Product Catalog with MongoDB, Part 2: Product Search
Continue learning about product catalogs in MongoDB as we look at product seraches.
Join the DZone community and get the full member experience.
Join For FreeThis post is a follow up to my 1st post on Product Catalog Schema Design for MongoDB. Now that we have established a strong basis for our product catalog, we are ready to dive into one the most important feature: Product Search.
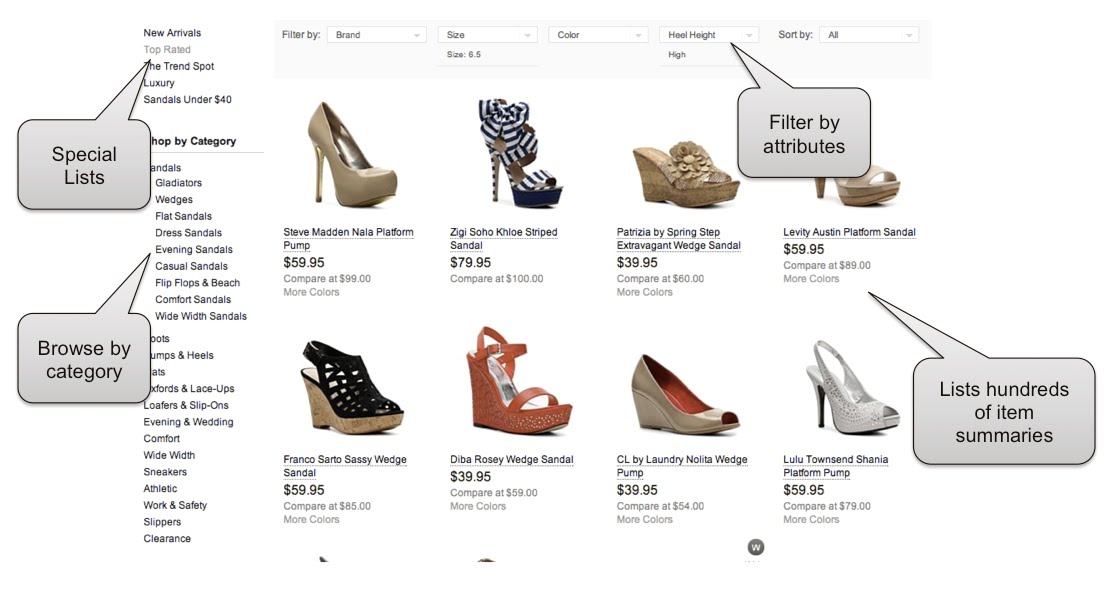
This feature presents many challenges:
- Response within milliseconds for hundreds of items
- Faceted search on many attributes: category, brand, …
- Efficient sorting on several attributes: price, rating
- Pagination feature which requires deterministic ordering
Fortunately those challenges are not new, and software like Search Engines are built exactly for this purpose. In the following sections we will see how to use Search Engines with MongoDB, which one is best, and whether we can leverage MongoDB’s indexing itself.
Overall Architecture
The diagram below illustrates the traditional architecture:
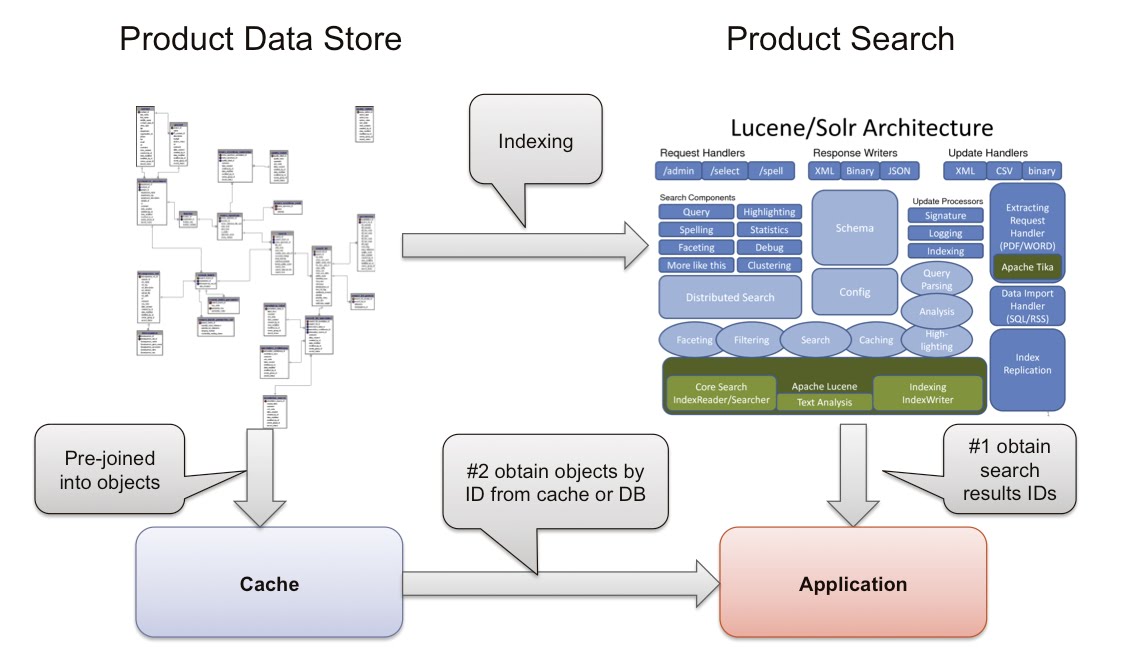
It presents the following limitations:
- 3 different systems to maintain: RDBMS, Search engine, Caching layer
- RDBMS schema is complex and static
- Applications needs to talk many languages
The new architecture with MongoDB looks like this:
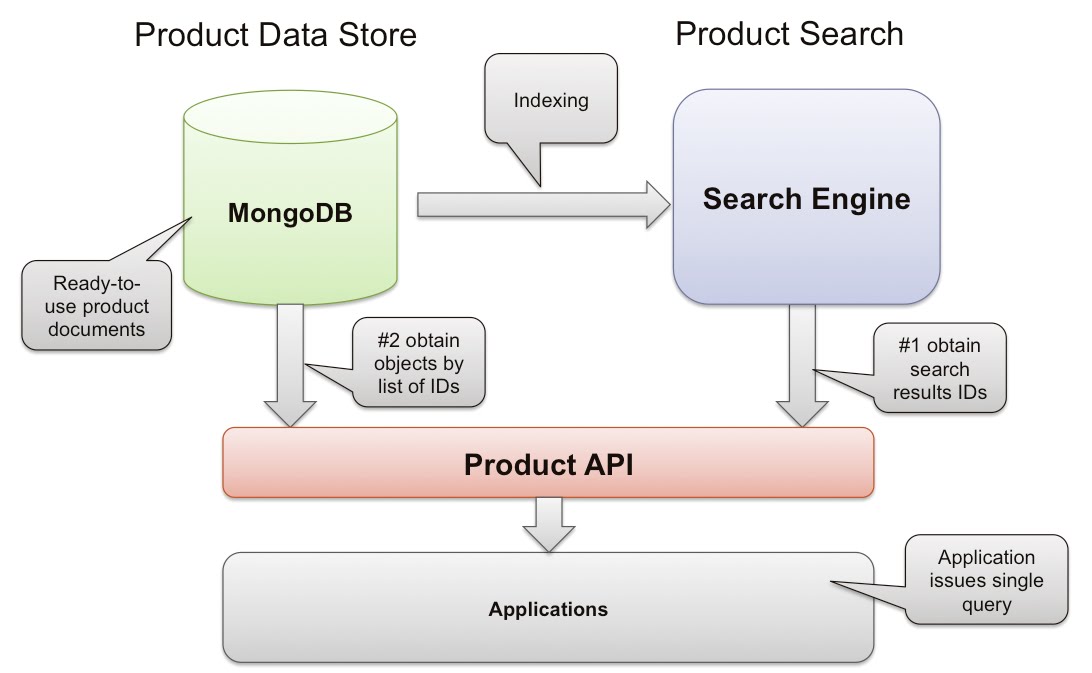
A few things are improved:
- With the API layer, the application just issues a single call, thus reducing complexity and latency
- No need for a caching layer since MongoDB’s read performance is close to Memcache and the likes
- The schema is dynamic and maps well to the API calls
Now on to the indexing part: how can the data from MongoDB be indexed into a Search Engine? There are many different ways to do this, but one easy option is to use Mongo-Connector.
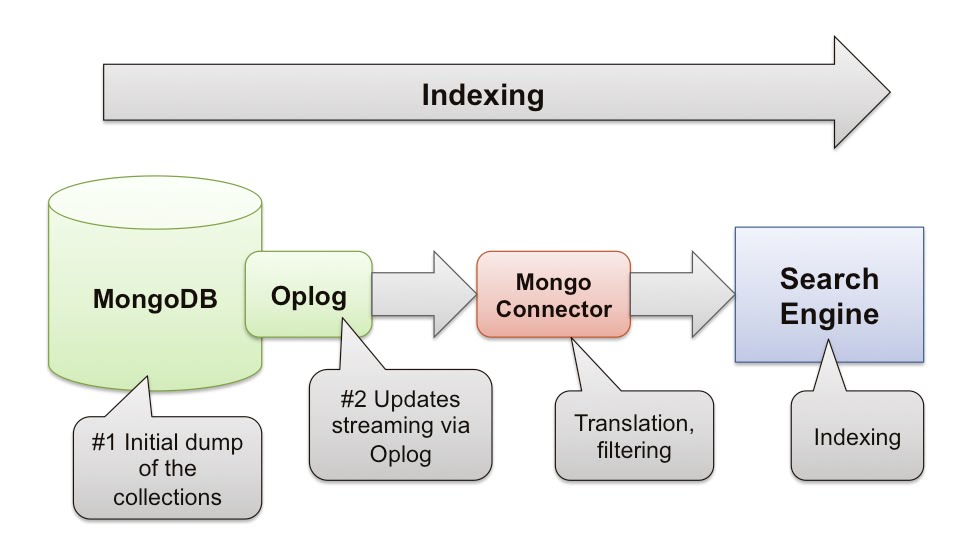
What is the Mongo-Connector?
- Open-source Project at https://github.com/10gen-labs/mongo-connector
- Python app that reads from MongoDB’s oplog and publishes the updates to a target of choice
- Supports initial sync by dumping the collections
- Default connectors for Solr, Elastic Search, or other MongoDB cluster
- Easily extensible to update other systems like SQL
So here we are, we have the connector installed on our Search Engine server, ready to start indexing from MongoDB. Wait, which data are we supposed to index?
The Source Data
In the first post Product Catalog Schema Design, we devised models that are quite normalized. The goal was to make it more natural for queries and updates while avoiding the mega-document syndrome. But now, we are faced with searches that look like this:
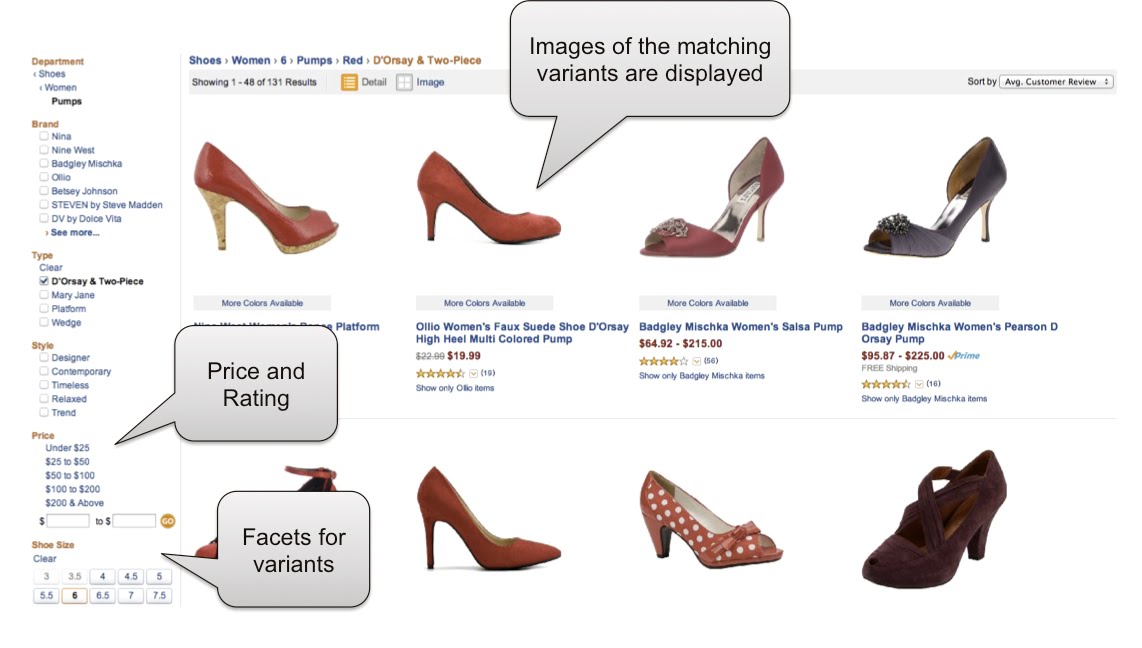
Thus more challenges appear:
- Attributes at the variant level: color, size, etc
- Attributes from other docs: pricing, ratings, etc
- Display the matching variant’s image and details (e.g. red version of shoe)
- Dozens of matching variants for an item, still need to display a single item (Deduplication of results)
- Challenge to properly index the fields in Search Engines
This calls for a single document per item which would contain all necessary information, but omiting all fields that are not needed for browsing and searching. We will call this an Item Summary and use the following model:
{ "_id": "3ZZVA46759401P", // the item id
"name": "Women's Chic - Black Velvet Suede",
"dep": "84700", // useful as standalone for indexing
"cat": "/84700/80009/1282094266/1200003270",
"desc": { "lang": "en", "val": "This pointy toe slingback ..." },
"img": { "width": 450, "height": 330, "src": "http://..." },
"attrs": [ // global attributes, easily indexable by SE
"heel height=mid (1-3/4 to 2-1/4 in.)",
"brand=metaphor",
"shoe size=6",
"shoe size=6.5", ...
],
"sattrs": [ // global attributes, not to be indexed
"upper material=synthetic",
"toe=open toe", ...
],
"vars": [
{ "id": "05497884001",
"img": [ // images],
"attrs": [ // list of variant attributes to index ]
"sattrs": [ // list of variant attributes not to index ] }, …
] }
Those documents can be updated as often as needed by a background process using custom code. The updates will make their way to MongoDB’s oplog, and we can tap into it using the Mongo-Connector.
Using Solr
After successful setup, your Solr install may looks like this:
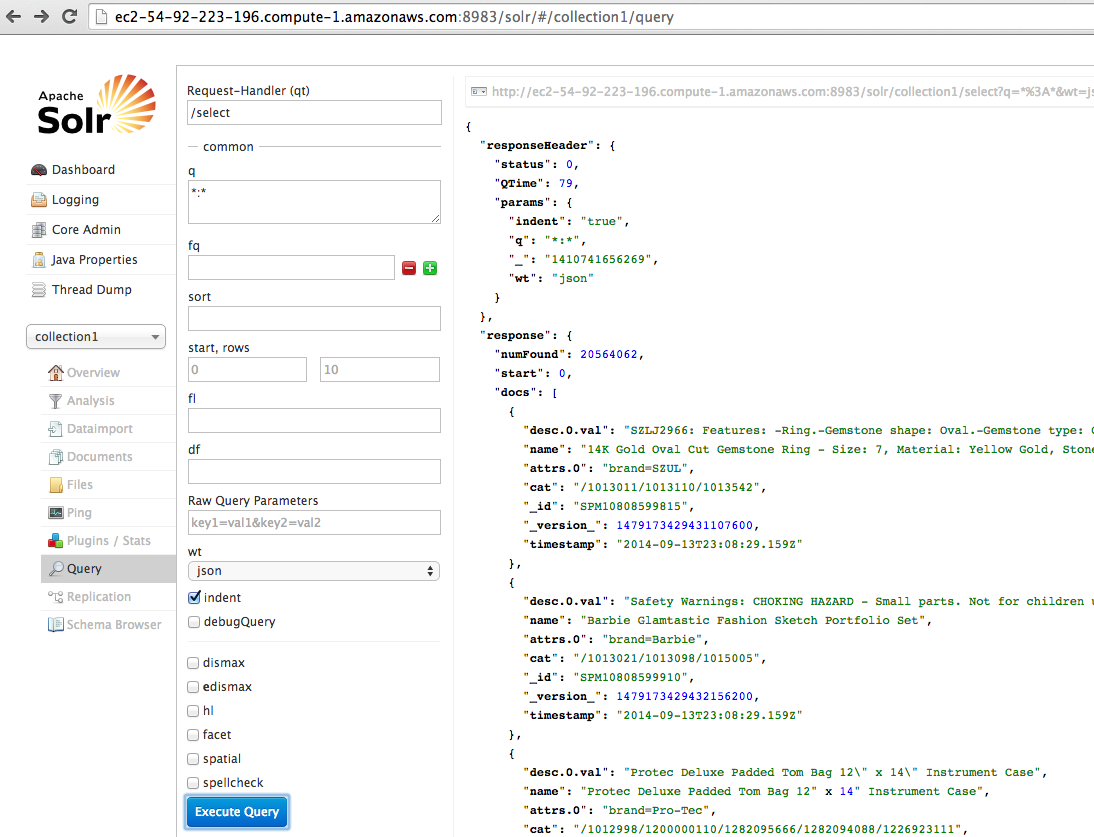
The first and most difficult step with Solr is to define the proper indexing schema in schema.xml. Based on our model, such a definition may look like:
<fields>
<!-- some of the core fields -->
<field name="_id" type="string" indexed="true" stored="true" />
<field name="name" type="text_general" indexed="true" stored="true" />
<field name="cat" type="string" indexed="true" stored="true" />
<field name="price" type="float" indexed="true" stored="true"/>
<!-- the full text to index -->
<field name="desc.0.val" type="text_general" indexed="true" stored="true"/>
<!-- dynamic attributes for faceting -->
<dynamicField name="attrs.*" type="string" indexed="true" stored="true"/>
<!-- some Solr specific fields -->
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="timestamp" type="date" indexed="true" stored="true" default="NOW" multiValued="false"/>
<!-- ignore all other -->
<dynamicField name="*" type="ignored" multiValued="true"/>
</fields>
Now we are ready to start up the connector, using the single command line:
> mongo-connector
-m ec2-54-80-63-229.compute-1.amazonaws.com:27017 // the mongo
-t http://localhost:8983/solr // the solr
-d mongo_connector/doc_managers/solr_doc_manager.py
-n "catalog.summary" // target summary collection
--auto-commit-interval=60 // commit every 1 min
…
The connector will first dump the summary collection, indexing all documents. When done, it will continue processing anything coming to the Oplog. Looking at the Solr interface, a document looks like:
{ "desc.0.val": "Our classic \"Flying Duck\" styled as a ...",
"name": "Drake Waterfowl Duck Label SS T-Shirt Army Green",
"attrs.1": "brand=Drake Waterfowl",
"attrs.0": "style=t-shirts",
"cat": "/84700/1200000239/1282094207/1200000817",
"_id": "SPM10823491916",
"_version_": 1479173524477182000,
"timestamp": "2014-09-13T23:09:59.782Z"
}
The exercise reveals several serious limitations:
- The wildcard to match dynamic fields can only appear at beginning or end. As a result we can’t match fields like “desc.*.val”
- Wildcard characters cannot be used with faceting. One would have to specify “attrs.0”, “attrs.1”, etc. Even then, facets are computed independently
- Basically JSON lists get flattened and that makes it very difficult to use. The only workaround is to somehow make use of named fields instead e.g. “attr_color”, “attr_size”.
- Mongo-Connector uses pySolr to convert MongoDB’s document to XML usable by Solr and it turns out to be quite slow (about 200 docs / s)
Using Elastic Search
After successful setup, your Elastic Search install may looks like this:
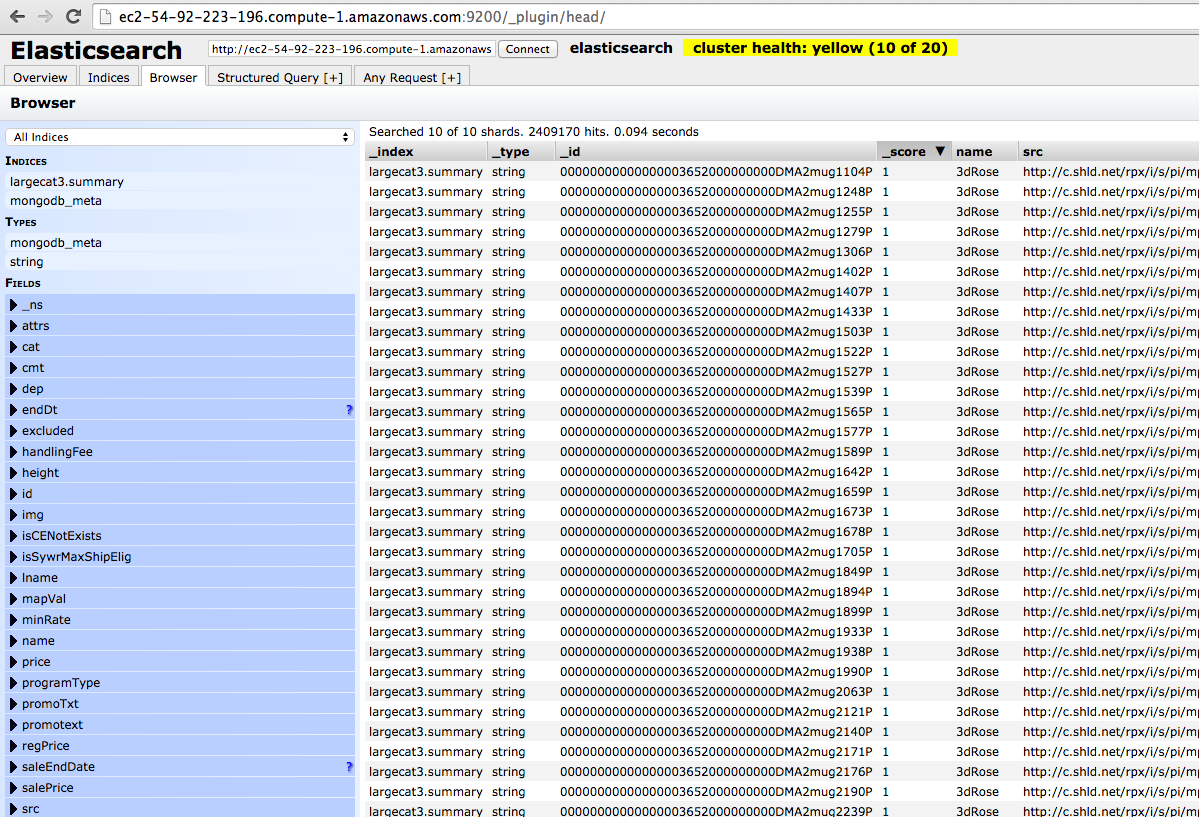
The nice thing about ES is that it conveniently understands the whole JSON document from MongoDB right off the bat :) The only change to indexing we have to do is to tell ES not to tokenize the facets. This can easily be done by submitting a new type mapping:
$ curl -XPOST localhost:9200/largecat3.summary -d '{
"settings" : {
"number_of_shards" : 1
},
"mappings" : {
"string" : { // string is the name of default mapping type
"properties" : {
"attrs" : { "type" : "string", "index" : "not_analyzed" }
}
} } }'
Everything else will get indexed auto-magically! Now we are ready to start up the connector, using the single command line:
> mongo-connector
-m ec2-54-80-63-229.compute-1.amazonaws.com:27017 // the mongo
-t http://localhost:9200 // the ES
-d mongo_connector/doc_managers/elastic_doc_manager.py
-n "catalog.summary" // target summary collection
--auto-commit-interval=60 // commit every 1 min
…
At this point we can go to ES’s interface (Head plugin) or query through the command line:
$ curl -X POST "http://localhost:9200/largecat3.summary/_search?pretty=true" -d '
{ "query" : { "query_string" : {"query" : "Ipad"} },
"facets" : { "tags" : { "terms" : {"field" : "attrs"} } } }'
{ "took" : 6,
"hits" : {
"total" : 151,
"max_score" : 0.5892989,
"hits" : [ {
"_index" : "largecat3.summary",
"_type" : "string",
"_id" : "000000000000000012730000000000QAU-QR2442P",
"_score" : 0.5892989,
"_source": { // original JSON from MongoDB }, ... ]
},
"facets" : {
"tags" : {
"_type" : "terms",
"total" : 1577,
"terms" : [ { "term" : "ring size=9", "count" : 120 },
{ "term" : "ring size=8", "count" : 120 },
{ "term" : "metal=sterling silver", "count" : 112 }, ... ]
} } }
Elastic Search gives us what we need:
- Facetting works as expected on the “attrs” list
- We have full text search on all elements of the “desc” list.
