Producing Messages at Warp Speed: Best Practices for Optimizing Your Producers
This article provides insights into the best practices for optimizing your message producer for maximum message throughput.
Join the DZone community and get the full member experience.
Join For FreeMemphis.dev recently organized its first hackathon; participants were tasked with saving the island of Zakar by predicting wildfires from temperature sensor data and social media posts. To set up the hackathon, I simulated seven years of data, generating more than four million messages.
Each participant needed to load that data into their Memphis Cloud account, so I wrote an upload script using the Python SDK. When I tested the script on my home network, I was easily seeing ingestion rates of 11,000 messages per second. But when I tested it using my Memphis Cloud account, messages were only being produced at a rate of 30 messages per second. Oh no! What gives?! And how did I end up fixing it?
Lesson 1: Don’t Underestimate the Impact of Latency
My original version of the script had a loop like so:
for msg in messages:
await producer.produce(bytearray(msg, "utf-8"))
By default, the Memphis Python SDK produces messages synchronously. In other words, the SDK will send a message to the broker and pause the program while it waits for a reply or a specified timeout period.
Imagine that we have a two-lane highway connecting two cities, Pizza Land and Hungry People Village. Pizza delivery drivers use the highway to deliver pizzas from Pizza Land to customers in Hungry People Village. Unfortunately, Pizza Land only has one delivery driver, and that driver can only deliver to one customer per trip.
If the distance between the two cities is small, this isn’t a huge deal. Let’s assume that the round trip time is 0.1 ms or 10^-4 seconds. 10,000 (10^4) orders can be delivered in a total of 1 second.
But what if the distance is greater? Let’s assume that it takes 10 ms or 10^-2 seconds to complete the round trip for a single delivery. It would now take 100 seconds to deliver the same 10,000 orders.
Solution 1: Non-Blocking Message Production
The Memphis SDKs also support producing messages using non-blocking I/O. In this model, Pizza Land has multiple delivery drivers. Each order sits in the queue until the preceding orders have been delivered, but now multiple orders can be delivered in parallel. If there are five delivery drivers, then it takes RTT time to deliver orders 1 through 5. Order 6 will need to wait until the first delivery driver returns, so the delivery time is 2 * RTT. If there are C delivery drivers, then it takes N * RTT / C to deliver all N orders.

To enable non-blocking message production in the Python SDK, use the nonblocking=True flag:
for msg in messages:
await producer.produce(bytearray(msg, "utf-8"), nonblocking=True)By setting the nonblocking=True, the SDK will allow the client to keep sending messages even if the responses haven’t yet been received from previous messages. The Python SDK accomplishes this using the asyncio framework. A task that waits for a response is created for each message that is sent. While the task is waiting, the main thread of the program keeps running, allowing it to keep sending messages.
With nonblocking=True, we went from producing 30 messages per second to 22,000 messages per second. Wow!
Lesson 2: Saturating the Channel
On my Mac laptop and Linux desktop, the non-blocking approach worked perfectly; the entire set of messages could be uploaded to Memphis Cloud without any issues. When testing on Microsoft Windows and slower network connections, however, we noticed that replies were not being received before the tasks timed out. As a result, messages weren’t being delivered to the broker.
Let’s assume Pizza Land has a delivery guarantee – 30 minutes, or they cancel and refund your order. It turns out that the cars kept trying to merge onto the highway when it was full, causing a traffic jam. As a result, the RTT of each delivery goes up. Pizzas aren’t being delivered. Customers start complaining, and Pizza Land is losing money.
Solution 2: Use Rate Limiting
Pizza Land decides to implement a policy where they will temporarily stop taking new orders when there is traffic. Pizza Land waits until the traffic goes down before it resumes taking orders again. Although this may be a shady business practice, it prevents Pizza Land from missing its delivery windows.
Similarly, to avoid issues with timeouts, we implemented a rate-limiting approach in the Python SDK. Every time a task is created, it’s added to a set of current tasks. When a task is completed (reply is received), the task is removed from the set. If the set reaches a given maximum size, the Producer’s produce() method will block until the size of the set is reduced to half its maximum size. Effectively, when the number of tasks overflows, we wait for the tasks to drain before adding more.
for msg in messages:
await producer.produce(bytearray(msg, "utf-8"), nonblocking=True, concurrent_task_limit=1000)
A few of our participants still ran into timeouts with a limit of 1,000 concurrent tasks. Presumably, these users were even further away from the US East 1 or EU 1 regions that Memphis Cloud runs in than I am. We advised these users to reduce the limit to 500 or 250 tasks. By doing so, they were able to successfully upload all of the messages.

Non-blocking production of messages is supported in all of the official Memphis SDKs. Here are examples of how to do so for the other official SDKs:
In the Javascript SDK, the functionality can be enabled by passing the asyncProduce=true flag to the produce() method:
await producer.produce({
message: 'message',
asyncProduce: true
});
In the Go SDK:
p.Produce(
[]byte("abc"),
memphis.AsyncProduce()
)In the .Net SDK:
await producer.ProduceAsync(
message: Encoding.UTF8.GetBytes("abc")
);We are working to expand support. In the v1.2.0 release of the Python SDK, we deprecated the async_produce flag and introduced the nonblocking flag. The semantics are the same, but we wanted to clarify the semantics. We also introduced rate limiting to the Python SDK. Rate limiting will be added to other SDKs in future releases.
Lesson 3: Use More Than One Connection
In the current version of the SDKs, all producers and consumers created from the same Memphis object instance share a single connection. Even with non-blocking I/O and batching, we may not be able to fill the highway to capacity when using a single TCP/IP connection. Does using multiple connections help?
Solution 3: Multiple Processes (or Threads) = Multiple Connections
I decided to test this out by running a benchmark. In five-minute intervals, I measured how many messages were received by a broker as we varied the number of producers. The broker was running in Memphis Cloud, while the producers were running from a home machine. The producers were implemented using the Python SDK and configured to use non-blocking I/O with a limit of 500 concurrent tasks. The message payloads were 512 bytes in size (~660 bytes with headers and other metadata).
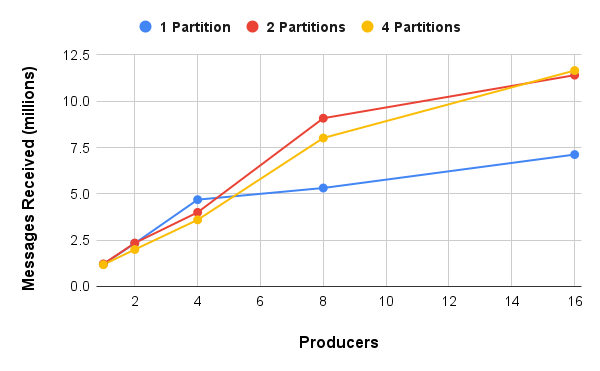
The number of messages produced scaled linearly when going from 1 to 4 producers (each running as a separate Python process). A win! If your application can be designed to use multiple producers, you absolutely should.
Lesson 4: Embrace Partitions
Until recently, each Memphis station was served by a single queue. This came with some overhead, which limits the rate of parallel production of messages. Specifically, the broker employs locks to ensure that messages are queued in the order of arrival and safe storage of messages on disk.
Solution 4: Configure Your Station With Multiple Partitions
Memphis recently introduced partitions. In short, rather than storing a station’s messages in a single queue, the messages are spread across multiple independent queues. We see the impact of scaling in the previous graph. Going from 1 to 2 partitions was the secret to achieving linear scaling up to 8 producers. We see less of an impact when going from 2 to 4 partitions, but that’s because the latencies from the locking mechanisms are relatively small compared with latencies over the network.
We’re not resting on our laurels. Our engineers are hard at work to continually improve the performance of Memphis and our SDKs. In the most recent release (v1.3.0) of Memphis, we introduced keys for determining the assignment of messages to partitions. With this and other upcoming changes, we can create 1:1 relationships between producers and partitions, unlocking further improvements in scalability. Similarly, we’ll be benchmarking and developing best practices for maximizing message consumption rates. Stay tuned!
Published at DZone with permission of RJ Nowling. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments