Performance of Array vs. Linked-List on Modern Computers
Linked-list might have been universally better than array at one point, but modern tech has since improved and array may be preferred.
Join the DZone community and get the full member experience.
Join For FreeA Few Notes
The array mentioned here is an automatically-resized array (vector in C++, ArrayList in Java or List in C#).
The benchmark graph between vector & list I showed in this post belongs to "Baptiste Wicht" in from this post (Thanks for saving my time for the benchmarking stuff).
From Theory...
People say Linked-list has much better performance than array when it comes to random-insertion & random-deletion. That's what we've learn in theory, too.
And I've seen many people around the internet suggest to use linked-list when we need to do a lots of random-insertion & random-deletion.
...To Practice
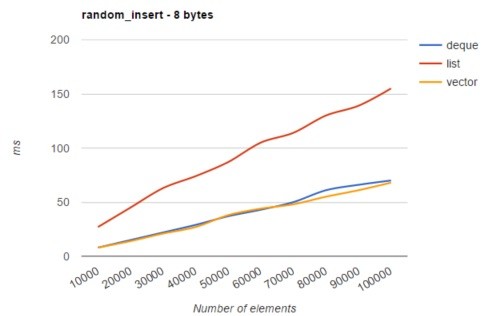
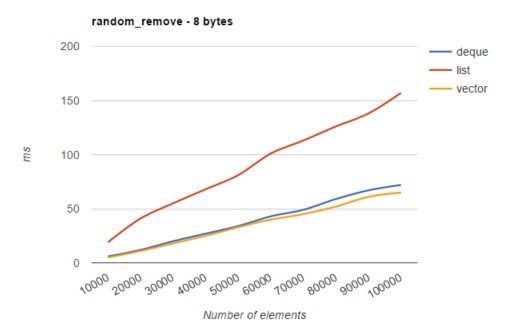
"Impossible!"
Note: The "list" above is implemented as doubly linked-list in C++. And the "vector" is implemented as an automatically-reallocated array in C++.
It's not that what people say is not true. It was once true in theory, in those old days when CPU speed was too slow. But now, the context has changed, and the architecture of computers has changed. Therefore, it might not be true anymore in some situations.
The CPU speed on modern computers is too fast, much faster than RAM-access speed. It would take about several hundred CPU cycles to read from RAM, which is way too slow. If that's the case, then most of the time, the CPU just sits there, drinks tea, and waits for its best friend—RAM.
And Then, CPU Caches Come into Play
The RAM-access speed is so slow that if CPU processes data directly on RAM, 99% of CPU speed will become a waste, and we can just make use of 1% of its power. Therefore, they invented CPU cache to solve this problem. The cache memory is very fast and is integrated directly on CPU. Its access speed is near the CPU speed. So now, instead of accessing data directly on RAM, CPU will access data on RAM indirectly through L1 cache (there are usually three levels of caches, and L1 cache is the fastest among them).
However, the CPU cache does not solve the problem completely because memory cache size is much smaller than RAM. We still need RAM as our main memory. And the CPU caches will just hold small pieces of data that are most likely to be needed by the CPU in the near future. Sometimes, the data that the CPU needs to access next is not already in L1 cache (nor in L2 or L3 cache), and it must be fetched from RAM, then the CPU will have to wait for several hundred cycles for the data to become available. This is what we call cache miss.
Therefore, to reduce cache miss, when the CPU wants to access data at address x in RAM, it will not only fetch the data at address x, but also the neighborhood of address x. Because we assume "if a particular memory location is referenced at a particular time, then it is likely that nearby memory locations will be referenced in the near future [3]." This is what we call locality of reference. So, if the data to be processed by the CPU is placed right next to each other, we can make use of locality of reference and reduce cache miss, which might cause huge performance overhead if it occurs often.
The Problem of Linked-List
Unlike array, which is a cache-friendly data structure because its elements are placed right next to each other, elements of linked-list can be placed anywhere in the memory. So when iterating through linked-list, it will cause a lot of cache miss (since we can't make use of locality of reference), and introduce lots of performance overheads.
Performance of Array vs Linked-List
When we perform random-insertion or random-deletion on an array, the subsequent elements need to be moved.
However, when it comes to a list of small elements (list of POD type, or list of pointers), the cost of moving elements around is chea, much cheaper than the cost of cache misses. Therefore, most of the time, when working with a list of small data types (whatever type of operations it is: from iterating, random-insertion, random deletion to number crunching), the performance of array will be much better than linked-list.
But when we need to work with a list of large elements ( > 32 bytes), the cost of moving elements around grows up to be higher than the cost of linked-lists "usual" cache misses. Then the linked list will have better performance than array.
Conclusion
We should prefer array over linked-list when working with a list of small elements, such as a list of POD type, a list of pointers in C++, or a list of references in Java/C#.
And nearly most of the time, we will use array because:
- In C++, we don't often store a list of large data type, but a list of pointers that point to large data type. If we do need to store a list of large-sized class/structure and need to do a lot of random-insertion and random-deletion, then linked-list would be a better choice.
- In Java, we're forced to use a list of references that point to an object in the heap, instead of a list of objects, because reference types are placed on the heap by default and we can just make a reference to it. Since reference is just a managed pointer, its size is no more than 8 bytes.
- In C#, we often use class instead of struct, so we also often have to deal with a list of references that point to object in the heap. And if we do use struct, we don't often create large struct since creating struct that has large size is a bad practice in C#.
CPU cache plays a very important role in performance improvement of programs on modern computers.
References
- [1] vector vs list performance benchmark, Baptiste Wicht: http://baptiste-wicht.com/posts/2012/11/cpp-benchmark-vector-vs-list.html
- [2] C++ vector, list, deque performance benchmark, Baptiste Wicht: http://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html
- [3] Locality of reference: https://en.wikipedia.org/wiki/Locality_of_reference
- [4] Understanding CPU caching and performance, Jon Stokes: http://arstechnica.com/gadgets/2002/07/caching/
Opinions expressed by DZone contributors are their own.
Comments