Oracle vs. Hadoop
In this article, we’ll explain the differences (and benefits) of both Hadoop and Big Data and how they fit into your data architecture.
Join the DZone community and get the full member experience.
Join For FreeAlthough Hadoop and Big Data (whatever that is) are the new kids on the block, don’t be too quick to write off relational database technology. In this article, I’ll explain the differences (and benefits) of both solutions.
Hadoop Is NOT a Database!
As much as the marketing hype would have us believe, Hadoop is NOT a database, but a collection of open-source software that runs as a distributed storage framework (HDFS) to manage very large data sets. Its primary purpose is the storage, management, and delivery of data for analytical purposes. It’s hard to talk about Hadoop without getting into keywords and jargon (for example, Impala, YARN, Parquet, and Spark), so I’ll start by explaining the basics.
At the very core of Hadoop is HDFS (Hadoop Distributed File System). So, it’s not a database after all — at its core, it’s a file system, but a very powerful one.
Hadoop Is a Different Kind of Animal
It’s impossible to really understand Hadoop without understanding it’s underlying hardware architecture, which gives it two of it’s biggest strengths, it’s scalability and massive parallel processing (MPP) capability.
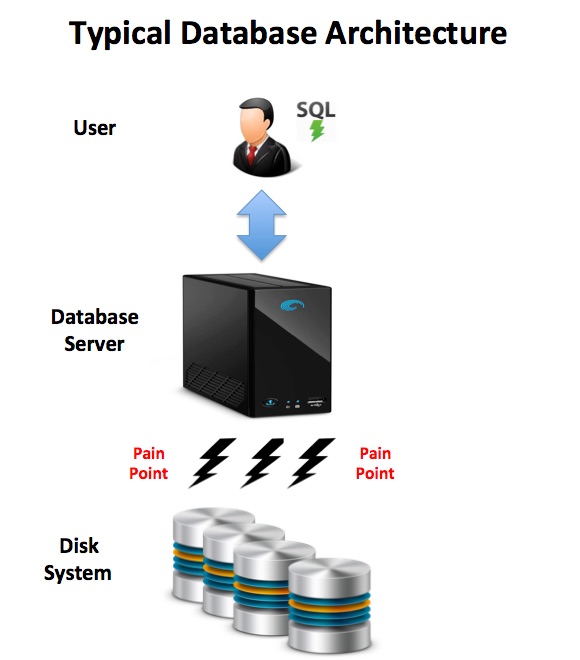
To illustrate the difference, the diagram below illustrates a typical database architecture in which a user executes SQL queries against a single large database server. Despite sophisticated caching techniques, the biggest bottleneck for most Business Intelligence applications is still the ability to fetch data from disk into memory for processing. This limits both the system processing and it’s ability to scale — to quickly grow to deal with increasing data volumes.
As there’s a single server, it also needs expensive redundant hardware to guarantee availability. This will include dual redundant power supplies, network connections and disk mirroring which, on very large platforms can make this an expensive system to build and maintain.
Compare this with the Hadoop Distributed Architecture below. In this solution, the user executes SQL queries against a cluster of commodity servers, and the entire process is run in parallel. As effort is distributed across several machines, the disk bottleneck is less of an issue, and as data volumes grow, the solution can be extended with additional servers to hundreds or even thousands of nodes.
Hadoop has automatic recovery built in such that if one server becomes unavailable, the work is automatically redistributed among the surviving nodes, which avoids the huge cost overhead of an expensive standby system. This can lead to a huge advantage in availability, as a single machine can be taken down for service, maintenance or an operating system upgrade with zero overall system downtime.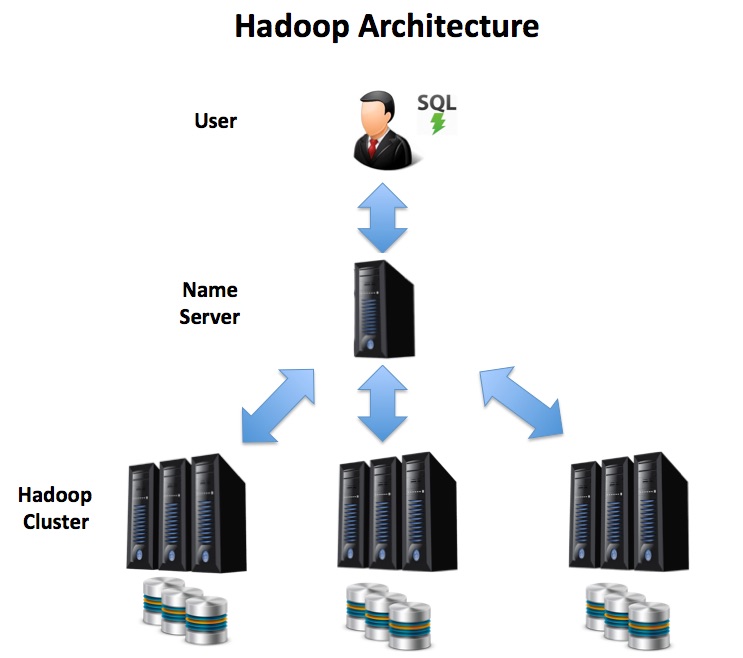
The 3 Vs and the Cloud
Hadoop has several other potential advantages over a traditional RDBMS most often explained by the three (and increasing) Vs.
- Volume — It’s distributed MPP architecture makes it ideal for dealing with large data volumes. Multi-terabyte data sets can be automatically partitioned (spread) across several servers, and processed in parallel.
- Variety — Unlike an RDBMS where you need to define the structure of your data before loading it, in HDFS, loading data can be as simple as copying a file – which can be in any format. This means Hadoop can just as easily manage, store and integrate data from a database extract, a free text document or even JSON or XML documents and digital photos or eMails.
- Velocity — Again the MPP architecture and powerful in-memory tools (including Spark, Storm, and Kafka), which form part of the Hadoop framework, make it an ideal solution to deal with real or near-real-time streaming feeds which arrive at velocity. This means you can use it to deliver analytics-based solutions in real time. For example, using predictive analytics to recommend options to a customer.
The advent of The Cloud leads to an even greater advantage (although not another “V” in this case) — Elasticity.
That’s the ability to provide on-demand scalability using cloud-based servers to deal with unexpected or unpredictable workloads. This means entire networks of machines can spin up as needed to deal with massive data processing challenges while hardware costs are restrained by a pay-as-you-go model. Of course, in a highly regulated industry (eg. Financial Services) with highly sensitive data, the cloud may well be treated with suspicion, in which case you may want to consider an "On-Premises Cloud"-based solution to secure your data.
Column Based Storage
As if the hardware advantages were not already compelling, Hadoop can also natively support Column based storage which gives analytic queries a massive performance and compression advantage. This technique has been adopted a number a Data Warehouse databases including the incredibly fast Vertica.
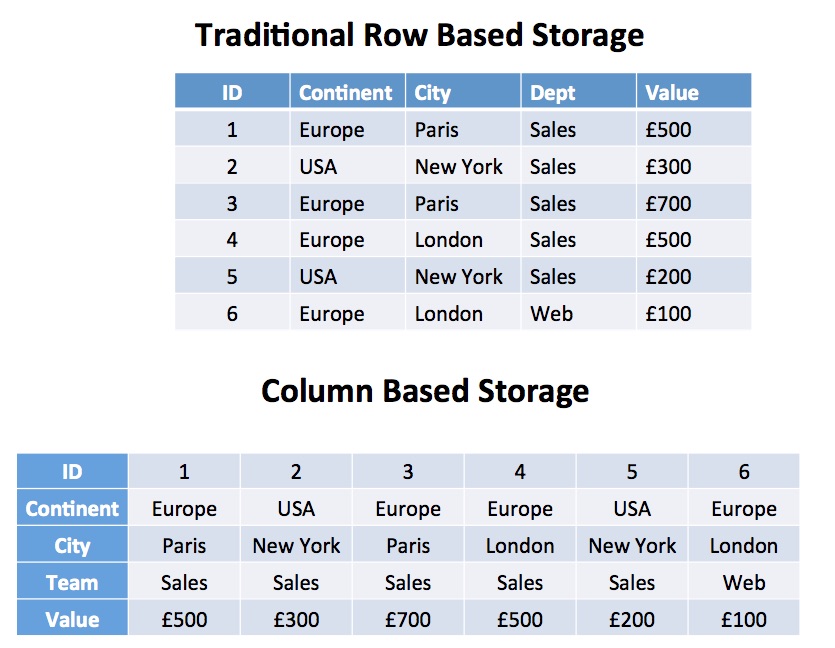
The diagram above illustrates the difference between the two methods. With traditional row-based storage, it’s quick to identify and fetch a single row, for example, SALES row 5. This is great for transaction processing systems where we need to fetch or update the value for a single row.
