Part 1: Best Practices for Testing Data Integrations
Follow along in part one as we discover why assessing risks early and often is key and learn the best practices for addressing risks and risk mitigation.
Join the DZone community and get the full member experience.
Join For FreeIn this three-part series, we'll look at the best practices for testing data integrations, the quality risks for data integration projects, and how to develop a data integration master test plan. Follow along through part one of the series as we discover why assessing risks early and often is key, the best practices for addressing risks, and best practices for common risk mitigation.
Introduction
Leading data integration providers of services and tools continue to promote best practices to help their customers improve data quality. Data integrations are at the center of data warehousing, data migration, data synchronization, and data consolidation projects.
Data integration processes help gather structured and unstructured data from multiple sources into one location. Consolidating data to central repositories enables teams across an enterprise to gain deeper insights and actionable intelligence for more informed decision-making.
There can be many reasons for data integrations, including application replacements or upgrades, business process changes, data volume growth, and performance improvements. In the process of integration, data often needs to be made fit for purpose in the new system. This usually requires data validation, correction of problems in data sources – and data testing during data transformations, data format conversions, and complex data aggregations such as merging values or calculating new ones.
Data integration tool and service providers argue that “since every organization runs on data, its data must be complete, accurate, and delivered on time”. To achieve those goals, leaders on data integration projects should implement best practices throughout all phases of development and test.
Assess and Test Data Integration Project Risks – Early and Often
Data integration project stakeholders don’t always know for sure what they want to be delivered until they start seeing the data in data targets and as output from applications that use the data.
High data quality is the desired state when an organization’s data assets must reflect the following attributes:
- Clear definitions and meanings
- Correct values in sources during extractions, while loading to targets, and in analytic and business intelligence reports
- Understandable presentation format in analytic applications
- Beneficial in supporting targeted business processes
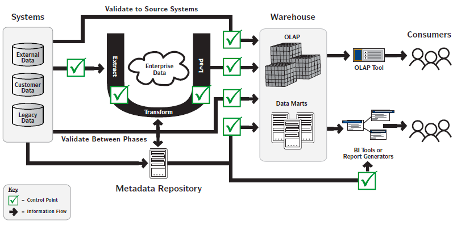
Figure 1 illustrates the primary checkpoints (testing points) in an end-to-end data quality auditing process. Shown are points at which data (as it’s extracted, transformed, aggregated, consolidated, etc.) should be verified – that is, extracting source data, transforming source data for loads into target databases, aggregating data for loads into data marts, and more.
Development is the project phase where team members implement and test the proposed architecture; it is in this phase where the most time is generally spent.
Only after data owners and other stakeholders confirm that the data integration was successful, can the whole process be considered complete.
Figure 1: Checkpoints that are necessary to audit and verify data quality in data integration projects. A data warehouse data integration example is shown in this figure. (©Tricentis)
Address Data Integration Risks with Best Practices
In this first of a series of blogs, we describe vital processes involved in data integration, which are typically complex and multi-phased. After integration requirements are documented and approved, the process continues with an analysis of available enterprise data sources culminating in the loading and reconciliation of data for new or upgraded applications.
Data integration is almost always a complex process where a wide variety of tests are necessary to ensure data quality. Such projects can be costly if best practices are not followed and hidden risks are not identified early and often.
In the past, most data integration projects involved data stored in databases. Today, it’s essential for organizations to also integrate their database or structured data with data from documents, e-mails, log files, websites, social media, audio, and video files.
Listed here are a few of the many data integration risks that can be mitigated while implementing project-wide and testing best practices.
Common Risks and Best Practice Mitigation
Source data architecture and data definition artifacts may be unavailable or incomplete to aid in project planning.
- Best Practice: Create or utilize meaningful documentation of data definitions, data descriptions, and data models.
Source data mapped incorrectly due to a lack of (or outdated) legacy system data dictionaries and data schemas.
- Best Practice: Ensure accurate and current documentation of data models and mapping documents.
Source data transformed inaccurately due to a lack of involvement of key business subject matter experts in the requirements and business rule process.
- Best Practice: Target data must be tested to ensure that all required data from data sources were integrated into the targets according to business and data transformation rules.
Independent data verifications not utilized; therefore- the quality of the target system data may not meet the enterprise standards.
- Best Practice: Implement independent data validation (e.g., QA department, off-shore testing) as a part of the scope of work.
These and many additional data integration risks (accompanied by associated best practices for reducing and eliminating each risk) will be presented in the next blog in this series.
Conclusion
Data integration projects are often inundated with potential risks -- from data quality in data sources to transformed values in data targets. If testing is not addressed suitably with best practices, data quality risks can bring entire projects to a halt leaving planners scrambling for cover, sponsors looking for remedies, and budgets wiped out.
Part two of the series is already published on DZone—keep learning and focus in on quality risks on your data integration projects.
Wayne Yaddow is an independent consultant with 20 years of experience leading data migration/integration/ETL testing projects at organizations such as J.P. Morgan Chase, Credit Suisse, Standard and Poor’s, and IBM. He has taught courses and coached IT staff on data warehouse, ETL, and data integration testing. Wayne continues to lead ETL testing and coaching projects on a consulting basis. [ wyaddow.academia.edu/research#papersandresearch]
Opinions expressed by DZone contributors are their own.
Comments