For example, this dashboard shows that shard 20 is overwhelmed with reads.

For another example, the following graph shows three shards with higher utilization, which correlates to the replication factor of three configured for the keyspace in question.

Here, shard seven introduces a much higher load due to the spamming.
How do you address hot spots? First, use a vendor utility on one of the affected nodes to sample which keys are most frequently hit during your sampling period. You can also use tracing, such as probabilistic tracing, to analyze which queries are hitting which shards and then act from there.
If you find hot spots, consider:
- Reviewing your application access patterns. You might find that you need a data modeling change, such as the previously-mentioned bucketing technique. If you need sorting, you could use a monotonically increasing component, such as Snowflake. Or, maybe it’s best to apply a concurrency limiter and throttle down potential bad actors.
- Specifying per-partition rate limits, after which the database will reject any queries that hit that same partition.
- Ensuring that your client-side timeouts are higher than the server-side timeouts to prevent clients from retrying queries before the server has a chance to process them ( “retry storms”).
Misusing Collections
Teams don’t always use collections, but when they do, they often use them incorrectly. Collections are meant for storing/denormalizing a relatively small amount of data. They’re essentially stored in a single cell, which can make serialization/deserialization extremely expensive.
When you use collections, you can define whether the field in question is frozen or non-frozen. A frozen collection can only be written as a whole; you cannot append or remove elements from it. A non-frozen collection can be appended to, and that's exactly the type of collection that people most misused. To make matters worse, you can even have nested collections, such as a map that contains another map, which includes a list, and so on.
Misused collections will introduce performance problems much sooner than large partitions, for example. If you care about performance, collections can’t be very large at all. For example, if we create a simple key:value table, where our key is a `sensor_id` and our value is a collection of samples recorded over time, our performance will be suboptimal as soon as we start ingesting data.
CREATE TABLE IF NOT EXISTS {table} (
sensor_id uuid PRIMARY KEY,
events map<timestamp, FROZEN<map<text, int>>>,
)The following monitoring snapshots show what happens when you try to append several items to a collection at once.


You can see that while the throughput decreases, the p99 latency increases. Why does this occur?
- Collection cells are stored in memory as sorted vectors.
- Adding elements requires a merge of two collections (old and new).
- Adding an element has a cost proportional to the size of the entire collection.
- Trees (instead of vectors) would improve the performance, BUT…
- Trees would make small collections less efficient!
Returning that same example, the solution would be to move the timestamp to a clustering key and transform the map into a FROZEN collection (since you no longer need to append data to it). These very simple changes will greatly improve the performance of the use case.
CREATE TABLE IF NOT EXISTS {table} (
sensor_id uuid,
record_time timestamp,
events FROZEN<map<text, int>>,
PRIMARY KEY(sensor_id, record_time)
)
Published at DZone with permission of Felipe Mendes. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments