Why Every Defense Against Prompt Injection Gets Broken — And What to Build Instead
Twelve LLM prompt injection defenses were tested, and all bypassed. Stop relying on perimeter filters. Strip model privileges and design for containment instead.
Join the DZone community and get the full member experience.
Join For FreeI watched a senior engineer spend two weeks hardening their LLM-powered claims assistant against prompt injection. Input sanitization. A blocklist with 400+ attack patterns. A classifier model running in front of the main LLM. Rate limiting. He was thorough. Proud, even. And on day one of the penetration test, the red team got through in eleven minutes using a base64-encoded payload nested inside a PDF attachment.
I've seen this scene play out more than once. Teams treat prompt injection like a classic injection vulnerability — filter the inputs, escape the dangerous characters, done. That mental model is wrong. And building on a wrong mental model is how you end up with false confidence that's arguably worse than having no security at all.
The Research Nobody Wants to Talk About
In late 2025, a joint research team from OpenAI, Anthropic, and Google DeepMind published a paper that should have sent shockwaves through the industry. They tested twelve of the most widely cited published defenses against prompt injection and jailbreaking. Not toy implementations — actual production-grade techniques teams are deploying right now.
Every single one was bypassed. Most have success rates above 90%. The paper's title says it plainly: "The Attacker Moves Second."
Think about what that means architecturally. Every defense you build is a fixed rule or a trained pattern. An attacker who encounters that defense has infinite time and infinite prompting attempts to probe around it. You ship once. They iterate continuously. This isn't a fair fight, and pretending otherwise is how security theater gets born — the kind that passes code review but fails at 2 a.m. on a Tuesday.
"The goal is not to prevent prompt injection. That bar is too high. The goal is to make a successful injection structurally irrelevant."
This isn't pessimism — it's a design constraint, the same way we think about SQL injection. We don't rely solely on input validation to prevent SQL injection in mature systems. We use parameterized queries, ORMs, connection pool scoping, and database-level user permissions. The sanitization still exists, but it's not load-bearing. Prompt injection needs that exact same architectural rethinking.
Why Defenses Fail: A Taxonomy
Before you can design around failure modes, you need to understand why each defense class breaks down in practice.
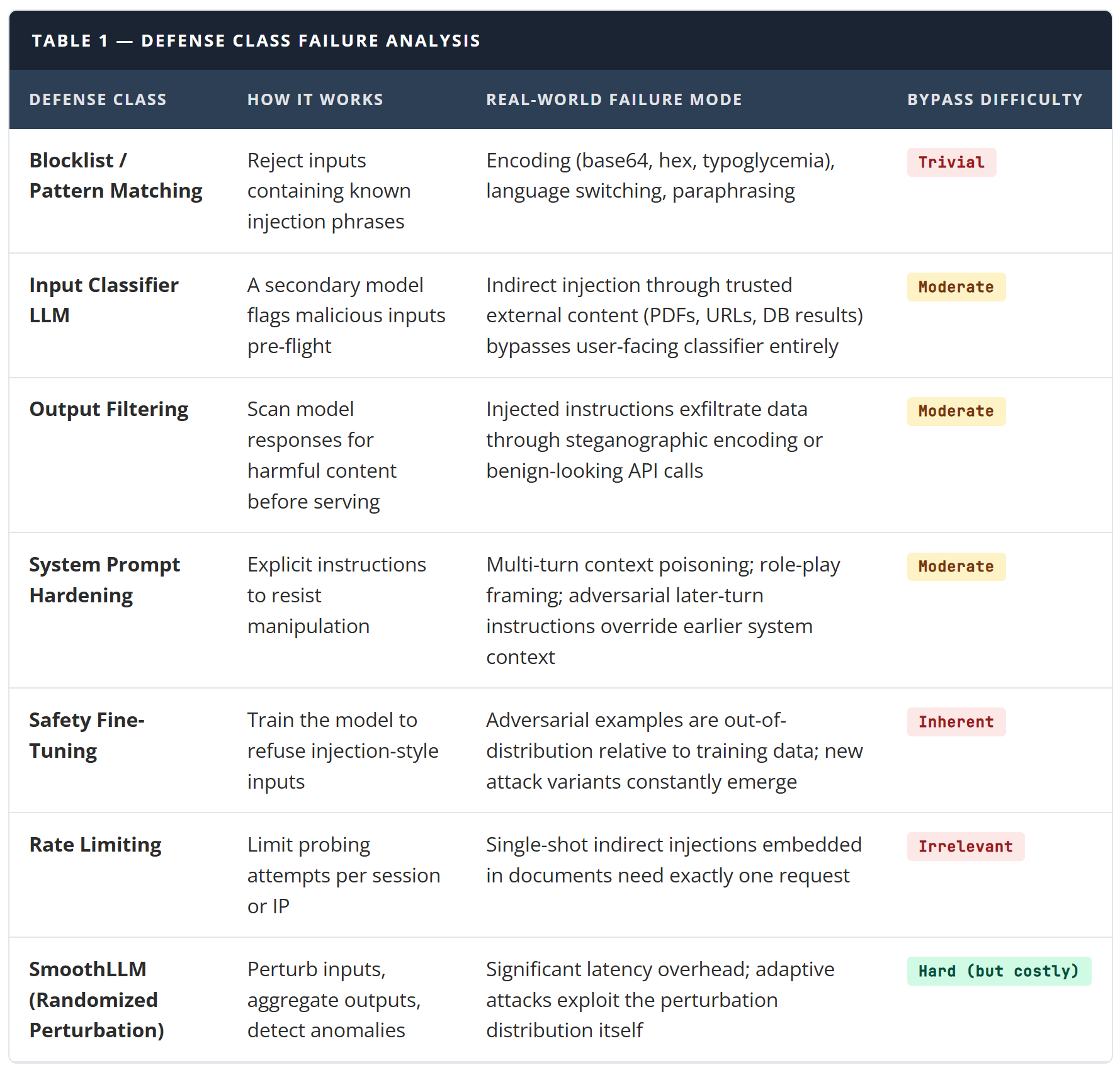
The pattern is consistent. Every defense that focuses on detecting or blocking injection at the perimeter gets defeated by attackers who simply shift their vector. You close the front door; they come through the PDF processor. You add a classifier; they inject through the RAG knowledge base. You harden the system prompt; they poison the context over multiple turns.
The root cause isn't poor implementation. It's that current LLM architecture fundamentally blurs the line between instructions and data. Everything is tokens. The model cannot inherently distinguish "this is a command I should follow" from "this is document content I should summarize." Until that distinction exists at the architectural level — not the prompt level — injection remains structurally possible.
Designing for When It Succeeds
Here's the question that doesn't get asked loudly enough: what happens in your system after a prompt injection succeeds?
If the answer is "the model generates a harmful response," that's a problem addressable at the output layer. If the answer is "the model calls a payment API with attacker-controlled parameters," you have a completely different threat profile. That's a privilege and authorization problem. The injection just exploited it.
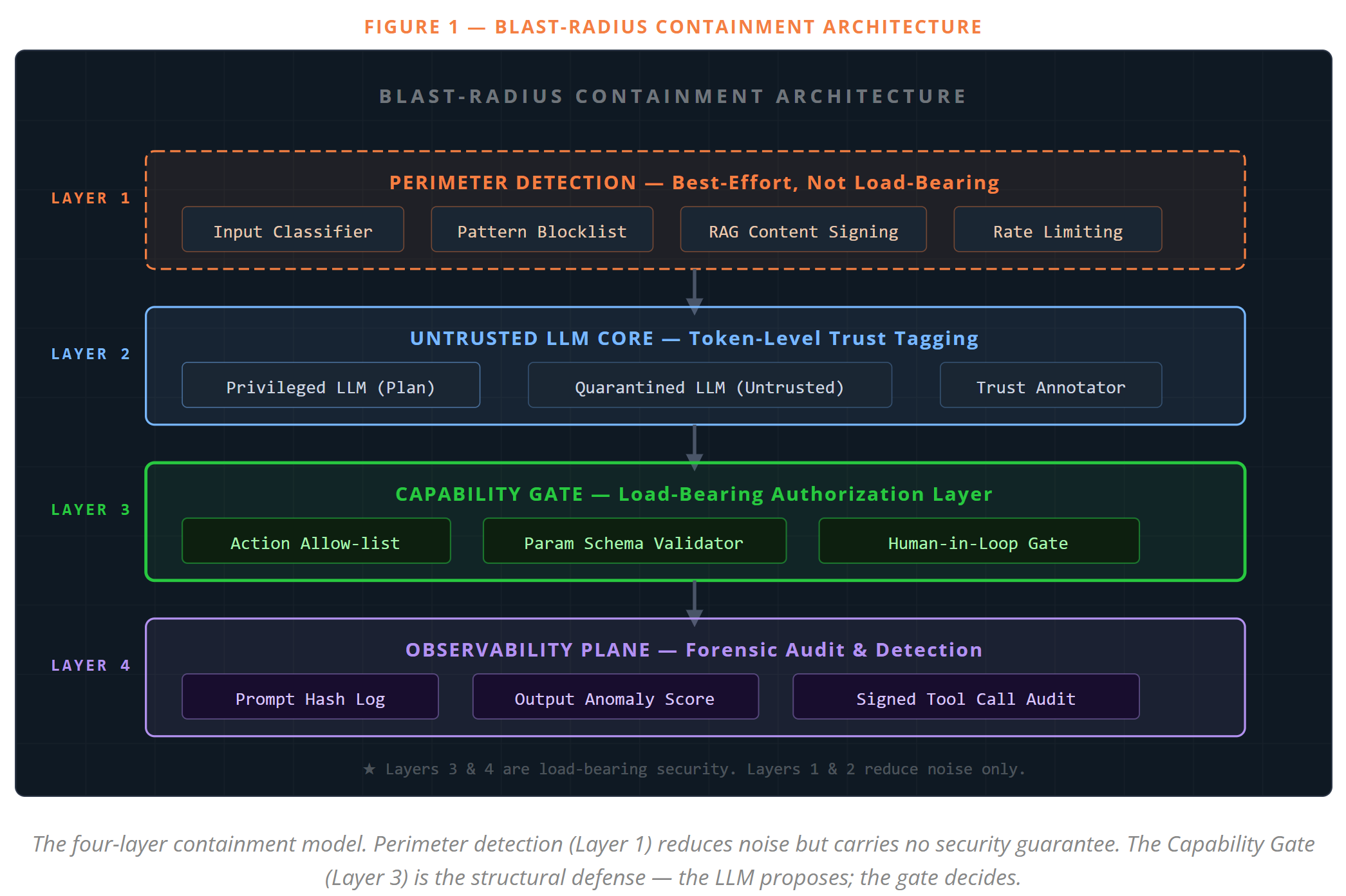
Building the Capability Gate
Layer 3 Is Load-Bearing — Build It Like It
The single most impactful structural change you can make: the LLM should never be the authorization authority for what it can do. The model decides what it wants to do. A separate, hardened capability gate decides whether it's allowed.
This is the core of Google DeepMind's CaMeL framework. The LLM plans. A privileged external executor validates each planned action against a strict allow-list before running it. If the model was injected and now "wants" to exfiltrate data to an external URL, the capability gate says no — because exfiltrating to external URLs was never on the allow-list, regardless of what the model was told mid-session.
# Capability gate — the LLM proposes tool calls; this gate executes them.
# Policy is loaded from config at startup — never derived from LLM output.
from dataclasses import dataclass
from typing import Any, Callable
import jsonschema, hashlib, time, logging
@dataclass
class ToolCall:
name: str
params: dict[str, Any]
session_id: str
class CapabilityGate:
def __init__(self, policy: dict):
self.policy = policy # set at startup by engineers, not by the LLM
self.audit_log = []
def execute(self, call: ToolCall) -> Any:
# Step 1 — Is this tool in the allow-list at all?
if call.name not in self.policy["allowed_tools"]:
self._audit(call, "BLOCKED_UNKNOWN_TOOL")
raise PermissionError(f"Tool '{call.name}' not in capability allow-list")
tool_policy = self.policy["allowed_tools"][call.name]
# Step 2 — Do params match the declared schema exactly?
try:
jsonschema.validate(call.params, tool_policy["param_schema"])
except jsonschema.ValidationError as e:
self._audit(call, "BLOCKED_SCHEMA_VIOLATION", str(e))
raise
# Step 3 — Privileged operations require human approval
if tool_policy.get("requires_human_approval"):
self._audit(call, "PENDING_HUMAN_REVIEW")
return self._request_human_approval(call)
# Passed all gates — log and execute
self._audit(call, "EXECUTED")
handler: Callable = tool_policy["handler"]
return handler(**call.params)
def _audit(self, call: ToolCall, outcome: str, detail: str = ""):
entry = {
"ts": time.time(),
"session": call.session_id,
"tool": call.name,
"params_hash": hashlib.sha256(str(call.params).encode()).hexdigest()[:16],
"outcome": outcome,
}
self.audit_log.append(entry)
logging.info("[GATE] %s | %s | session=%s", call.name, outcome, call.session_id)Key thing to note: line 9 — the policy is loaded from config at startup. An injected model cannot rewrite its own allow-list. No matter what it was told to do, the gate only knows the tools registered by engineers at deploy time.
The Quarantined LLM for External Content
Indirect injection — malicious instructions arriving inside processed documents, emails, or web pages — is the variant most teams are under-defending. The fix isn't a better filter. It's an architectural separation.
Run a second, quarantined LLM instance for all external content. This model has no memory, zero tool access, and no ability to pass instructions into the primary model's context. It extracts facts. It summarizes. It cannot issue commands. The primary model receives only the quarantined model's structured output — never the raw document text.

Signed Audit Trails on Every Tool Call
Detection isn't prevention. But the difference between catching an incident after 41 days and catching it after 4 hours is entirely a detection problem. Every tool call the LLM proposes — executed or blocked — should be logged with a cryptographic hash of the input prompt and proposed parameters. When an injection succeeds, the audit trail tells you exactly what the model was instructed to do and when.
Implementation note:
Store tool-call audit logs in an append-only store that the LLM has no write access to. If the model is injected and the attacker tries to cover tracks, the log store needs to be structurally out of reach — not just policy-protected. Use a dedicated service with no LLM-accessible write endpoint, and sign entries with an HMAC key the model cannot observe.
The Priority Stack: What to Build First
Most teams can't implement all of this at once. If you're triaging, here's the honest priority order based on actual blast-radius impact:
- Audit and shrink LLM tool access — today. List every API and tool your LLM can invoke. Ask: Does the core use case actually require this? Payment writes, external HTTP calls, and database mutation — all need hard justification. Remove anything unnecessary. Blast radius reduction starts here, before you write a single line of security code.
- Parameter schema validation at the gate. Before any proposed tool call executes, validate every parameter against a strict JSON schema. An injected model trying to send data to
https://attacker.comgets blocked because the URL field only accepts your internal domain pattern — no matter how convincingly the model was instructed otherwise. - Quarantine all external document processing. Any content arriving from outside your trust boundary — user uploads, web fetches, email bodies, webhook payloads — passes through a sandboxed extraction layer before the primary model sees it. The primary model gets structured facts. Never raw text from untrusted sources.
- Signed, append-only audit logging. The forensic cost of not having this, when something goes wrong, dwarfs the engineering cost of building it. Ship this in the same sprint as the gate.
- Add perimeter detection on top. At this point, input classifiers and pattern blocklists are legitimate noise reduction. They lower the volume of attacks reaching your load-bearing defenses. They just aren't the defenses themselves anymore.
Where This Leaves Us
The uncomfortable truth that benchmark paper surfaces is something the security community knows well from other domains: you cannot secure a fundamentally porous boundary through inspection alone. You have to redesign around the assumption of compromise.
SQL injection was "solved" not because databases got better at detecting malicious strings, but because parameterized queries made the injection structurally irrelevant — the database engine stopped treating user input as code. Prompt injection will follow the same arc. Native token-level trust tagging, separate attention pathways for trusted versus untrusted content, architectural separation of instruction processing from data processing — this is where the real fixes lie. Some of that work is happening in research labs right now, including at the same organizations that published the benchmark study.
Until it ships at the model level, the only responsible posture is to assume injection will occasionally succeed, and engineer for containment. Your LLM is not a trusted actor in your system. Build accordingly.
The engineer at that insurance company wasn't wrong to build his perimeter defenses. He was wrong to stop there.
Opinions expressed by DZone contributors are their own.
Comments