Personalized Search Optimization Using Semantic Models and Context-Aware NLP for Improved Results
This tutorial shows how to build a semantic search engine using Hugging Face transformers to deliver more accurate, context-aware results.
Join the DZone community and get the full member experience.
Join For FreeHave you ever wondered how search engines like Google interpret phrases such as "budget-friendly vacation spots" and "cheap places to travel" as essentially the same query? That’s the power of semantic search. Traditional search engines rely heavily on exact keyword matches. They only find documents or results that contain the exact words entered in a query. For example, if you search for "budget-friendly vacation spots," a keyword-based search engine would return results containing those exact terms. However, this method falls short when it comes to understanding the nuances of human language, such as synonyms, different phrasing, or the intent behind the words.
For instance, one user might search for "affordable beach resorts," while another might search for "cheap seaside hotels." Both queries refer to similar types of accommodations, but traditional search engines might fail to connect these two searches effectively due to differing phrasing.
This is where semantic search comes in. Unlike traditional keyword-based search, semantic search engines understand the meaning behind the words, not just the words themselves. They are capable of recognizing that terms like "affordable," "cheap," "inexpensive," and "budget-friendly" all refer to the same concept: affordable travel options. Similarly, they can also understand that "beachfront resort" and "seaside hotel" are conceptually similar, even though they are expressed in different words.
In this tutorial, we will build a production-ready semantic search engine for travel accommodations using Hugging Face transformers. The goal is to create a system that can interpret user queries and return the most relevant results, considering the semantic meaning of the queries rather than just exact keyword matches. Additionally, we will incorporate contextual relevance, such as user preferences for location, price, ratings, and seasonality, to create a highly personalized and effective search experience.
What Is Semantic Search?
At its core, semantic search improves the search experience by focusing on meaning and context rather than simply matching keywords. Traditional search engines treat queries as literal strings, matching the words exactly as they are typed. This approach often fails to account for the various ways a query might be phrased or the nuances of a user's intent.
Semantic search engines, on the other hand, look at the intent behind the query and attempt to retrieve results that are semantically similar to what the user is searching for. Instead of just matching the query with exact words, a semantic search engine tries to understand the meaning of the words and phrases involved.
For example, consider the following search queries:
- "Best beach resorts in California"
- "Top coastal resorts near Los Angeles"
- "Seaside luxury hotels in Southern California"
Though the wording differs, all these queries likely refer to similar types of accommodations — beachfront or seaside resorts located in California. A semantic search engine would recognize that terms like “beach resort,” “coastal resort,” and “seaside luxury hotel” are conceptually similar, even though they don’t share the same keywords. By understanding the meaning behind these terms, the semantic search engine can rank results based on relevance to the user’s intent.
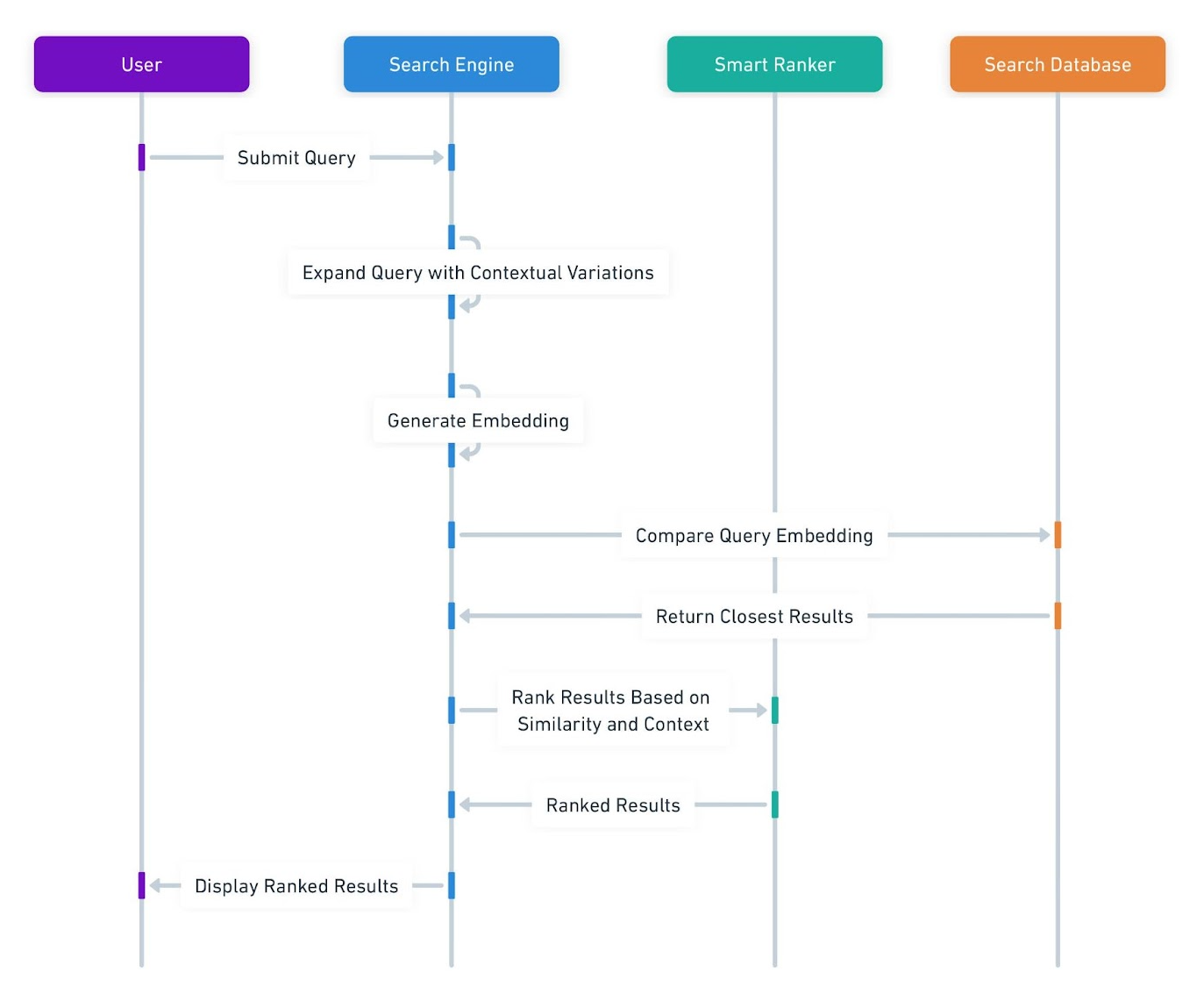
This diagram outlines the sequence of events in a semantic search engine's workflow, highlighting how the system processes a user query and returns semantically relevant results.
How Does Semantic Search Work?
Semantic search relies on a few key principles and technologies that allow it to understand and rank results based on meaning rather than exact keyword matches:
1. Word Embeddings and Sentence Embeddings
A word embedding is a vector (a list of numbers) that represents a word in a way that reflects its semantic meaning. Words that are semantically similar, like "car" and "automobile," will have similar embeddings, meaning their vector representations will be close to each other in a multi-dimensional space.
More advanced models, like sentence embeddings, represent entire sentences or phrases as vectors. This is useful because it allows you to compare not only individual words but also entire queries or documents. These embeddings are generated using transformer models, such as those provided by Hugging Face, which have been pre-trained on large text datasets and understand semantic relationships between words, phrases, and sentences.
2. Contextual Understanding
Unlike traditional keyword-based searches, semantic search models incorporate the context of a query. This means that the search engine takes into account synonyms, word order, and even implicit relationships between words to deliver more accurate and contextually relevant results.
For example, if a user searches for "cheap beach resorts in California," the search engine can expand the term "cheap" to include related terms like "affordable," "budget-friendly," or "inexpensive" based on the context, leading to more relevant search results.
3. Vector Space Models
Once a query is transformed into an embedding, the search engine compares it to a database of embeddings representing potential results (such as travel accommodations or documents). This comparison is done by calculating the cosine similarity or Euclidean distance between the vectors, which tells the system how similar the query is to the items in the database.
The closer the vectors, the more semantically similar the query and result are. This allows the system to rank results based on semantic relevance rather than simply matching keywords. The results with the highest similarity score are presented to the user.
4. Retrieving and Ranking
After matching the query embedding to the embeddings of potential results, the search engine ranks the results based on their semantic similarity to the query. The results with the highest similarity are displayed first. To further enhance relevance, a production-ready semantic search engine can incorporate additional ranking factors, such as user preferences (e.g., price range, location), ratings, and seasonality (e.g., travel preferences for summer versus winter).
The Problem With Traditional Search
Consider a travel platform where users search for accommodations. Here's a common issue with traditional keyword search:
# Traditional keyword-based search
destinations = [
{"name": "Sunset Resort", "description": "Budget-friendly beachfront accommodation"},
{"name": "Mountain Lodge", "description": "Affordable mountain getaway"},
{"name": "City Center Hotel", "description": "Cost-effective downtown location"}
]
def basic_search(query):
return [d for d in destinations if query.lower() in d['description'].lower()]
# Search for "cheap hotels"
results = basic_search("cheap hotels")
print(f"Found results: {len(results)}") # Output: Found results: 0
Despite having multiple affordable options, our search fails because:
- It lacks an understanding of synonyms (e.g., "cheap," "budget-friendly," and "affordable").
- It misses context (the type of accommodation).
- It cannot handle semantic variations.
Building a Better Solution: TravelSearchAI
Let’s create a comprehensive semantic search engine for a travel platform, utilizing Hugging Face's transformers and real-world data.
1. Setting Up the Data Structure
We will start by defining a data structure for our accommodations:
from dataclasses import dataclass
from typing import List, Optional
from datetime import datetime
import numpy as np
from transformers import AutoModel, AutoTokenizer
@dataclass
class Accommodation:
id: str
name: str
description: str
location: str
price_per_night: float
amenities: List[str]
reviews: List[str]
rating: float
embedding: Optional[np.ndarray] = None
def to_searchable_text(self) -> str:
"""Combine all relevant fields into searchable text."""
amenities_text = ", ".join(self.amenities)
reviews_text = " ".join(self.reviews[:5]) # Use first 5 reviews
return f"{self.name} in {self.location}. {self.description}. " \
f"Features: {amenities_text}. Guest reviews: {reviews_text}"
class AccommodationProcessor:
def __init__(self, model_name: str = "sentence-transformers/all-MiniLM-L6-v2"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
def create_embedding(self, text: str) -> np.ndarray:
"""Create an embedding for text using Hugging Face model."""
inputs = self.tokenizer(text, return_tensors="pt",
max_length=512, truncation=True, padding=True)
outputs = self.model(**inputs)
return outputs.last_hidden_state.mean(dim=1).detach().numpy()
2. Building the Search Engine Core
Next, we will create the core of our search engine, which will incorporate vector similarity and context awareness:
import faiss
from dataclasses import dataclass
from typing import List, Tuple
@dataclass
class SearchResult:
accommodation: Accommodation
score: float
relevance_factors: dict
class TravelSearchEngine:
def __init__(self, embedding_dim: int = 384):
self.index = faiss.IndexFlatL2(embedding_dim)
self.accommodations: List[Accommodation] = []
self.processor = AccommodationProcessor()
def add_accommodations(self, accommodations: List[Accommodation],
batch_size: int = 32):
"""Add accommodations to the search index with batching."""
for i in range(0, len(accommodations), batch_size):
batch = accommodations[i:i + batch_size]
embeddings = []
for acc in batch:
text = acc.to_searchable_text()
acc.embedding = self.processor.create_embedding(text)
embeddings.append(acc.embedding)
vectors = np.vstack(embeddings)
self.index.add(vectors)
self.accommodations.extend(batch)
def _expand_query(self, query: str) -> str:
"""Expand query with semantic variations."""
expansions = {
'cheap': ['affordable', 'budget', 'inexpensive'],
'luxury': ['high-end', 'premium', 'upscale'],
'beach': ['seaside', 'oceanfront', 'coastal'],
'city': ['downtown', 'urban', 'metropolitan']
}
expanded = query
for term, synonyms in expansions.items():
if term in query.lower():
expanded += f" {' '.join(synonyms)}"
return expanded
3. Adding Smart Ranking and Filters
To enhance our search results' relevance, we will implement contextual ranking:
class SmartRanker:
def __init__(self):
self.price_ranges = {
'budget': (0, 100),
'mid-range': (100, 250),
'luxury': (250, float('inf'))
}
def rank_results(self, results: List[SearchResult],
context: dict) -> List[SearchResult]:
"""Rank results based on multiple factors."""
for result in results:
score_adjustments = {
'price_match': self._calculate_price_match(
result.accommodation, context.get('budget')),
'rating_boost': result.accommodation.rating * 0.1,
'location_relevance': self._calculate_location_relevance(
result.accommodation, context.get('location')),
'seasonal_boost': self._calculate_seasonal_boost(
result.accommodation, context.get('date'))
}
# Combine scores
result.score *= sum(score_adjustments.values())
result.relevance_factors = score_adjustments
return sorted(results, key=lambda x: x.score, reverse=True)
def _calculate_price_match(self,
accommodation: Accommodation,
budget: float) -> float:
if not budget:
return 1.0
return 1.0 / (1.0 + abs(accommodation.price_per_night - budget))
def _calculate_location_relevance(self,
accommodation: Accommodation,
target_location: str) -> float:
if not target_location:
return 1.0
# Implement location matching logic here
return 1.0
def _calculate_seasonal_boost(self,
accommodation: Accommodation,
travel_date: datetime) -> float:
if not travel_date:
return 1.0
# Implement seasonal scoring logic here
return 1.0
4. Putting It All Together: A Complete Example
Here’s how to utilize our semantic travel search engine:
# Create sample data
def create_sample_accommodations():
return [
Accommodation(
id="1",
name="Beachfront Paradise",
description="Luxury beachfront resort with stunning ocean views",
location="Malibu, CA",
price_per_night=299.99,
amenities=["Pool", "Spa", "Restaurant", "Beach access"],
reviews=["Amazing beach views!", "Excellent service"],
rating=4.8
),
Accommodation(
id="2",
name="Downtown Boutique",
description="Affordable boutique hotel in city center",
location="Portland, OR",
price_per_night=149.99,
amenities=["Free WiFi", "Restaurant", "Business Center"],
reviews=["Great location!", "Perfect for business travelers"],
rating=4.5
)
]
# Initialize the search engine
engine = TravelSearchEngine()
ranker = SmartRanker()
# Add sample accommodations
accommodations = create_sample_accommodations()
engine.add_accommodations(accommodations)
# Example search function
def search_accommodations(query: str, context: dict = None):
"""
Search accommodations with context awareness.
Args:
query: Search query (e.g., "beach resort near LA").
context: Additional context (budget, dates, location preferences).
"""
# Expand query
expanded_query = engine._expand_query(query)
# Get initial results
results = engine.search(expanded_query, k=10)
# Apply smart ranking
if context:
results = ranker.rank_results(results, context)
# Display results
for result in results:
print(f"\n{result.accommodation.name}")
print(f"Location: {result.accommodation.location}")
print(f"Price: ${result.accommodation.price_per_night:.2f}/night")
print(f"Rating: {result.accommodation.rating}⭐")
print(f"Relevance Score: {result.score:.2f}")
print("Relevance Factors:", result.relevance_factors)
# Example usage
search_context = {
'budget': 200,
'location': 'California',
'date': datetime(2024, 7, 1)
}
search_accommodations("affordable beach resort", search_context)
Production Considerations
1. Performance Optimization
To enhance performance, we can implement caching and optimize our indexing strategy:
from functools import lru_cache
class CachedSearchEngine(TravelSearchEngine):
@lru_cache(maxsize=1000)
def get_query_embedding(self, query: str) -> np.ndarray:
"""Cache query embeddings for frequent searches."""
return self.processor.create_embedding(query)
def optimize_index(self):
"""Convert to a more efficient index type for large datasets."""
if len(self.accommodations) > 100000:
# Convert to IVF index for better scaling
nlist = int(np.sqrt(len(self.accommodations)))
quantizer = faiss.IndexFlatL2(self.embedding_dim)
new_index = faiss.IndexIVFFlat(quantizer,
self.embedding_dim,
nlist)
new_index.train(self.get_all_vectors())
new_index.add(self.get_all_vectors())
self.index = new_index
2. Monitoring and Analytics
To gather insights and improve performance, we can implement analytics:
class SearchAnalytics:
def __init__(self):
self.searches = []
def log_search(self, query: str, results: List[SearchResult],
selected_result: Optional[str]):
"""Log search data for analysis."""
self.searches.append({
'timestamp': datetime.now(),
'query': query,
'num_results': len(results),
'top_result': results[0].accommodation.id if results else None,
'selected_result': selected_result,
'conversion': selected_result is not None
})
def get_metrics(self) -> dict:
"""Calculate key search metrics."""
total_searches = len(self.searches)
conversions = sum(1 for s in self.searches if s['conversion'])
return {
'total_searches': total_searches,
'conversion_rate': conversions / total_searches if total_searches else 0,
'zero_results_rate': sum(1 for s in self.searches
if s['num_results'] == 0) / total_searches
}
Best Practices and Tips
Creating a robust semantic search engine involves ongoing attention to various aspects. Below are best practices to ensure effective operation and user experience.
Data Quality
- Regularly update accommodation data: Implement systems for real-time updates and scheduled reviews to maintain data accuracy.
- Clean and normalize text data: Use consistent naming conventions and NLP techniques to standardize data entries.
- Maintain a standardized format: Establish a clear schema for accommodation representation and validation rules.
Performance
- Utilize batch processing: Optimize updates through bulk inserts and asynchronous processing.
- Implement caching: Use in-memory stores and query result caching to speed up response times.
- Monitor memory usage: Use profiling tools to keep an eye on memory usage and be ready to scale infrastructure as needed.
User Experience
- Provide relevant filters: Allow users to filter by amenities, price ranges, and ratings for a more tailored experience.
- Explain ranking decisions: Build user trust by explaining why certain results are ranked higher.
- Implement auto-suggestions: Enhance user interaction by predicting queries based on historical data.
Enhancement Roadmap
To continuously improve the search engine, consider the following advancements:
- Implement multi-language support: Expand capabilities to support multiple languages with automatic detection and translation services.
- Add image similarity search: Incorporate visual search features to allow users to find accommodations based on images.
- Integrate external APIs: Fetch real-time data and user reviews from third-party services to enhance content richness.
- Introduce personalization: Tailor search results based on user profiles and past searches.
- Establish A/B testing framework: Continuously evaluate performance through experimentation and user feedback.
Conclusion
In this guide, we built a production-ready semantic search engine capable of comprehending user queries and ranking results based on various contextual factors. Leveraging Hugging Face transformers alongside intelligent ranking methodologies allows our solution to surpass simple keyword matching, delivering relevant and personalized results for users searching for travel accommodations. By following the outlined best practices and continuously evolving based on user feedback and performance metrics, you can create a search engine that stands out in an increasingly competitive landscape.
Opinions expressed by DZone contributors are their own.
Comments