Performance Patterns in Microservices-Based Integrations
Almost all applications that perform anything useful for a given business need to be integrated with one or more applications. With microservices-based architecture, where a number of services are broken down based on the services or functionality offered, the number of integration points or touch points increases massively.
Join the DZone community and get the full member experience.
Join For FreeSystems based on microservices architectures are becoming more and more popular in IT environments. The rise of microservices increases the challenges associated with systems with multiple integrations. Almost all applications that perform anything useful for a given business need to be integrated with one or more applications. With microservices-based architecture, where a number of services are broken down based on the services or functionality offered, the number of integration points or touch points also increases massively. This can impact the system as a whole, since now overall system performance is also dependent upon external factors (the performance of an external system and its behavior).
Performance Patterns and Their Benefits
The concept of Design Patterns are well documented and understood in the software development world. These design patterns generally describe a reusable solution to a commonly occurring problem. Using design patterns can ensure good architectural design, but these alone are not enough to address performance challenges.
This is where performance patterns come into play. When implemented correctly, these can really help build a scalable solution.
Performance Challenges With Respect to Integrated Systems
Distributed computing has its own challenges, and all of these challenges are not only well documented, but are experienced by professionals working on distributed systems almost daily. While connecting to other microservices (within the same bounded context or of some remote, external system), many things can go wrong. Services and systems (both internal and external) you connect to may be slow or down. If your application is not designed to handle this scenario gracefully, it can have an adverse impact on the performance and stability of the overall application.
Performance Patterns
In this section we will talk about some approaches and design decisions that can help us achieve better performance, resilience, and overall stability with respect to integration challenges in a microservices-based environment.
Throttling
Throttling is one technique that can be used to prevent any misbehaving or rogue application from overloading or bringing down our application by sending more requests than what our application can handle.
One simple way to implement throttling is by providing a fixed number of connections to individual applications. For example, there are two vendors who call our microservice to deduct money from one account. If one vendor has a big application (like Amazon), then it is likely to consume our service more often than a vendor which has a small user base. We can provide these two vendors two separate and dedicated “entry points,” with dedicated throttled connection limits. This way, a large number of requests coming from Amazon will not hamper requests coming from a second vendor. Moreover, we can throttle individual partners so that none can send requests at a rate faster than what we can process.
Generally, synchronous requests from external services/systems are throttled at the load balancer/HTTP server or another such entry point.
Timeouts
If a microservice is responding slowly, it can cause our application to take longer to complete a request. Application threads now remain busy for a longer duration. This can have a cascading impact on our application, resulting in the application/server becoming totally choked/unresponsive.
Most libraries, APIs, frameworks, and servers provide configurable settings for different kinds of timeouts. You may need to set timeouts for read requests, write requests, wait timeouts, connection pool wait timeouts, keep alive timeouts, and so on. Values of these timeouts should be determined only by proper performance testing, SLA validation, etc.
Dedicated Thread Pools/Bulkheads
Consider a scenario where, in your application f low, you need to connect to five different microservices using REST over HTTP. You are also using a library to use a common thread pool for maintaining these connections. If, for some reason, one of the five services starts responding slowly, then all your pool members will be exhausted waiting for the response from this service.
To minimize the impact, it is always a good practice to have a dedicated pool for each individual service. This can minimize the impact caused by a misbehaving service, allowing your application to continue with other parts of the execution path.
This is commonly known as the bulkheads pattern. The following figure depicts a sample scenario of implementing a bulkhead. On the left side of the figure, microservice A—which is calling both microservice X and microservice Y—is using a single common pool to connect to these microservices. If either service X or service Y misbehaves, it could impact the overall behavior of the flow, since the connection pool is common. If a bulkhead is implemented instead (as shown in the right side of the figure), even if microservice X is misbehaving, only the pool for X will be impacted. The application can continue to offer functionality that depends on microservice Y.
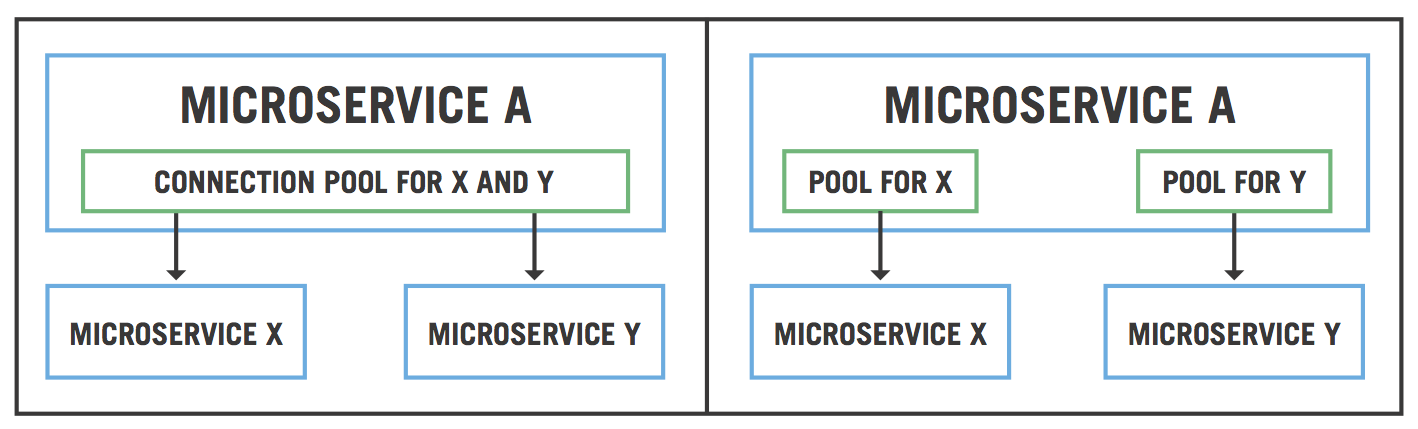
How Bulkheads Work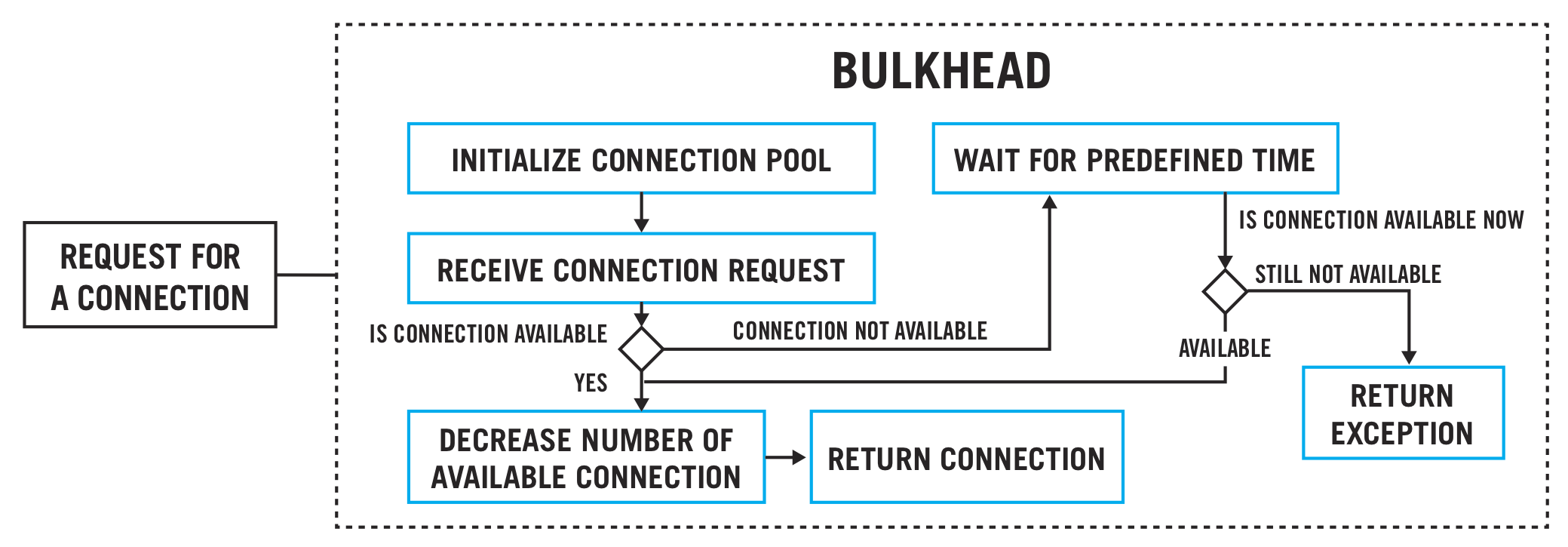
Critical Details
Any application that needs to connect to a component will request a connection to that component.
Connection to each of the components is controlled by the individual bulkhead.
When a request for a new connection is made, the bulkhead will check if the connection to the requested component is available to serve the request.
If the connection is available, it will allocate this connection to serve the request.
In case no free connection is available, the bulkhead will wait for a pre-defined time interval.
If any connection becomes available during this wait period, it will be allocated to serve the waiting request.
Circuit Breakers
A Circuit Breaker is a design pattern, which is used to minimize the impact of any of the downstream being not accessible or down (due to planned or unplanned outages). Circuit breakers are used to check the availability of external systems/services, and in case these are down, applications can be prevented from sending requests to these external systems. This acts as a safety measure, on top of timeouts/bulkheads, where one may not want to even wait for the period specified by timeout. If a downstream system is down, it is of no use to wait for the TIMEOUT period for each request, and then getting a response of timeout exception.
Circuit breakers can have built in logic to perform necessary health checks of external systems.
Synchronous Integration
Most performance issues related to integrations can be avoided by decoupling the communications between microservices. The asynchronous integration approach provides one such mechanism to achieve this decoupling. Take a look at the design of your microservices-based system, and give it a serious thought if you see point-to-point integration between two microservices.
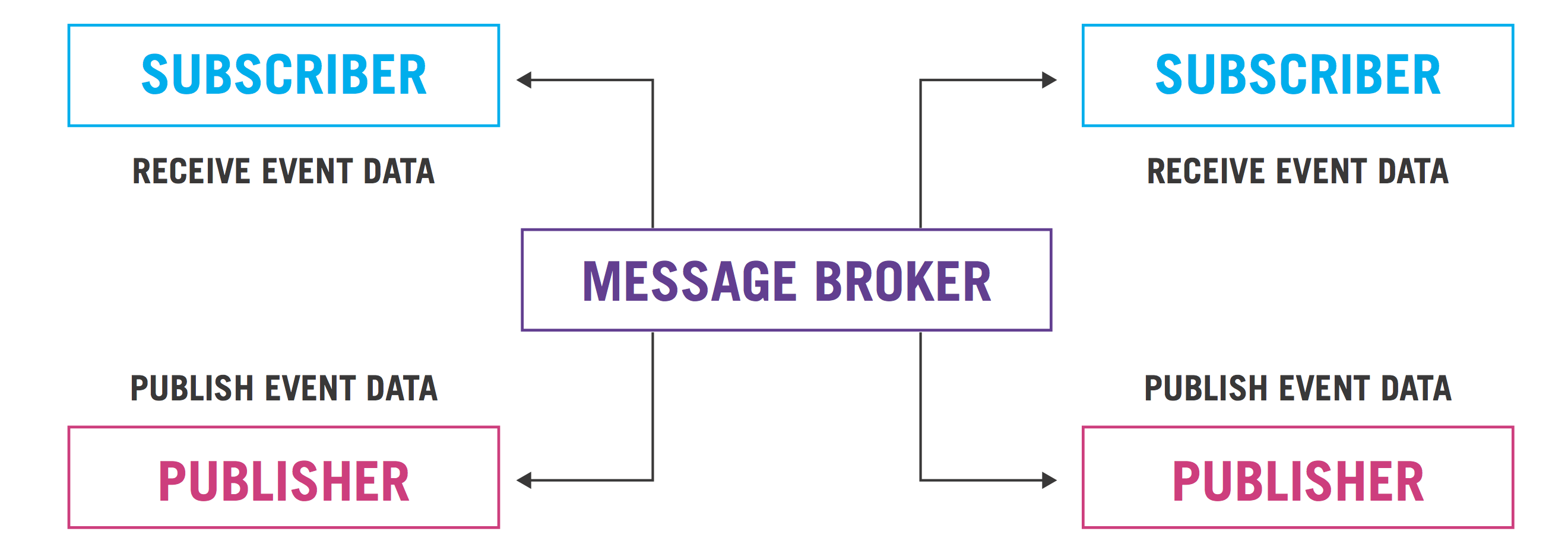
Any standard message broker system can be used to provide publish-subscribe capabilities. Another way to achieve asynchronous integration is to use event-driven architecture.
The following figure shows a scenario, where decoupling between producers and receivers/subscribers is achieved with the use of a message broker.
Conclusion
In this article, we talked about some of the performance challenges we face while integrating microservices-based systems. It also presented some patterns that can be used to avoid these performance issues. We discussed throttling, timeout, bulkheads and circuit breaker patterns. Apart from these, an asynchronous integration approach is also discussed.
In a nutshell, asynchronous integration should be preferred, wherever possible. Other patterns can also be used in integration scenarios to avoid the ripple/cascading side effect of a misbehaving downstream system.
Opinions expressed by DZone contributors are their own.
Comments