- Result includes MongoDB’s original document
- Query Results are automatically cached for faster future retrieval
- Mongo-Connector is much faster with ES (about 1000 docs / s)
Using MongoDB’s Indexing
One might wonder, how about not using a Search Engine at all? Doesn’t MongoDB have a full text search? Could we build faceted search too? The FTS of MongoDB is still a fairly new feature and has a number of limitations since it is purely based on a regular BTree:
- It slows down writes quite significantly (each word is an index entry)
- Index ends up being very large (no de-duplication of terms)
- Only supports latin languages
- No automatic caching of results
Now that we know the limitations, is it of any use? Well beyond the limitations, it actually does the job pretty well especially for smaller catalogs (in the GBs). We can create the following FTS index:
> db.createIndex({ "desc.val": "text", "name": "text" },
{ weights: { "desc.val": 1, "name": 5 } })
Then we can query it using the “$text” operator which is integrated into the main query syntax:
> db.summary.find({$text: {$search: "Ipad"}})
This returns fast but the results are in random order, which is not ideal. You can get the results sorted by matching score instead:
> db.summary.find({$text: {$search: "5"}}, {score: {$meta: "textScore" }})
.sort({score: {$meta: "textScore" }}).limit(50)
Note here that “limit()” is needed to avoid blowing up the RAM usage during sorting, which would make it abort. One of the limitation here is that since there is no query cache, querying for a very common word (other than stop words) will yield many results to sort for every call.
Now on to faceting, which can be tackled using a compound index. Here we will discuss faceting as a search feature rather than a count of facets. The following fields are of interest:
- department e.g. “Shoes”
- Category path, e.g. “Shoes/Women/Pumps”
- Price
- List of Item Attributes e.g. “Brand=Guess”, which includes Variant Attributes e.g. “Color=red”
- List of Item Secondary Attributes e.g. “Style=Designer”, which includes Variant Secondary Attributes, e.g. “heel height=4.0”. Those fields do not need to be indexed.
When thinking of a typical faceted query, it should include a department, a category, a price range, and a list of attributes:
db.summary.find( { dep: "84700" ,
"vars.attrs": { $all: [ "Color=Gray", "Size=10" ],
"cat": ^/84700\/80009\/1282094266/ ,
"price": { "$gte" : 65.99 , "$lte" : 180.99 } } )
What kind of indices do we need for this query? Ideally they should start with the department, which can be a left equality that must be specified (i.e. user won’t see facets until they pick a department). Then they should probably end with _id in order to allow faster deterministic ordering (useful for pagination). Beyond that, we need a mix of the fields so that MongoDB can always use an index that quickly narrow down results. For our purpose we will define the following indices:
- department + attrs + category + price + _id
- department + category + price + _id
- department + price + _id
The goal is not to have an absolute perfect coverage of all possibilities, since it would result in too many indices. But the indices above will make sure that MongoDB narrows down the documents to a short list in most cases. Now another question is for the “$all” operator, which attribute property is actually used to locate the index branch? Using “explain()” quickly reveals that the 1st item in the $all list is the most significant one:
> db.foo.find({ attrs: {$all: ["a", "b"]} }).explain()
{
"cursor" : "BtreeCursor attrs_1",
"isMultiKey" : true,
...
"millis" : 3,
"indexBounds" : {
"attrs" : [
[
"a",
"a"
]
]
},
"server" : "agmac.local:27017",
"filterSet" : false
}
MongoDB has no idea which value is more restrictive and it just assumes the 1st one will be good enough. Consequently the query is much faster if the 1st item in the $all list is the most restrictive one - all others will just be matched during index scan. Using static facet information from the catalog, the application can thus speed up the query by placing the facet value with the lowest number of items first:
{ "_id" : "Accessory Type=Hosiery" , "count" : 14}
{ "_id" : "Ladder Material=Steel" , "count" : 2}
{ "_id" : "Gold Karat=14k" , "count" : 10138}
{ "_id" : "Stone Color=Clear" , "count" : 1648}
{ "_id" : "Metal=White gold" , "count" : 10852}
In this case the “Ladder Material=Steel” should come first in the query.
Closing Comments
In conclusion, we’ve devised an ideal Product Search architecture and established a good source of data to be indexed. Then we compared different solutions for full-text searching and faceting, with the following outcome…
Search Engine advantages:
- Index size (~ 10x smaller than MongoDB’s)
- Indexing speed
- Query speed, integrated cache for complex queries
- All languages support
- Built-in faceted search, which includes facet counts
MongoDB’s Indexing advantages:
- Built-in the data store, no additional server / software needed
- Single query to get the results
- Facetting without text search can be faster when using the proper $all combination
In the current state, the winning combination for Product Search is Elastic Search, combined with MongoDB as Data Store! The MongoDB FTS will hopefully get better and better to cover larger use cases, but it will need other index structures than BTree to get close to Lucene-based search engines.
Published at DZone with permission of Antoine Girbal. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments