Protecting Multi-Tenant RabbitMQ Instances From Queue Backlogs
Let's take a look at how to protect multi-tenant RabbitMQ instances from queue backlogs and also explore the topology.
Join the DZone community and get the full member experience.
Join For FreeWe use tools like event brokers (like Apache Kafka) and message brokers (like RabbitMQ) in our microservice architectures to share data between multiple microservices. If we are following patterns like event sourcing, command sourcing, and asynchronous communication, these messaging tools become more critical components of our architectures.
Some of these tools should be treated as shared infrastructure components that are utilized by multiple microservices. The reasons vary, but the first one is the complexity of the tool/technology that will be deployed.
Some tools are heavy-weight by nature and may not be feasible to be installed within an individual microservice's topology and this applies not only to brokers. Data sources like NoSQL (like Cassandra), or RDBMSs (like Oracle) can fall into this category. These tools may require dedicated optimization, special hardware, special licensing schemes, or may not get along with microservice’s execution environment (like containers). The complexity of the technology itself can also require specific engineering skills that may not exist in all scrum teams.
Shared infrastructure components may also bring cost savings in most cases. (You don't typically auto-scale these components - spinning-up new ones or killing the unnecessary ones due to load conditions)
Hey, we won’t give up our microservice principles. We still need to segregate the "data" of the microservice and we do this by applying logical partitioning to these tools. We will create dedicated Cassandra datasets, RDBMS databases, Kafka topics, RabbitMQ queues for these micro-services and eliminate coupling.
However, we still share the hardware/software infrastructure. The environment is shared, multi-tenant and it should provide fair-usage to its tenants. If one microservice is abusing its message queue/topic, due to a legit traffic spike or a buggy code, this may affect other microservices performance living on the same cluster.
Some tools will give you options to limit tenant behavior via different mechanisms. On Kafka, for instance, we can apply quotas to users/client IDs to enforce a maximum publisher/consumer throughput. On others which don't provide this functionality, we can implement some workarounds.
In this article, I will touch on a strategy that we can apply to protect our RabbitMQ broker.
RabbitMQ provides 2 mechanisms to apply segregation. Virtual hosts and queues. A virtual host can be created per microservice which will hold all the logical infrastructure definitions like Queues, Exchanges, users etc. This is a good practice as this allows the teams to manage their own AMQP topologies. However, this does not stop a virtual host to demand more from the underlying physical RabbitMQ instance.
Under load, RabbitMQ will start to choke first on memory. The default behavior is to keep the queue messages in the memory (even for persistent messages). This is for performance purposes and allows Rabbit to respond to consumers more quickly. The more un-ACKed messages in the queues, the more memory Rabbit will consume.
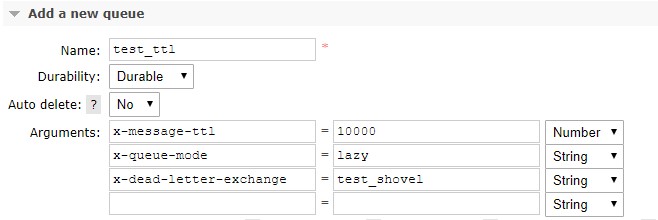
Rabbit introduced the queue parameter "lazy" to cancel this behavior and skip the memory. In lazy mode, the messages are directly written to disk. This is especially useful for queues that will hold messages for longer times, like staging queues. However, this will obviously affect the consumption rate.
When the total memory reaches to a preconfigured percentage of the total machine memory, Rabbit will start paging to disk to free up memory and in the meantime, it will start applying backpressure to protect itself from the demanding publishers. Unfortunately, it does this by rejecting the publishers and it is not a "slow down" mechanism. This means that the publisher should implement retries as soon as it starts getting rejects from the broker. If the publisher code is a legacy that you don’t want to touch, a 3rd party component, or simply you want leaner publishers, that may not be your preferred scenario.
During this stop-the-world kind of situation, all the publishers (regardless of their maturity) will go to a halted state and we don't want this to happen. This steers us to focus at the contention point: Queue.
The best practice in dealing with Rabbit queues is to keep the queue empty at all times. Queue backlogs can happen only in one situation: when publishers publish faster than the consumption rate.
We can mitigate this by auto-scaling our consumer fleet by watching the queue metrics (Unacknowledged message count). However, if auto-scaling is not available and we are dealing with an unexpected peak load, we can start seeing the backlogs. Rare situations like catastrophic failures can also occur on the consumer side which causes message pileups.
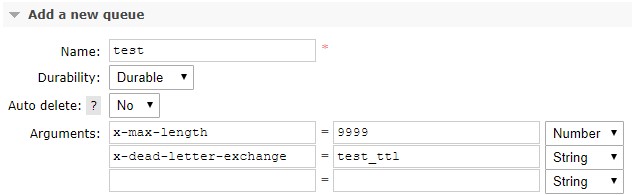
We need to put some governance around our queues that are owned by different applications/ different teams. The technical enforcement of this can be done via a basic queue configuration parameter: Maximum Queue Length.
The governance process is simple: before creating the queues, it will be mandatory to set this parameter which ensures there will be at most Maximum Queue Length messages on the queue at a given time. (The application should estimate the maximum number of publishes in a peak time that can be backlogged in the queue and a baselining study is beneficial)
The queue will then be created with this parameter. But what happens if you publish more?
This is called “overflow” in Rabbit terms and the default overflow behavior is to drop the messages from the head of the queue to make room for new messages. For some use-cases, we can live with this but for some others, we may be required to keep all messages.
To tackle these situations, we need to be creative with some AMQP components.
The topology is depicted below:
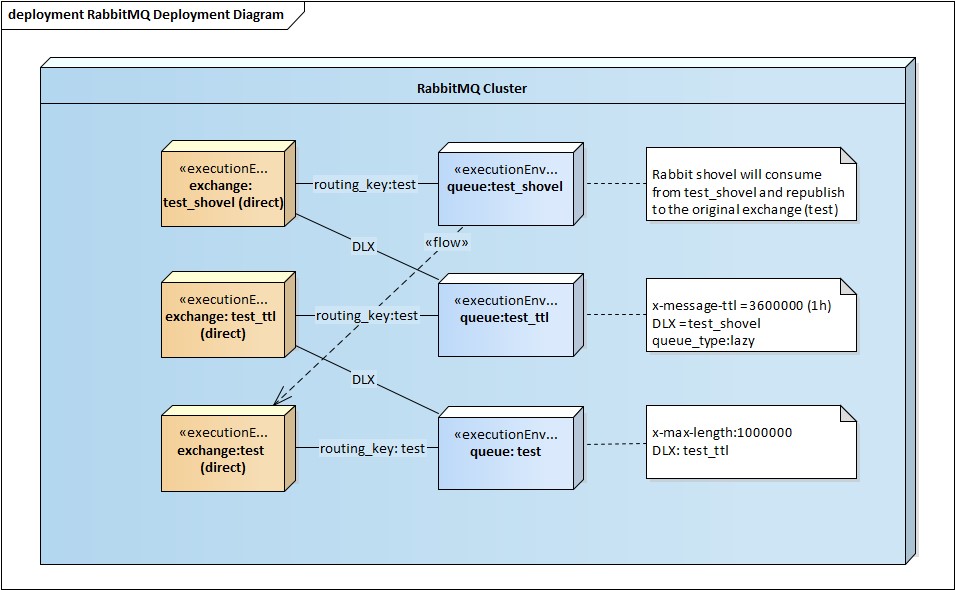
The idea is to dead-letter the messages that are overflowing to another queue with a default TTL associated. Since this queue should not consume memory, its type is set to "lazy". The messages will be staged here for a TTL amount of time and be dead-lettered to a different queue, test_shovel. (Rabbit will not allow us to send them to the original exchange as this will cause a loop). That last queue will be consumed by a Rabbit shovel which re-publishes the messages to the original queue.
If by that time, the overfilled original queue backlog is reduced by the consumers, these TTL’ed messages will be enqueued and finally consumed.
One problem with this setup is with the ordering of the messages. Original ordering will be lost (if you are using multiple consumers it'd be lost anyway), so if you have strict ordering requirements enforced by a single consumer, you may want to implement consumer side re-ordering or listening to the “staging queue” as well and give precedence to it on the receiver side.
Here are the queue definitions of the test setup:
Original Queue (test):
TTL Queue (test_ttl):
Shovel Queue (test_shovel):

These queues are bounded to “direct” exchanges “test”, “test_ttl”, and “test_shovel” respectively with the routing key “test”.
It is important to note that this setup should go hand-in-hand with observability practices. Traffic metrics will help us when to increase the maximum message count limit, and at some point, scale the Rabbit instance itself.
Happy queuing!
Opinions expressed by DZone contributors are their own.
Comments