Onion Architecture Is Interesting
With layered and hexagonal architectures understood, the time has come to talk about a relative – Onion Architecture, which puts a new spin on layers.
Join the DZone community and get the full member experience.
Join For FreeAfter Layered and Hexagonal architectures, the time has come to talk about their close cousin – the Onion Architecture initially introduced in a series of posts by Jeffrey Palermo.
What is Onion Architecture?
As we said in the introduction, the concept of Onion Architecture is closely connected to two other architectural styles – Layered and Hexagonal. Similarly to the Layered approach, Onion Architecture uses the concept of layers, but they are a little different:
- Domain Model layer, where our entities and classes closely related to them e.g. value objects reside
- Domain Services layer, where domain-defined processes reside
- Application Services layer, where application-specific logic i.e. our use cases reside
- Outer layer, which keeps peripheral concerns like UI, databases or tests
Those layers when presented as circles, each wrapping around the previous one, form the famous “onion”:
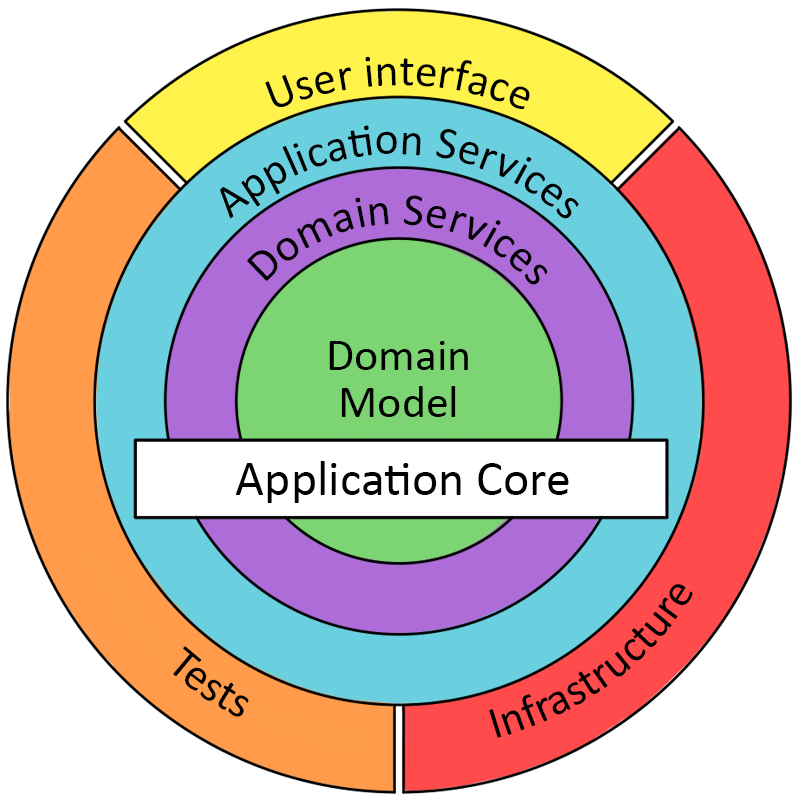
Between the layers of the Onion, there is a strong dependency rule: outer layers can depend on lower layers, but no code in the lower layer can depend directly on any code in the outer layer. This is essentially the Dependency Inversion Principle, just presented in terms of the overall architecture, not just single classes.
As you can see in the picture, the three inner layers i.e. domain model, domain services, and application services are parts of the application core. Application core contains all logic necessary to run and test the application as long as necessary dependencies are provided at runtime. This is possible thanks to the dependency rule that we introduced in the previous paragraph. Since no code in the application core depends on outer layers, we can just swap out the UI or the database for the testing (or any other) purposes.
The Essence of Onion Architecture
To me, the essence of Onion Architecture is the application of Dependency Inversion Principle with architecturally defined priorities between layers. Jeffrey Palermo, in his original texts about Onion Architecture, stresses this a lot – the major difference between Onion Architecture and Layered Architecture is the direction of the dependencies (and hence coupling).
In the Layered Architecture, as understood by the majority of people, virtually all layers can depend on the infrastructure layer, as in the picture below:

This causes some bad coupling. A change in the infrastructure layer like changing some library or switching a database provider could spill changes all over your business logic. Onion Architecture is about protecting the business logic, hence the dependency rule. A flattened picture of the Onion Architecture would look like this:

Implementing Onion Architecture
The Onion Architecture gives us no direct guideline on how the layers should be implemented, so we can assume that you are free to choose whatever level you want i.e. class, package, module or whatever else. However, given the heart of the architecture being a domain model, I would say that you should definitely avoid mixing it with those less important concerns like UI.
When it comes to the dependency rule, things boil down to implementing the Dependency Inversion Principle whenever an inner-layer class wants to interact with an outer-layer class. To do this, we simply put interfaces that the outer-layer classes should implement in the inner layers:

Example
Jeffrey Palermo himself provided an example of the Onion Architecture, so instead of playing around with Spring Pet Clinic again, let’s analyze his solution. The project is in C#, but since we will look only at the code structure and won’t read the implementation, all you need to know is that C# namespaces are roughly equivalent to Java packages (more info here).
The overall structure of the project looks like this (I cut out configuration files):

As you can see, the application core is separated from the infrastructure, UI, and tests using namespaces. Let’s look at the structure of the Core namespace:

The most prominent classes in the Core are Visitor and VisitorProcessor, members of domain model and application services layers respectively. Since the core should not depend on the Outer layer, the dependencies on VisitorBuilder and VisitorRepository are represented as interfaces, which are implemented in the UI and infrastructure layers.
If you want to take a closer look at the project, you can check it out here.
Benefits of an Onion Architecture
- Plays well with DDD – that should not be a surprise for an architecture that builds everything on top of a domain model
- Directed coupling – the most important code in our application depends on nothing, everything depends on it
- Flexibility – from an inner-layer perspective, you can swap out anything in any of the outer layers and things should work just fine
- Testability – since your application core does not depend on anything else, it can be easily and quickly tested in isolation
Drawbacks of an Onion Architecture
- Learning curve – I don’t know why, but people tend to mess up splitting responsibilities between layers, especially harming the domain model
- Indirection – interfaces everywhere!
- Potentially heavy – if you look at Palermo’s project, the application core has no dependencies towards frameworks, even NHibernate, a cousin of Java’s Hibernate. Implementing things this way in Java would not be so easy unless you want to jump into XML files (yay!)
When to Apply Onion Architecture?
In the case of Onion Architecture, I see things pretty similarly as in the Hexagonal one. In the world of microservices that work in a request-response manner, you usually need a Repository interface and one or two Gateways, and your business code is well protected from unwanted dependencies. I’m not sure if that’s an Onion Architecture already, it depends on your interpretation. On the other hand, we have the monoliths, which contain much more dependencies and services depend on one another on the code level. In this case, you’ll probably find much more outward dependencies to replace with interfaces. And there’s my framework dilemma, which I keep coming back to, mostly because of Uncle Bob’s writings that suggest that Onion and Hexagonal Architectures avoid framework dependencies. Hence, I’d say that to some extent all of us should take from Onion Architecture, but that extent should be decided on a case-by-case basis.
One interesting thing that I found about Onion Architecture is that it’s more appealing for C# programmers than Java programmers, at least judging by the blog posts I found. Of course, that’s just a curiosity, I wouldn’t consider that an argument in the discussion on whether to apply the architecture or not.
Summary
Onion Architecture sets a clear dependency rule between layers, making it a more restrictive variant of Layered and Hexagonal Architectures. At the very center of our application sits a domain model, surrounded by domain services and application services. Those 3 layers form the application core – no relevant application logic should reside outside of it and it should be independent of all peripheral concerns like UI or databases. As a close cousin of Hexagonal, Onion Architecture is certainly very powerful, but the extent to which we’ll apply its principles should be carefully considered.
Published at DZone with permission of Grzegorz Ziemoński. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments