Parallelism in ConcurrentHashMap
ConcurrentHashMap is used extensively in multi-threaded applications. In this article, we will learn more about parallelism in Concurrent Hashmaps.
Join the DZone community and get the full member experience.
Join For FreeConcurrentHashMap is used extensively in multi-threaded applications. Examples of multi-threaded applications are online gaming applications and chat applications, which add the benefit of concurrency to the application. To make the application more concurrent in nature, ConcurrentHashMap introduces a concept called ‘Parallelism.’
In this article, we will learn more about parallelism in Concurrent Hashmaps.
What Is Parallelism?
Basically, parallel computing divides a problem into subproblems, solves those subproblems parallelly, and finally joins the results of the subproblems. Here, the subproblems will run in separate threads.
Java Support to Parallelism in ConcurrentHashMap
In order to make use of parallelism in ConcurrentHashMap, we need to use Java 1.8 version onwards. Parallelism is not supported in Java versions less than 1.8.
Common Framework for Parallel Processing
Java has introduced a framework called ‘fork and join’ that will enable parallel computing. It makes use of java.util.concurrent.ForkJoinPool API to achieve parallel computing. This API is used to implement parallelism in ConcurrentHashMap.
Parallel Methods in ConcurrentHashMap
ConcurrentHashMap effectively uses parallel computing with the help of parallelism threshold. It is a numerical value, and the default value is two.
These are the following methods that have parallelism capabilities in ConcurrentHashMap.
forEach()reduce()reduceEntries()forEachEntry()forEachKey()forEachValue()
The concurrentHashMap deals with parallelism slightly differently, and you will understand that if you look at the arguments of these above methods. Each of these methods can take the parallelism threshold as an argument.
First of all, parallelism is an optional feature. We can enable this feature by adding the proper parallel threshold value in the code.
Usage of ConcurrentHashMap Without Parallelism
Let us take an example of replacing all the string values of a concurrenthashmap. This is done without using parallelism.
Example:
concurrentHashMap.forEach((k,v) -> v=””);
It is pretty straightforward, and we are iterating all the entries in a concurrenthashmap and replacing the value with an empty string. In this case, we are not using parallelism.
Usage of ConcurrentHashMap With Parallelism
Example:
concurrentHashMap.forEach(2, (k,v) -> v=””);
The above example iterates a ConcurrentHashMap and replaces the value of a map with an empty string. The arguments to the forEach() method are parallelism threshold and a functional interface. In this case, the problem will be divided into subproblems.
The problem is replacing the concurrent hashmap's value with an empty string. This is achieved by dividing this problem into subproblems, i.e., creating separate threads for subproblems, and each thread will focus on replacing the value with an empty string.
What Happens When Parallelism Is Enabled?
When the parallelism threshold is enabled, JVM will create threads, and each thread will run to solve the problem and join the results of all the threads. The significance of this value is that if the number of records has reached a certain level (threshold), then only JVM will enable parallel processing in the above example. The application will enable parallel processing if there is more than one record in the map.
This is a cool feature; we can control the parallelism by adjusting the threshold value. This way, we can take advantage of parallel processing in the application.
Take a look at another example below:
concurrentHashMap.forEach(10000, (k,v) -> v=””);
In this case, the parallelism threshold is 10,000, which means that if the number of records is less than 10,000, JVM will not enable parallelism when replacing the values with an empty string.
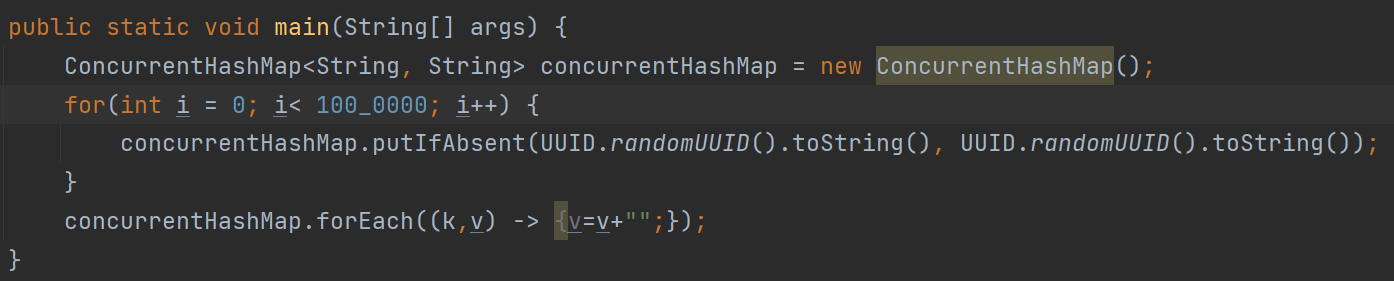
Fig: Full code example without parallelism
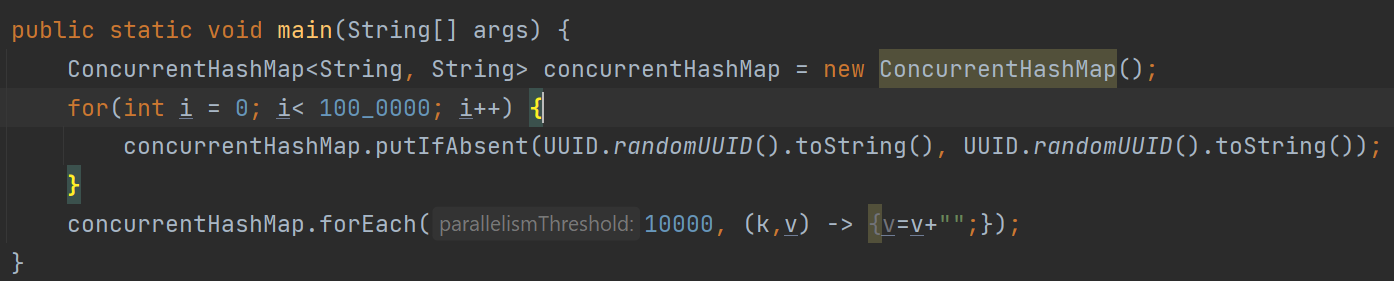 Fig: Full code example with parallelism
Fig: Full code example with parallelism
In the above example, the parallelism threshold is 10,000.
Performance Comparison of Parallel Processing
The following code replaces all the values in the map with an empty string. This concurrenthash map contains more than 100,000 entries in it. Let’s compare the performance of the below code without and with parallelism.
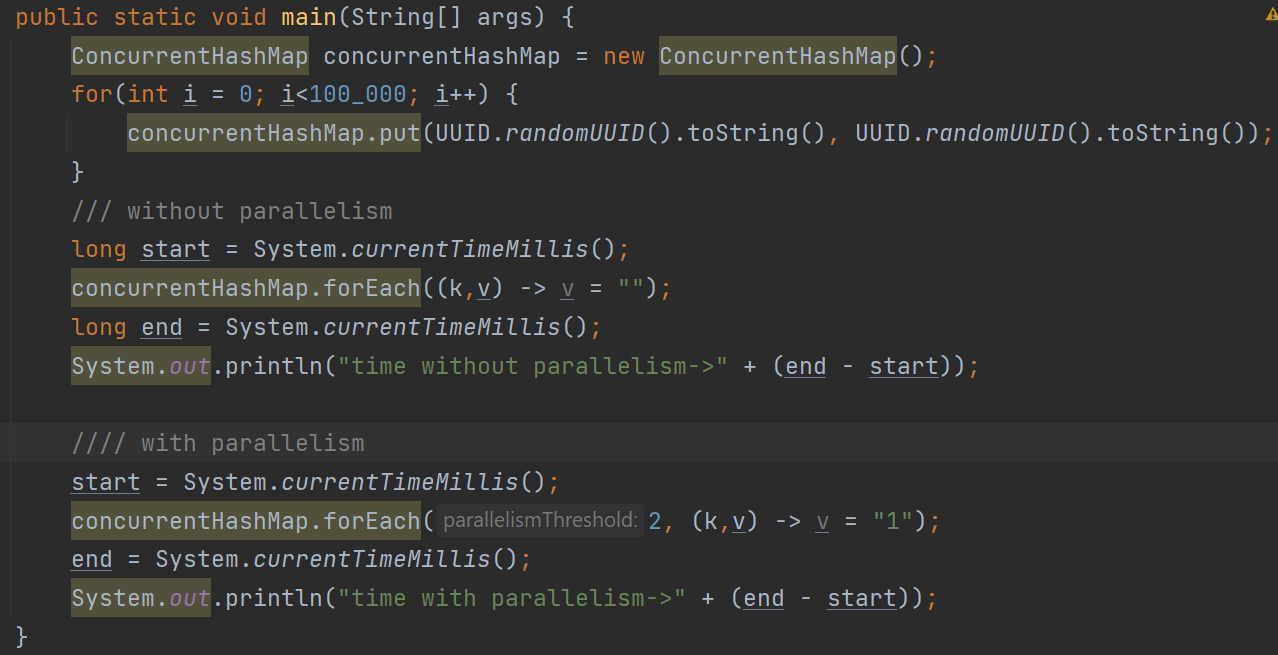
Fig: Comparison of the code both with and without parallelism
After running the above code, you can see there is a little performance improvement in the case of normal forEach operation.
time without parallelism->20 milliseconds
time with parallelism->30 milliseconds
This is because the number of records on the map is fairly low.
But if we add 10 million records to the map, then parallelism really wins! It takes less time to process the data. Take a look at the code in the below image:
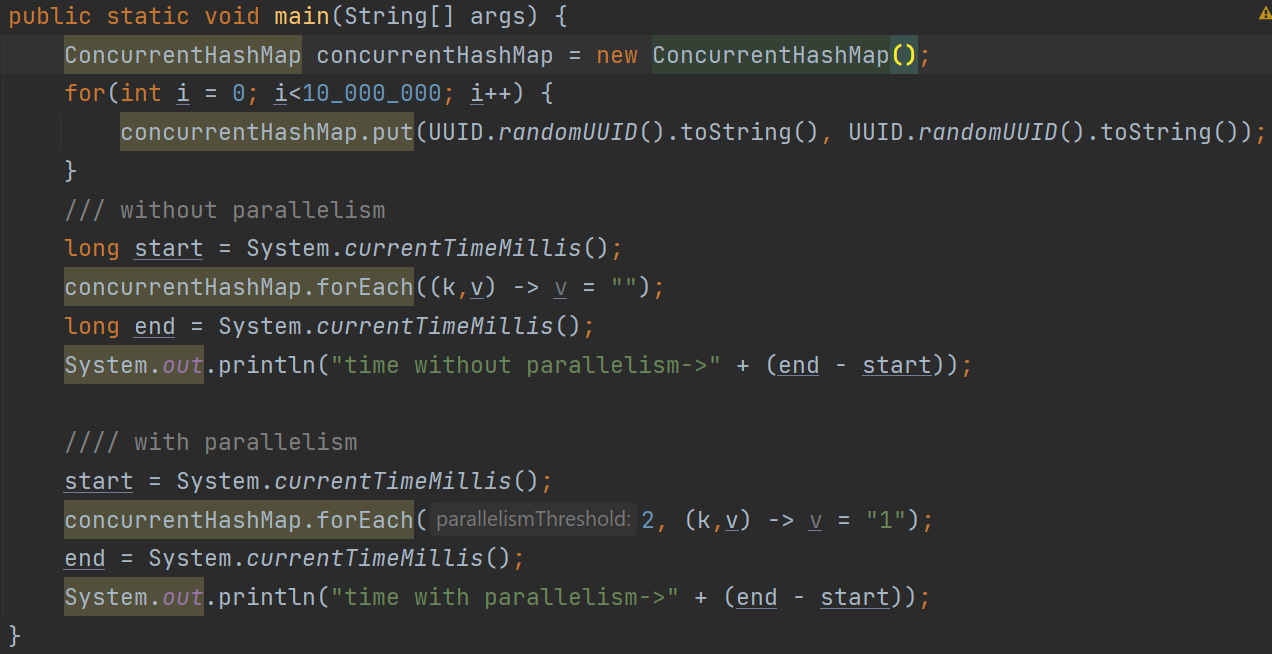 Fig: Threshold of the code with and without parallelism
Fig: Threshold of the code with and without parallelism
The above code replaces all the values in the concurrenthashmap with an empty string without using parallelism. Next, it uses parallelism to replace all the values of the concurrenthashmap with string one. This is the output:
time without parallelism->537 milliseconds
time with parallelism->231 milliseconds
You can see that in the case of parallelism, it only takes half of the time.
Note: The above values are not constant. It may produce different results in different systems.
Thread Dump Analysis for Parallelism
JVM uses the ForkJoinPool framework to enable parallel processing when we enable parallelism in the code. This framework creates a few worker threads based on the demand in the current processing. Let’s take a look at the thread dump analysis with parallelism enabled using the fastthread.io tool for the above code.
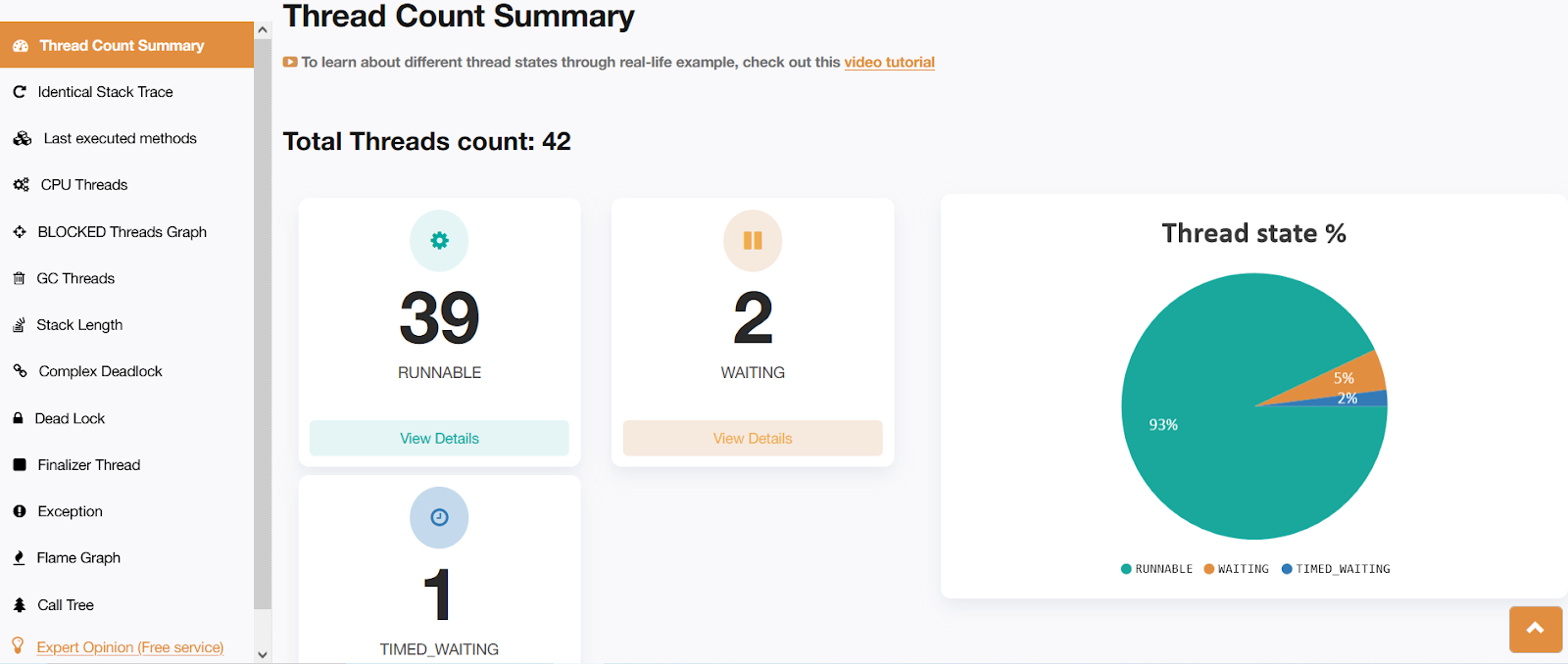
Fig: fastThread report showing the thread count with parallelism enabled
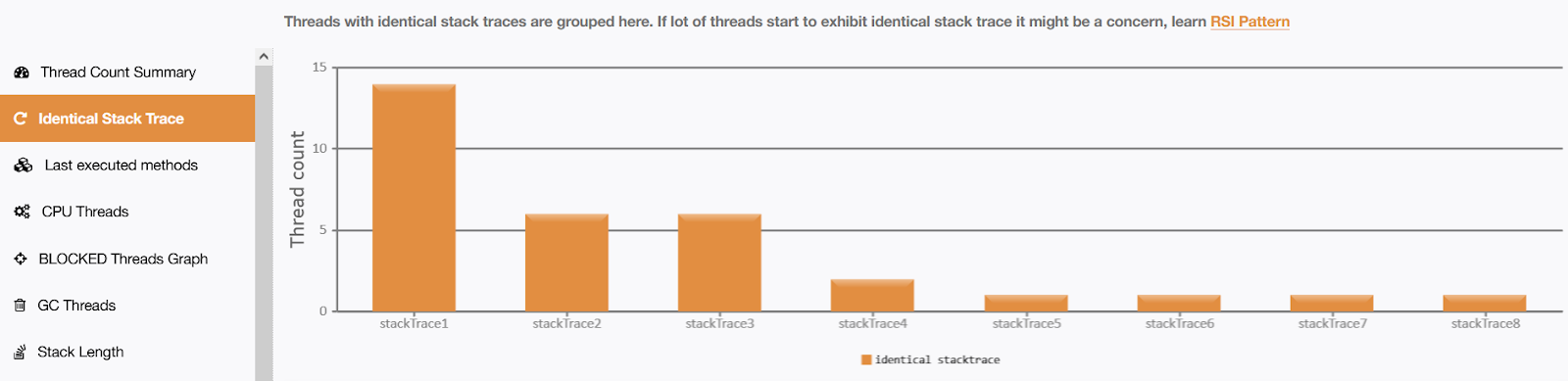
Fig: fastThread report showing the identical stacktrace by enabling parallelism
You can understand from the above picture that it is using more threads.
The reason for too many running threads is that it is using ForkJoinPool API. This is the API that is responsible for implementing the 'parallelism' behind the scenes. You will understand this difference when you look at the next section.
Thread Dumps Analysis Without Parallelism
Let us understand the thread dump analysis without enabling parallelism.
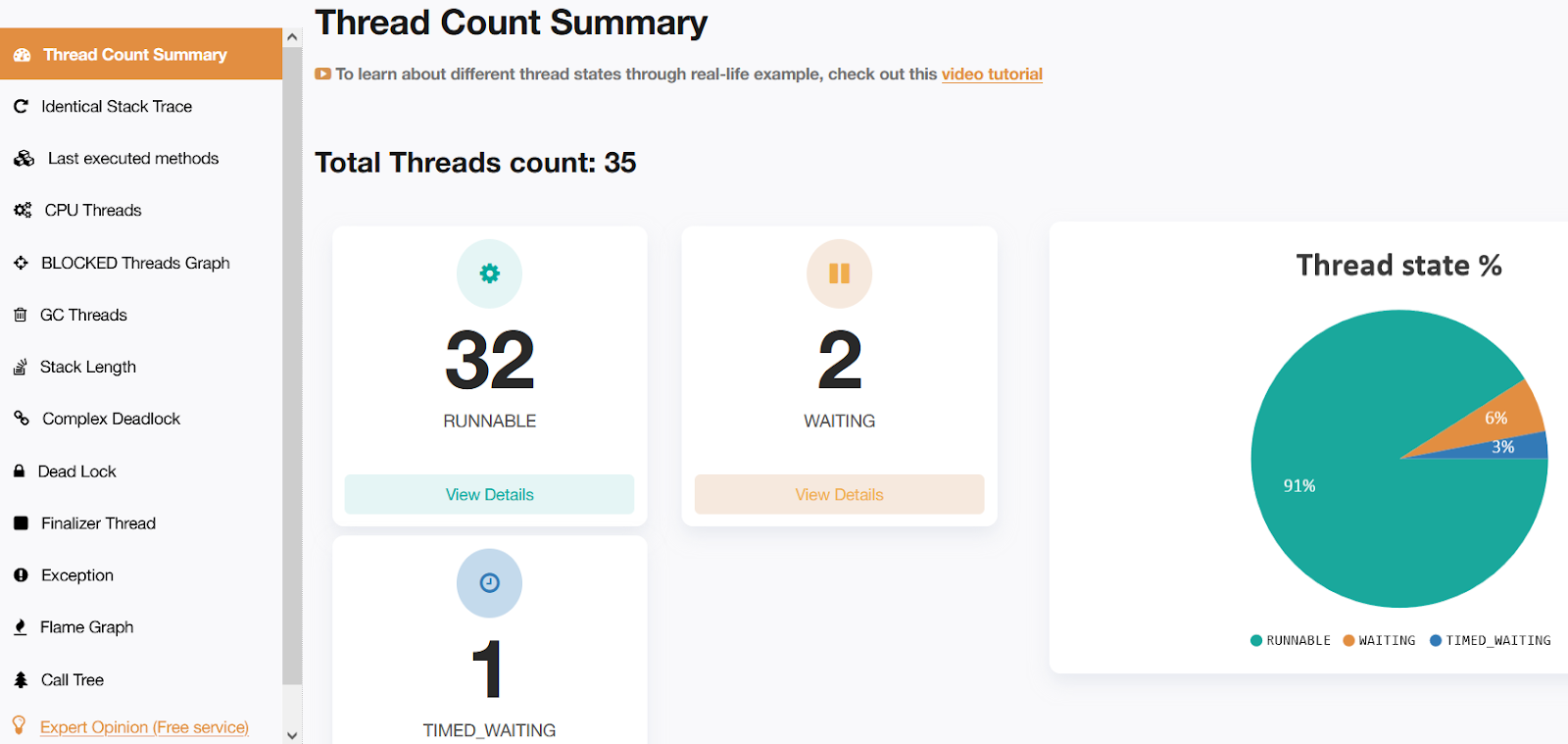 Fig: fastThread report showing thread count without parallelism enabled
Fig: fastThread report showing thread count without parallelism enabled
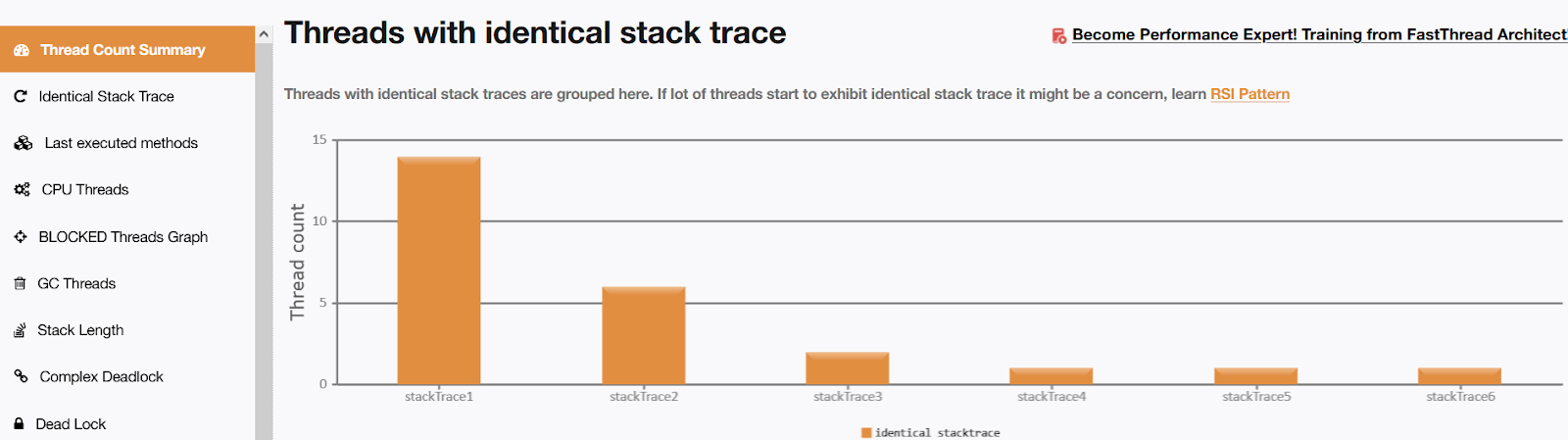 Fig: fastThread report showing the identical stacktrace without enabling parallelism
Fig: fastThread report showing the identical stacktrace without enabling parallelism
If you look closely at the above image, you can understand that only a few threads are used. In this case, there are only 35 threads as compared to the previous image. There are 32 runnable threads in this case. But, waiting and timed_waiting threads are 2 and 1, respectively. The reason for the reduced number of runnable threads, in this case, is that it is not calling the ForkJoinPool API.
This way, the fastthread.io tool can provide a good insight into the thread dump internals very smartly.
Summary
We focused on parallelism in the concurrenthashmap and how this feature can be used in the application. Also, we understood what happens with the JVM when we enable this feature. Parallelism is a cool feature that can be used well in modern concurrent applications.
Opinions expressed by DZone contributors are their own.
Comments