However, analytic queries tend to fetch, summarise and process millions or even billions of rows.
Take the following simple query:
SELECT team, sum(value) FROM sales GROUP by team;
On a row-based system, this query needs to fetch every column of every row into memory to strip out the team andvalue columns. On a table with 100 columns and billions of rows, this could lead to terabytes of data being read from disk.
However, on a column based solution, the same query would involve processing just 2% of the data with enormous performance benefits. As an added bonus, you’ll also find significant compression advantages. For example, the repeating values in the TEAM column can be replaced by a simple dictionary encoding technique to compress the data. On a simple test of a billion rows of text, this produced a 50% saving, reducing a 56Gb text file to 26Gb using the Parquet data format.
Hadoop Is (Probably) Cheaper Than Oracle
As a comparison of Hadoop and Oracle costs demonstrates, despite the increasing cost of scarce Hadoop skills, the benefits of Open Source software and inexpensive hardware mean it can be considerably cheaper to host a large Hadoop system than an Oracle database.
On a system storing 168 TB of data, and taking account of hardware, license costs, support, and personnel, the study found Oracle cost around 200% more than the corresponding Hadoop solution. Of course, that doesn’t take account of migrating data from the warehouse to Hadoop, although whether that’s sensible is, in fact, a question for a later article.
Bigger, Faster, Cheaper: What’s the Catch?
To start, you need to choose the right tool for the job. Throughout this article, I’ve repeatedly talked about Analytics, Data Warehousing, and Business Intelligence. That’s because Hadoop is not a traditional database, and is not suitable for transaction processing tasks — as a back-end data store for screen-based transaction systems.
This is because Hadoop and HDFS are not ACID compliant. This means:
- A — Atomic: When updating data, all components of the change will complete or none at all. For example, an update affecting both CUSTOMER and their SALES history will be committed together. Not so on HDFS.
- C — Consistent: When a transaction completes, all data will be left in a consistent state.
- I — Isolation: Changes made by other users are dealt with in isolation which in Oracle implies read consistency — any given user will see a consistent view of the data at that point in time.
- D — Durable: After a change is applied it will be durable, and if the system fails mid-way through a change, the partial changes will be rolled-back during system recovery.
In fact, Hadoop sacrifices ACID compliance in favor of throughput. It’s also designed to deal with large data volumes, and the smallest typical unit of work is around 128Mb. Compare this to a typical Oracle data block at around 8 Kilobytes.
Whereas Oracle will manage a range of OLTP and OLAP, processing lots of short running transactions with single row lookups, Hadoop is more suited to single process batch operations. For single-row key-value lookup operations, you'll need a NoSQL (or even NewSQL) database - a subject of my next articles.
All is not lost, however, as most Data Warehouse processing is batch-oriented, fetching, processing, and storing massive data sets, and Hadoop is purpose-built for this use-case.
Products like Cloudera Impala, Apache Hive, and Spark SQL add low latency end-user SQL query and analysis tools over massive data sets, and again, ACID compliance tends to be less important in Business Intelligence systems where 99.9% accuracy is a dreamed of goal rather than a business critical requirement.
If you do need massive OLTP throughput, you might consider a NoSQL database, described in my next article.
Conclusion
The fact is, Oracle is not going to go away any time soon. It’s been the core enterprise database platform for over 30 years, and that’s not going to change overnight. Indeed, Oracle is already adopting and adapting to the new challenger technologies with the Oracle Big Data Appliance, Exadata Appliance, and Oracle 12c In-Memory, which I’ll cover in separate articles.
I do, however, sense the overall Data Warehouse architecture is changing, and Hadoop and the plethora of technology products that come with it will each add an additional specialized capability to the overall stack. In the meantime, we need to be mindful of our approach so we deliver Requirements Driven Development rather than CV driven solutions.
It’s certainly good to be living in interesting times.
Thank You
Thanks for reading this far. If you found this helpful, you can view more articles on Big Data, Cloud Computing, Database Architecture and the future of data warehousing on my web site www.Analytics.Today.

Published at DZone with permission of John Ryan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments