Putting Jenkins Build Logs Into Dockerized ELK Stack
In this tutorial, you will learn how to dockerize Filebeat, Elasticsearch, Logstash, and Kibana and utilize them to manage Jenkins logs.
Join the DZone community and get the full member experience.
Join For FreeToday we are going to look at managing Jenkins build logs in a dockerized environment.
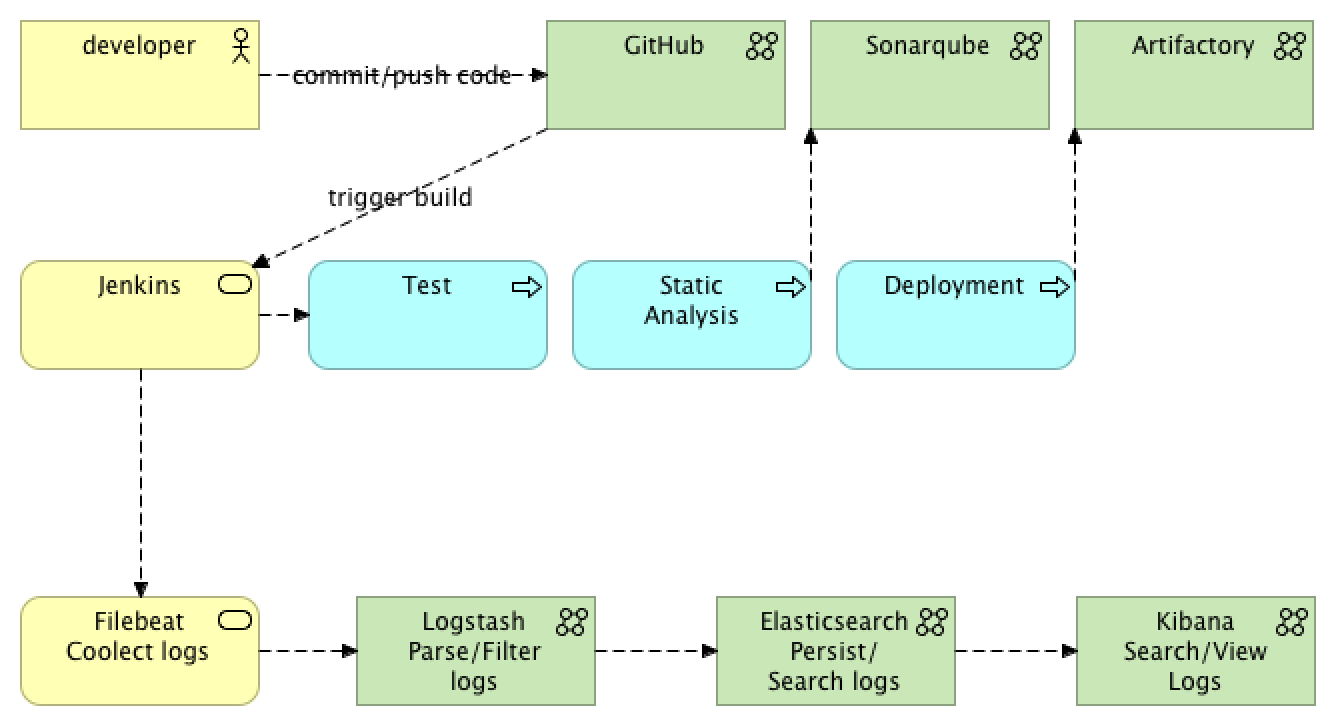 Normally, in order to view the build logs in Jenkins, all you have to do is to go to a particular job and check the logs. Depending on a log rotation configuration, the logs could be saved for N number of builds, days, etc, meaning the old jobs' logs will be lost.
Normally, in order to view the build logs in Jenkins, all you have to do is to go to a particular job and check the logs. Depending on a log rotation configuration, the logs could be saved for N number of builds, days, etc, meaning the old jobs' logs will be lost.
Our aim in this article will be persisting the logs in a centralized fashion, just like any other application logs, so they could be searched, viewed, and monitored from a single location.
We also will be running Jenkins in Docker, meaning if a container is dropped and no other means are in place, like mounting the volume for logs from a host and taking the backup, the logs will be lost.
As you may have already heard, one of the best solutions when it comes to logging is called ELK stack.

The idea with ELK stack is you collect logs with Filebeat (or any other *beat), parse, filter logs with Logstash, send them to Elasticsearch for persistence, and then view them in Kibana.
On top of that, because Logstash is a heavyweight JRuby app on JVM, you either skip it or use a way smaller application called Filebeat, which is a Logstash log forwarder; all it does is collect the logs and sends them to Logstash for further processing.
In fact, if you don’t have any filtering and parsing requirements, you can skip Logstash altogether and use Filebeat’s elastic output to send the logs directly to Elasticsearch.
In our example, we will use all of them, plus, we won’t be running Filebeat in a separate container, but instead, will use a custom Jenkins image with preinstalled Filebeat. If you're interested in how to install Filebeat or any other application into your Jenkins container, then you can read about it here.
So, a summary of what we are going to look at today:
- Configure and run Logstash in a Docker container.
- Configure and run Elasticsearch in a Docker container.
- Configure and run Kibana in a Docker container.
- Run Jenkins with preinstalled Filebeat to send the logs into ELK.
The command to clone and run the stack will be available at the end of the article.
1. Configure and Run Logstash in a Docker Container
Let’s create a docker-compose file called docker-compose-elk.yml and add containers related to ELK there:
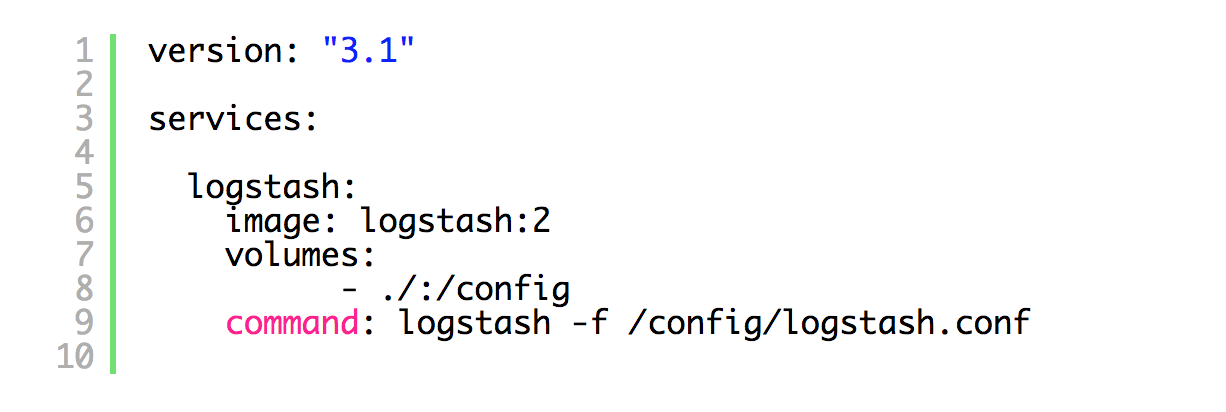
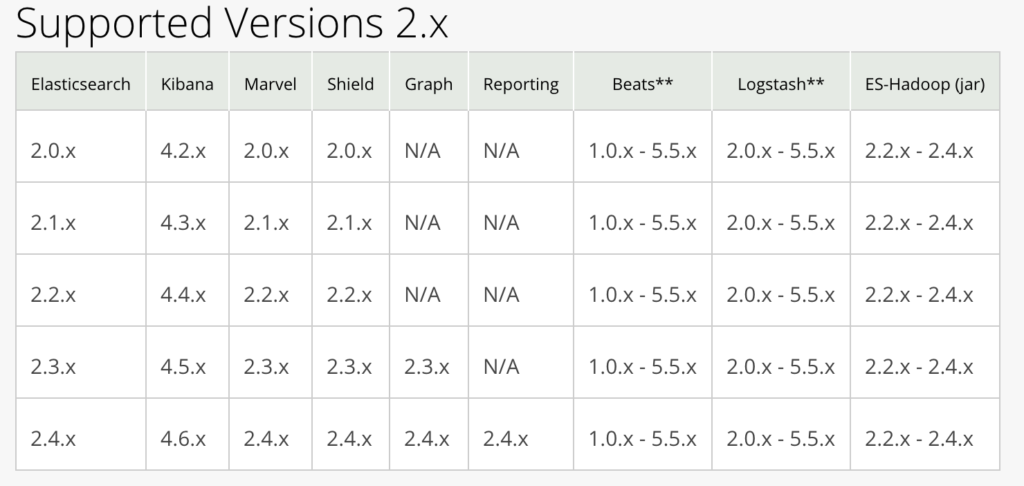
As you see, we created a new file and added Logstash to it; it is a pretty old image and I just took it from the stack I set up a long time ago (I have updated it, so the source code you download from my reference implementation could have a newer version). If you want to get latest, you will need to make sure the versions matrices match:

Now we need to configure Logstash in logstash.conf:

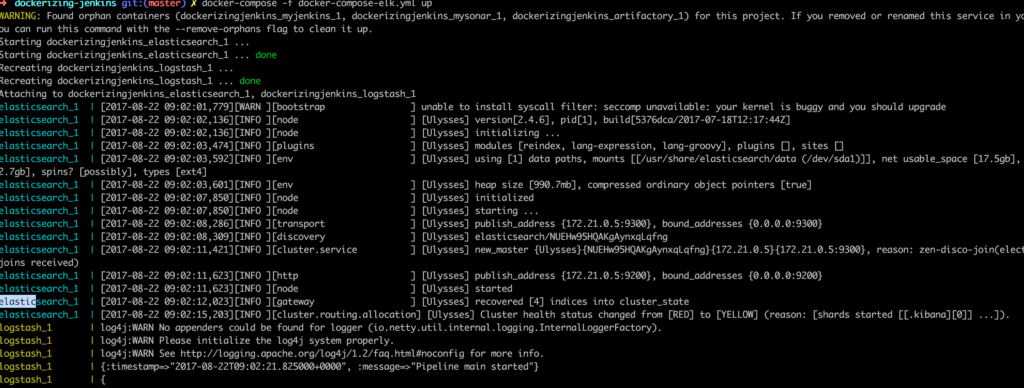
With this config, all it does is show the logs on the output so we can check if it is actually working. Another baby step; let’s run the new stack:


As you can see, Logstash is up and running.
2. Configure and Run Elasticsearch in a Docker Container
The next step is adding Elasticsearch to the stack:
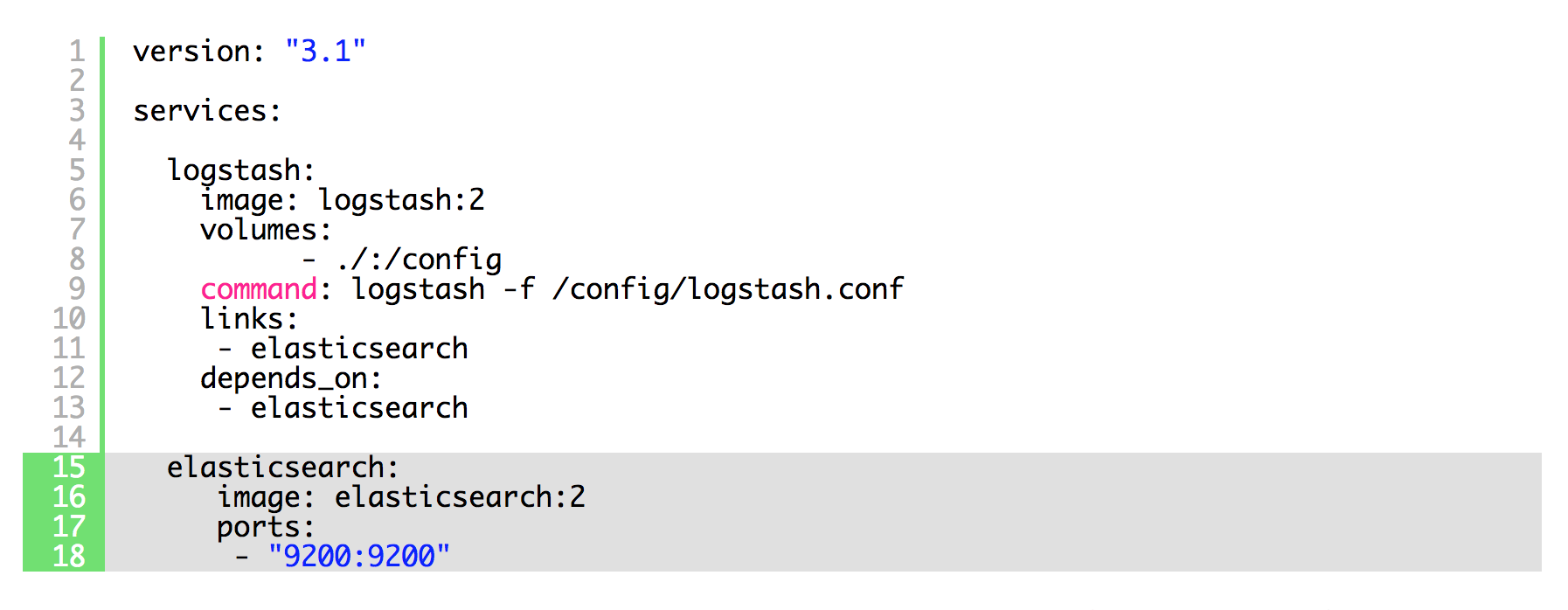
We also added links and dependency on Elastic to Logstash, so it can see it and wait for it as well. Now we need to forget to configure Logstash to send messages to Elastic on top of the standard output:

Now you can stop the ELK stack and start again, just hit Ctrl + C or run:


3. Configure and Run Kibana in a Docker Container
Let's add Kibana into the stack now:
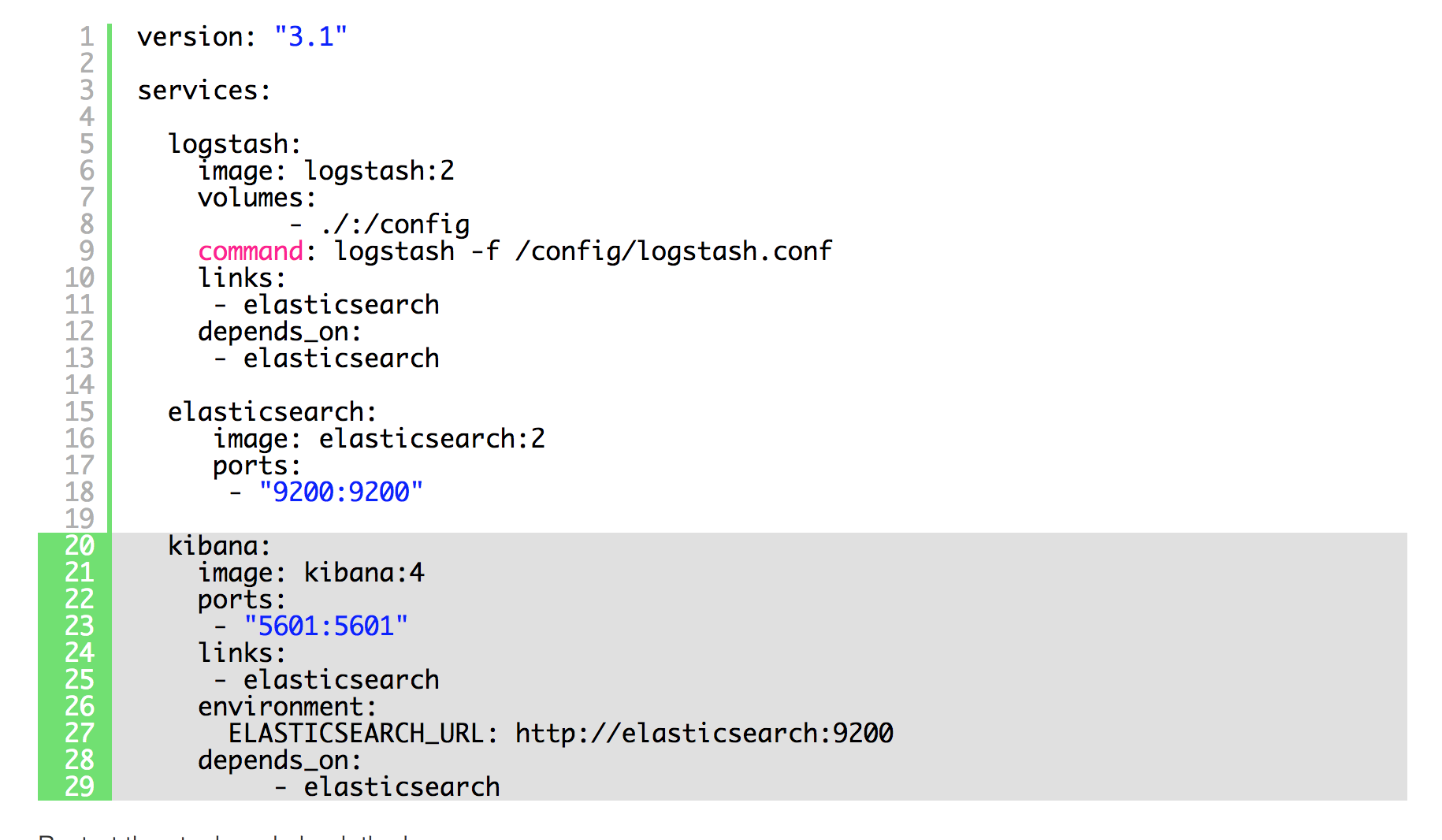
Now go to http://localhost:5601. That is where you find Kibana; you should see this screen:
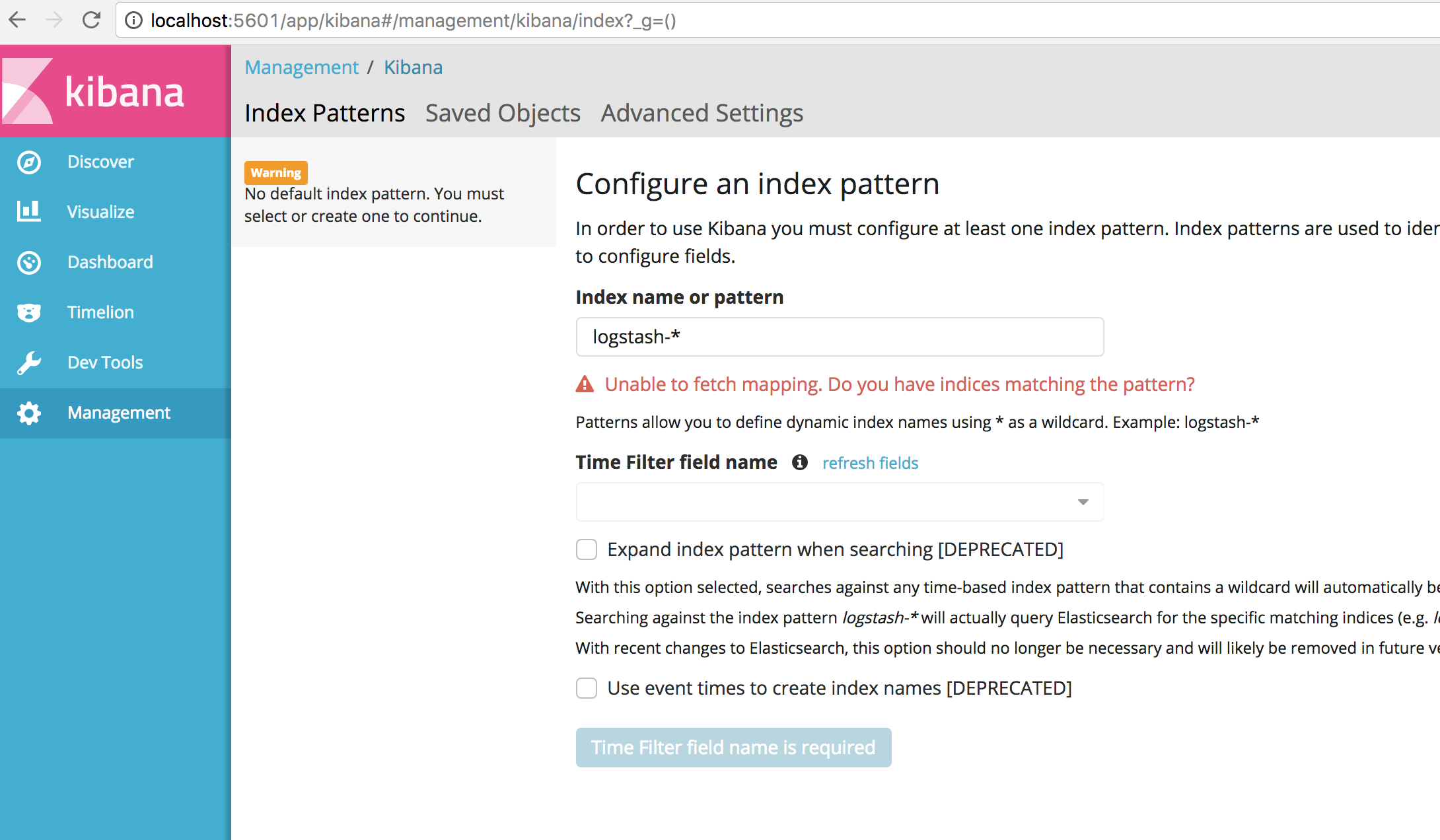
Time to send some logs into the stack.
4. Run Jenkins With Preinstalled Filebeat to Send the Logs Into ELK
Create docker-compose.yml with the content as below for Jenkins:
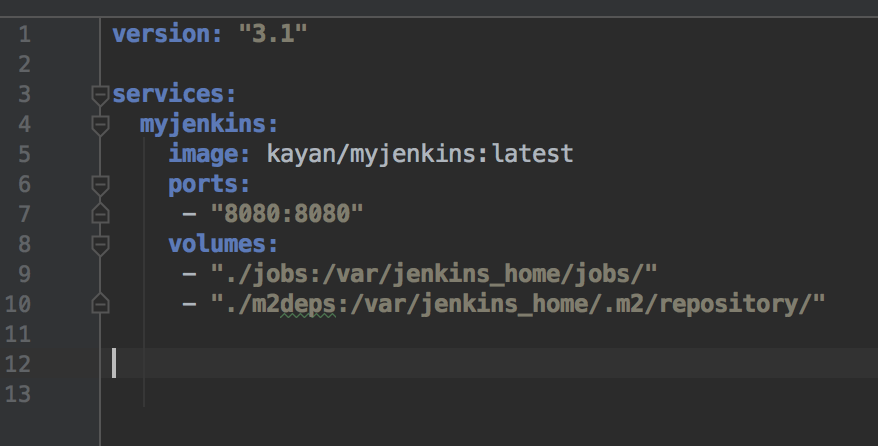
As you see, it requires the jobs folder to be mounted from the host; this is to configure the jobs which Jenkins will run.
Let's create the folder structure:
Add this config to config.xml:
<?xml version='1.0' encoding='UTF-8'?>
<flow-definition plugin="[email protected]">
<actions>
<org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction plugin="[email protected]">
<jobProperties/>
<triggers/>
<parameters/>
</org.jenkinsci.plugins.pipeline.modeldefinition.actions.DeclarativeJobPropertyTrackerAction>
</actions>
<description></description>
<keepDependencies>false</keepDependencies>
<properties/>
<definition class="org.jenkinsci.plugins.workflow.cps.CpsScmFlowDefinition" plugin="[email protected]">
<scm class="hudson.plugins.git.GitSCM" plugin="[email protected]">
<configVersion>2</configVersion>
<userRemoteConfigs>
<hudson.plugins.git.UserRemoteConfig>
<url>https://github.com/kenych/maze-explorer</url>
</hudson.plugins.git.UserRemoteConfig>
</userRemoteConfigs>
<branches>
<hudson.plugins.git.BranchSpec>
<name>*/jenkins-elk</name>
</hudson.plugins.git.BranchSpec>
</branches>
<doGenerateSubmoduleConfigurations>false</doGenerateSubmoduleConfigurations>
<submoduleCfg class="list"/>
<extensions/>
</scm>
<scriptPath>Jenkinsfile</scriptPath>
<lightweight>true</lightweight>
</definition>
<triggers/>
<disabled>false</disabled>
</flow-definition>This is needed to run Jenkins with predefined jobs. Ideally, it should be done with jobDsl, but for the sake of this article, I just used simple job config with a single job.
Let's run the stack now:

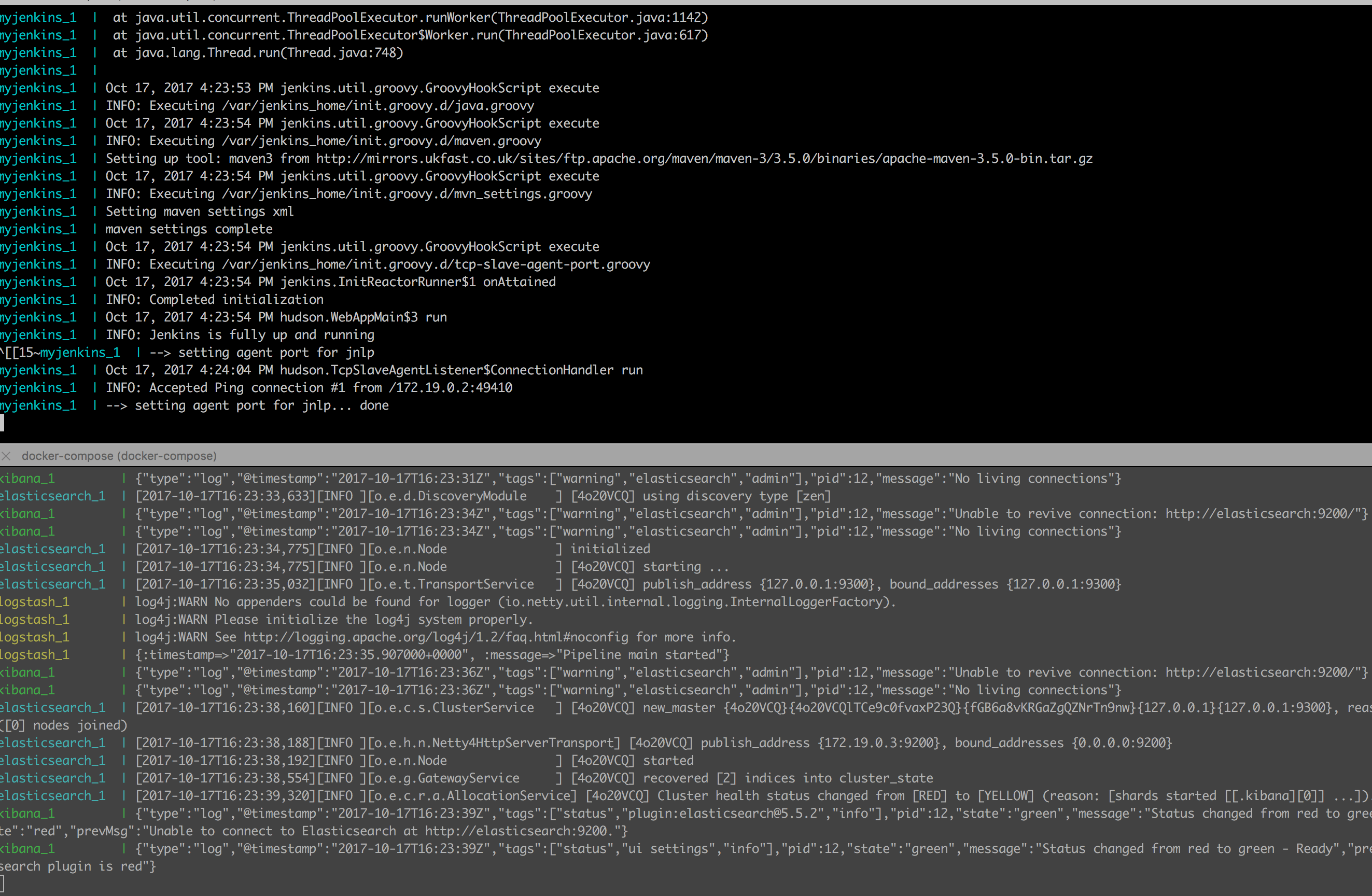
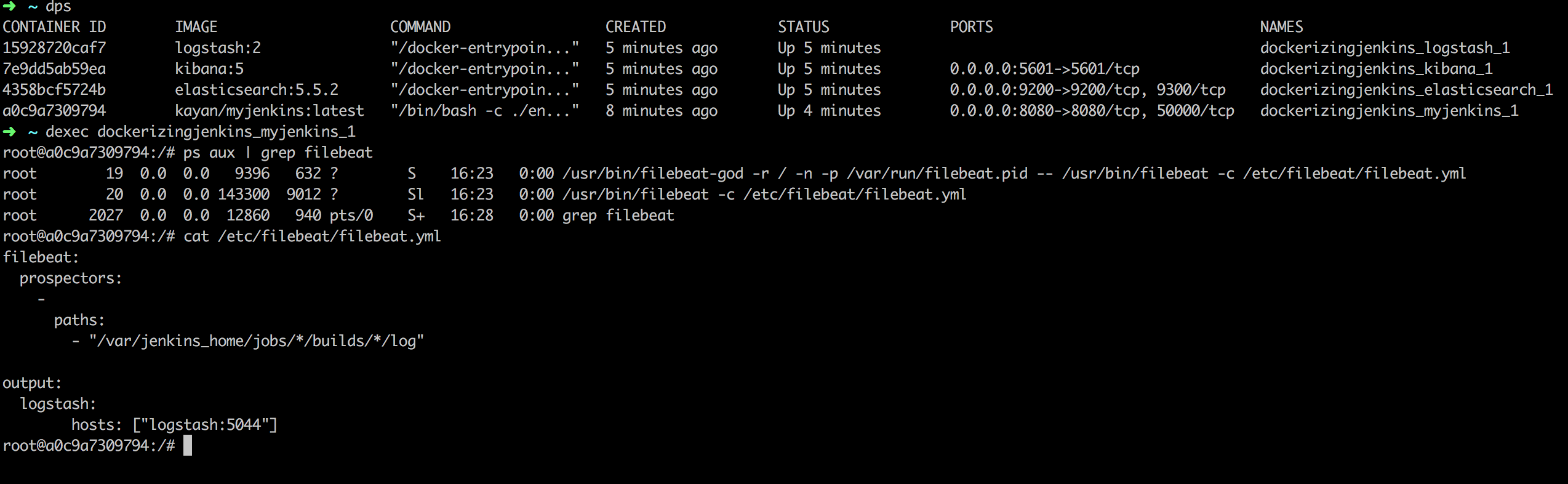
As you can see, everything is up and running. We can also check the Filebeat configuration inside the container:
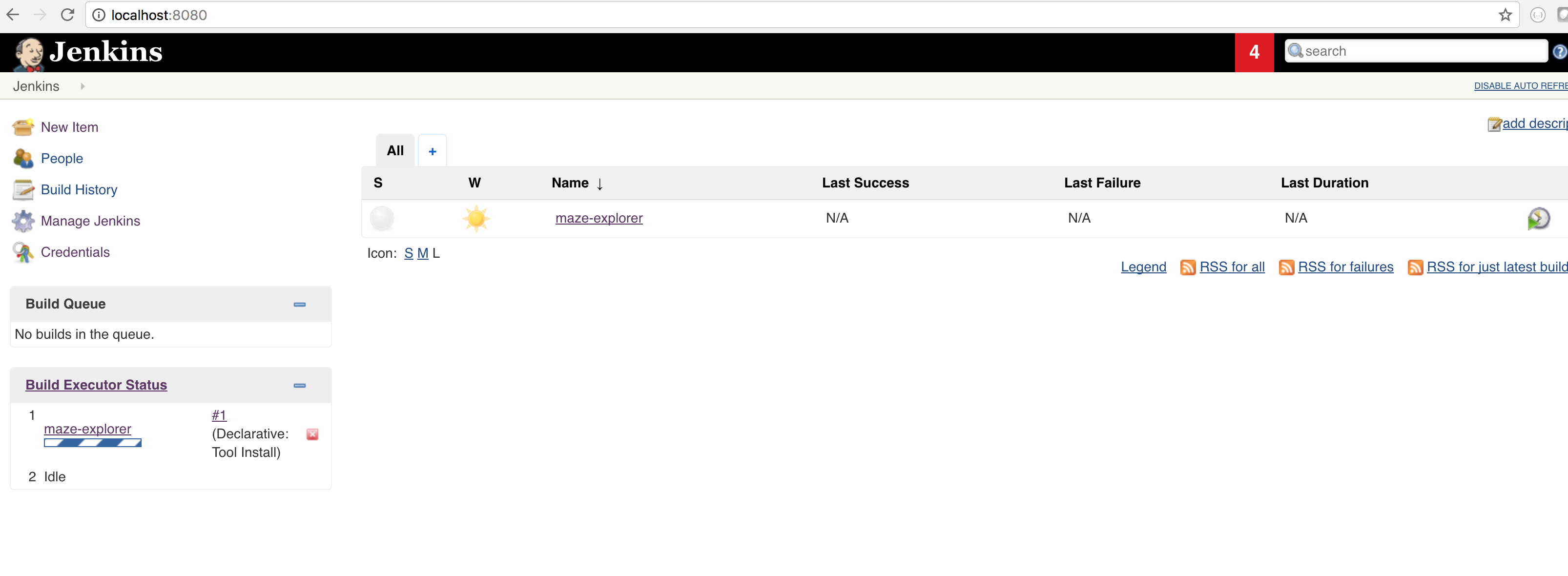
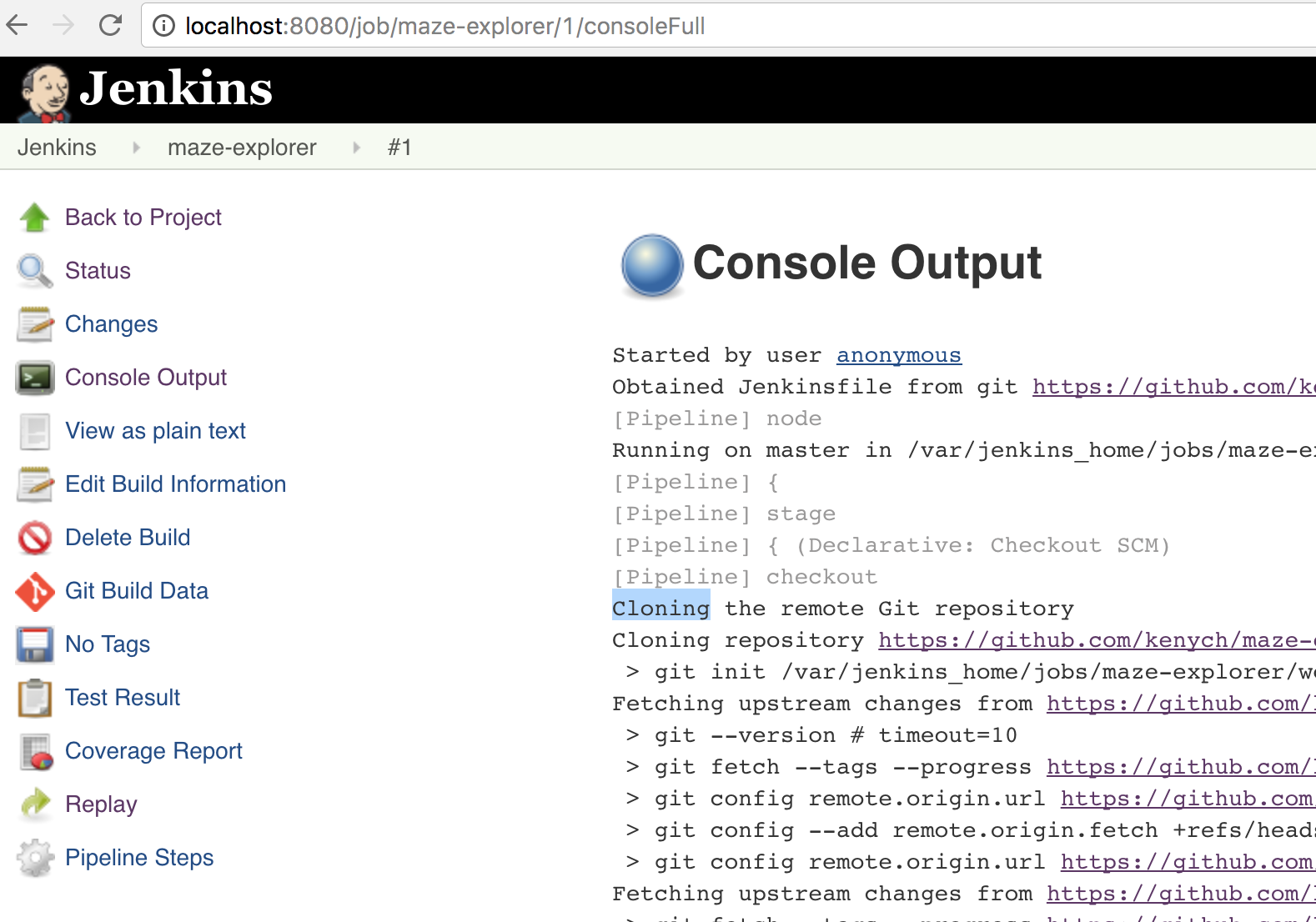
As soon as you run the job, Filebeat should start sending logs found by scanning the configured path, so please start the job:
Now let's search for something in the logs:
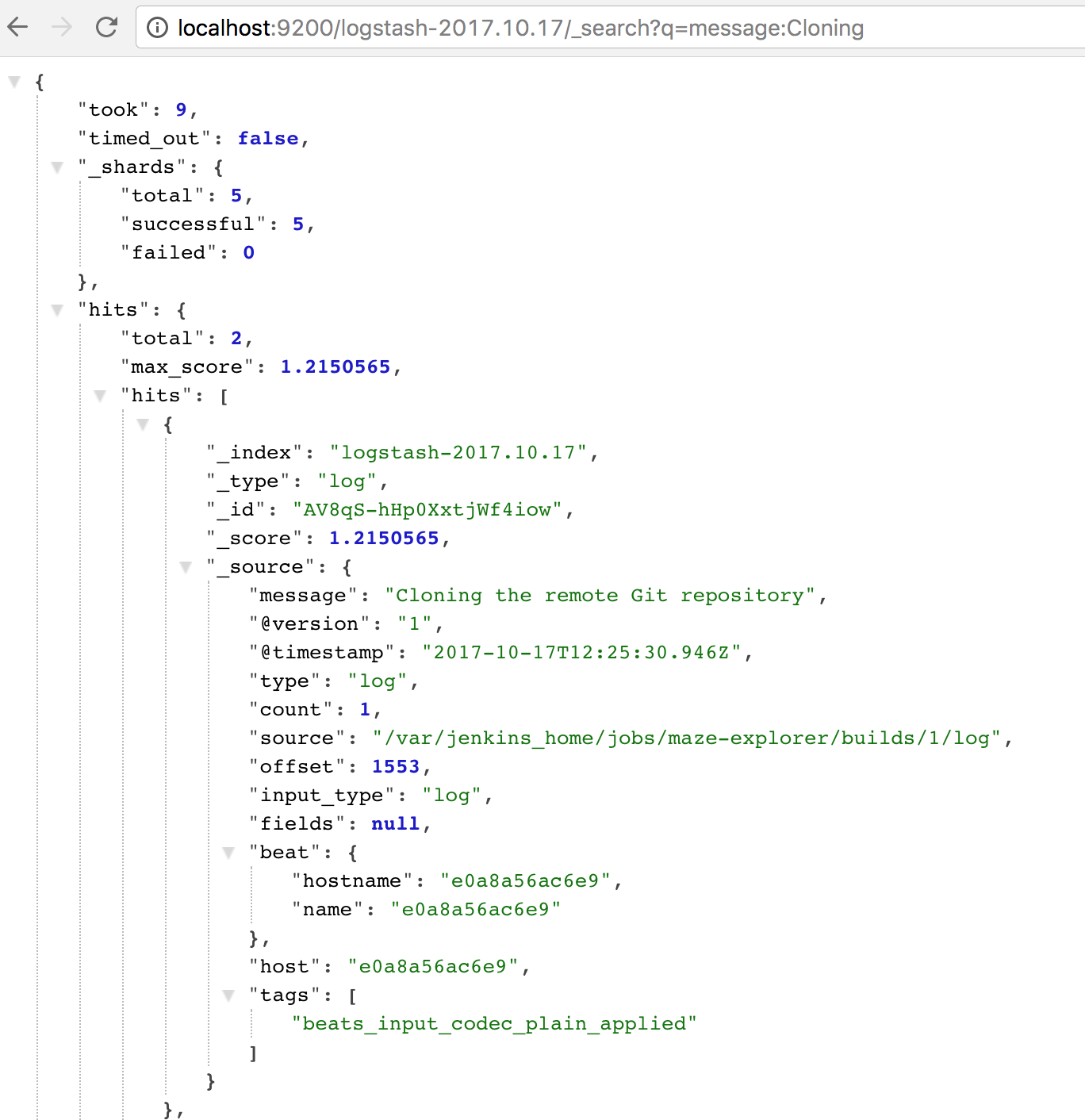
I picked up the phrase "cloning;" let's use Elastic's REST API first:
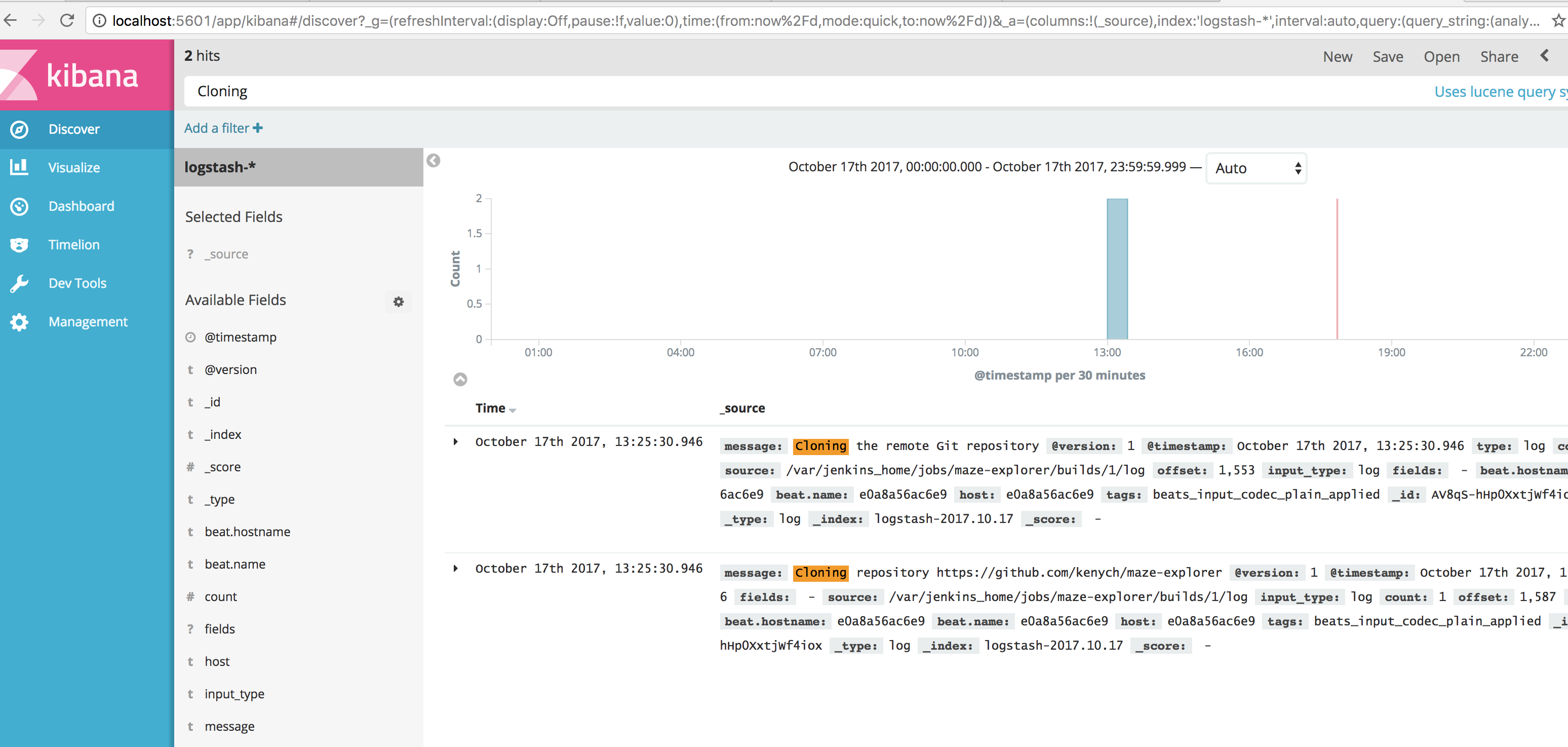
And then Kibana:
Finally, if you didn’t follow the instructions but still want to have it all up and running with a magic command, just run this to clone and run the stack:
git clone https://github.com/kenych/dockerizing-jenkins && \
cd dockerizing-jenkins && \
git checkout dockerizing_jenkins_part_4_elk_stack_simplified && \
./runall.shOpinions expressed by DZone contributors are their own.
Comments