PostgreSQL Kubernetes: How to Run HA Postgres on Kubernetes
This article will show you how you can run PostgreSQL in production on Kubernetes so you can answer some of the questions listed below.
Join the DZone community and get the full member experience.
Join For Free![]()
![]()
Thanks to advances in the container ecosystem recently (Kubernetes stateful sets, PVCs, etc), getting started running PostgreSQL in a container is easy. However, running PostgreSQL in production still requires a lot of forethought and planning. Here are some of the things you need to think about when running PostgreSQL on Kubernetes in production:
- How do I automatically deploy a new PostgreSQL instance in the cloud or on-prem data center?
- How do I failover a PostgreSQL pod to another availability zone or rack if my PostgreSQL instance goes down?
- How do I resize my PostgreSQL volume if I am running out of space?
- How do I snapshot and backup PostgreSQL for disaster recovery?
- How do I test upgrades?
- Can I take my PostgreSQL deployment and run it in any environment if needed? Whether that is AWS, GCE, Azure, VMWare, OpenStack, or bare metal?
This article will show you how you can run PostgreSQL in production on Kubernetes so you can easily answer these questions. After reading through the following steps, you will understand how to run an HA PostgreSQL cluster in production using Kubernetes.
The Essential Steps to Run HA PostgreSQL on Kubernetes
This post will walk you step-by-step through how to deploy and manage an HA PostgreSQL cluster on Kubernetes. Before getting into all that detail. Let's summarize.
There are 5 basic steps to run HA PostgreSQL:
- Chose a multi-cloud container orchestration platform like Kubernetes
- Install multi-cloud container storage solution like Portworx
- For a simple and efficient HA setup, run a single instance of PostgreSQL and set px replication to <code>repl:"3"</code>
- For scale-out, high performance, use PostgreSQL replication to send read-only requests to secondaries but keep px replication to <code>repl:"3" or "2"<code> for faster failover and lower total number of instances at scale.
- Optionally set <code>io_priority:"high"</code> to schedule PostgreSQL instance on fast storage medium for better IO performance. Use a journal device with your volumes to speed up performance.
Read on for more details about running an HA PostgreSQL cluster on Kubernetes. Follow this link to launch the PostgreSQL Kubernetes Katacoda tutorial.
Achieving HA with PostgreSQL
PostgreSQL can run in a single node configuration and in a clustered configuration using different alternative solutions for asynchronous or synchronous replication as of PostgreSQL 9.1. The preferred replication technique with PostgreSQL is the use of a Write Ahead Log (WAL). By writing the log of actions before applying them to the database the PostgreSQL master, state can be replicated on any secondary by replaying the set of actions.
For deployments where you require replication for data protection but where a single database instance is capable of handling the read requests, a single Postgres pod with Portworx replicated volumes offers a simpler and more cost-effective solution to running HA PostgreSQL on Kubernetes.
With Portworx, each PostgreSQL Master and Secondary can have its PVC synchronously replicated. This makes recovering database instances a near-zero cost operation, which results in shorter recovery windows and higher total uptime. Our test also shows the elimination of the degradation in performance during the PostgreSQL recovery process when the state has to be recovered from the other database instances. With Portworx and Kubernetes, database instance recovery can take less than 30 seconds.
This is far less complex to manage and configure and requires ⅓ of the PostgreSQL Pods and therefore ⅓ of the CPU and Memory because Portworx is already running on your Kubernetes cluster and synchronously replicates data for all of your applications with great efficiency and scale.
Deploying PostgreSQL on Kubernetes
When deploying PostgreSQL on Kubernetes, the container image captures the database version and libraries while Kubernetes has the abstractions necessary to capture the database configurations, deployment topology, and storage configuration. There are different choices of container images for the database itself but also for running other PostgreSQL specific infrastructure and configuring them.
The Crunchy Data team has created an extensive set of containers as well as Kubernetes artifacts that we recommend taking a look at here. They also create a Kubernetes Postgres Operator to help with the management of large number of PostgreSQL instances and clusters in a single Kubernetes environment.
Helm charts are useful to quickly get started deploying a wide variety of databases onto Kubernetes, including PostgreSQL. For our tests, we used the Patroni helm chart to deploy a replicated 3 node cluster and we used a PostgreSQL helm chart to deploy a single node PostgreSQL instance. For the single instance configuration looks something like this:
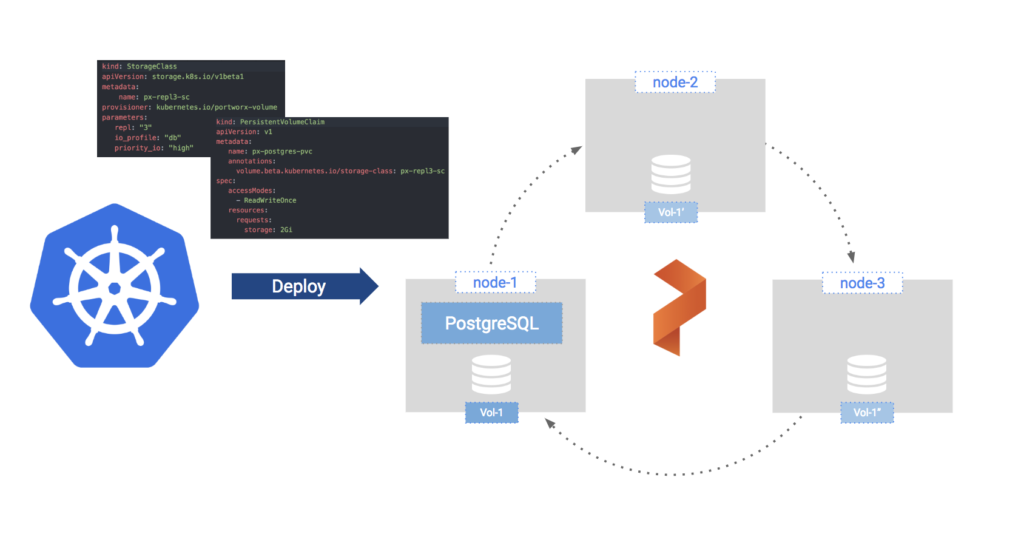
Figure 1: PostgreSQL Running on Portworx Replicated Volume
| HA PostgreSQL config | Postgres pods required | Volumes required |
|---|---|---|
| Without Portworx replication | 3 | 3 |
| With Portworx replication | 1 (1/3 the pods for the same reliability!) | 3 |
Table 1: Resource utilization with Portworx replication versus with PostgreSQL
In figure 1, we define a Kubernetes Storage Class object that declaratively defines how we want to handle storage for MongoDB:
kind: StorageClass
apiVersion: storage.k8s.io/v1beta1
metadata:
name: px-ha-sc
provisioner: kubernetes.io/portworx-volume
parameters:
repl: "3"
io_profile: "db"
io_priority: "high"
Along with the repl:"3", io_profile:"db", and io_priority"high" settings, we can add Kubernetes snapshot schedules and Kubernetes data encryption policy directly in this storage class definition. This declarative style of configuration is exactly what modern cloud-native infrastructure is all about. No more snowflakes, you can recreate whole environments from source code, including the automation of your common data management tasks.
And finally, we will pass in the defined storage class as a parameter for the PostgreSQL Helm chart:helm install --name px-psql --set persistence.storageClass=px-repl3-sc stable/postgresql
There are cases where running a single PostgreSQL instance is not going to cut it and when we will want to spread our reads to the secondary nodes which are part of our PostgreSQL secondary pool. For these scenarios, you can leverage the Kubernetes Stateful Sets to handle all the replica set configuration for you and still get all the agility benefits from Portworx by using the storage class for Portworx in the same way as before. There is a Patroni incubator Helm chart available for this and it can very easily be used with Portworx as follows:
helm repo add incubator https://kubernetes-charts-incubator.storage.googleapis.com/
helm install --name px -f k8s-yaml/patroni-values.yaml incubator/patroni
The patroni-values.yaml file includes the name of the storage class as well as other deployment parameters like the number of instances in the cluster and address to the ETCD host Patroni uses to do master election. You can see the full file in the git repo for the simple REST API we create using Spring Boot and Spring JPA to test failover performance under load here: https://github.com/fmrtl73/px-jpa-rest.
You can choose to turn off Portworx replication in this case but we recommend that you set it to replication factor of 2 so that when nodes go away and restart the synchronization process is much faster. When one of the Postgres instances gets restarted it doesn't have to rebuild the dataset from scratch because it can start with a copy of the volume that is consistent up to the time of the crash. This helps you reduce the instance outage window which in turn can help you reduce the total size of your cluster while keeping similar uptime guarantees. This in turn allows you to save on your total compute, memory, and network utilisation.
Failover PostgreSQL Pod on Kubernetes
Now, let's walk through a failover scenario. In the linked katacoda tutorial, we will simulate a node failure by cordoning the Kubernetes nodes where PostgreSQL is running and then deleting the PostgreSQL pod.
Once Kubernetes identifies that the pod needs to be rescheduled, it will work with Portworx's Kubernetes scheduler extender, STORK, to identify which node is best suited to host the restarted pod. In our small environment, any of the two remaining nodes will do because we have a copy of the data on all three nodes. In reality, you will likely have much larger clusters and that's when STORK will benefit you by making sure the pod starts on a node where a copy of the data is locally stored. In the unlikely event that your pod cannot be started on one of those nodes, it will be able to start on any of the cluster nodes and access it's data seamlessly through the Portworx storage fabric.
This failover should all happen within a very short time window, which is very similar to the Postgres replication configuration described above. This failover is depicted in the figure below:
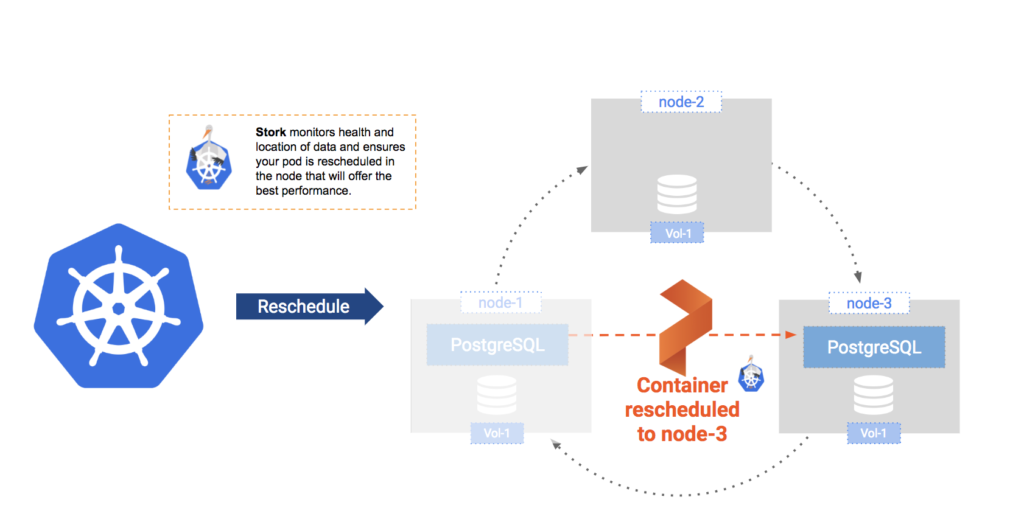
Figure 2: PostgreSQL Failover
PostgreSQL Storage Operations
So, it seems that just for Reliability and High Availability alone it would be worth running PostgreSQL on Kubernetes and Portworx, but there is a lot more that you can do. So many of the data management operations that are error prone and time consuming are now going to be fully automated the same way in any cloud environment. First, we'll show how volumes can be dynamically expanded without reconfiguring or restarting PostgreSQL, and then we will show how Snapshots can be easily restored.
Resize Postgres Volume on Kubernetes
Data management tasks like these need to be predictable and automatable when it makes sense to do so. The PostgreSQL Kubernetes Katacoda tutorial embedded at the bottom of this post will show how a simple command run from your Kubernetes command line interface can expand the PostgreSQL volume with zero downtime. Since Portworx volumes are virtual and carved out of your aggregate storage pool on your cluster, we thinly provision the volumes so that the expansion doesn't immediately require you to add more storage capacity to your cluster. For information about expanding storage capacity, view our docs.
Snapshot PostgreSQL on Kubernetes
Snapshots can be scheduled as part of your storage class definition by using the Portworx command line interface (pxctl) or taken on demand by using Stork. Stork uses the external-storage project from kubernetes-incubator to add support for snapshots. The Katacoda tutorial will show how to use Stork with this simple YAML file to create a snapshot on demand:
apiVersion: volumesnapshot.external-storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: px-postgresql-snapshot
namespace: default
spec:
persistentVolumeClaimName: px-postgresql-pvc
To learn more about PostgreSQL snapshot schedules, please refer to our docs page. In the Katacoda tutorial, you will also learn how to start a new PostgreSQL instance from a snapshot for point-in-time recovery of your data.
Conclusion
As we've just seen, you can easily run an HA PostgreSQL container on Kubernetes using Portworx for replication, snapshots, backups, volume resizing, and even encryption. Depending on the size of the cluster, you can either forego PostgreSQL replication and use Portworx replication for HA, or use both PostgreSQL replication (for spreading out writes) and Portworx replication (for faster failover). For more information, explore our Katacoda tutorial for HA PostgreSQL on Kubernetes.
Published at DZone with permission of Michael Ferranti. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments