Quality Assurance 101 for AI and Machine Learning
QA for AI and ML is developing fast. Learn why it matters and what data quality has to do with the accuracy of your ML models and the success of AI initiatives.
Join the DZone community and get the full member experience.
Join For FreeArtificial intelligence has been in the spotlight for several years. Despite widespread hype and sensationalized headlines about 'robots coming for your jobs,' it is clear that AI generates value, even if the gains are marginal, and it has multiple applications across diverse industries.
Though AI, machine learning, and other intelligent technologies are rapidly gaining traction in various industries, the 'productionalization' processes lag behind. Quality assurance for AI perfectly demonstrates this.
There exist no AI developers or AI testers, per se. All the work is done by data scientists and ML engineers who handle every stage of the ML life cycle. In comparison to software development, AI engineering relies on 'testing best practices' rather than concrete rules that everyone adheres to.
QA for AI and machine learning is developing at a fast clip, though. Secure and data-sensitive industries like healthcare, banking and finance, insurance, logistics, and communications require AI/ML solutions to be tested and fine-tuned continuously, to ensure their data, infrastructure, and critical systems are protected.
This article is my take on how QA for AI/ML should be done. My colleagues at Provectus, as I found out, have their own vision of the process. This only proves how much work is ahead for all who want to test AI.
Life Cycle and Testing of An ML Model
A few words on basics.
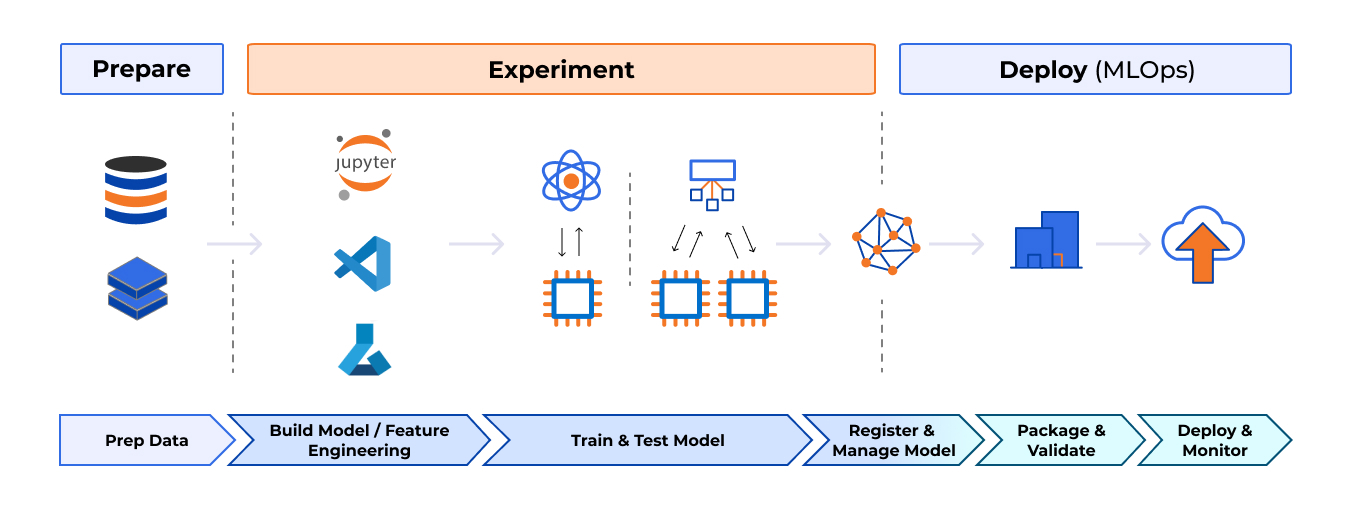
From a QA perspective, the ML model life cycle includes three major stages:
- Preparation. Data is collected, filtered, and wrangled to make it easier to process and analyze at later stages.
- Experimentation. Features are engineered. The model is designed, built, trained, tested, and fine-tuned, in preparation for deployment.
- Deployment. Once the model is packaged and validated, it is deployed in production to be used by customers. The model is monitored to ensure high accuracy and reliability.
This means that very different properties are tested at every stage of the life cycle, from data and features to model components and the AI solution itself. This creates a major challenge for QA engineers.
Data Testing
We cannot underestimate the importance of clean, well-prepped data in machine learning. As the saying goes, 'garbage in, garbage out,' If you push garbage into a high-quality ML model, it will deliver garbage results, and vise versa.
There are quite a few studies that support this.
Back in 2016, for instance, a group of researchers from UC Berkeley concluded that 'failure to [detect and repair dirty data] can result in inaccurate analytics and unreliable decisions by ML models.'
We proved the very same thing at Provectus.
One of our clients, GoCheck Kids, wanted to enhance the image classification component of its pediatric photo screening application through machine learning. Upon review of the results delivered by the vision screening model, it was found that a considerable portion of images that were used to train the model had to be relabelled. Once done, the team saw a 3x increase in the ML model’s recall while preserving its precision.
So, what can be tested?
We can test a dataset as a whole, and each data point individually.
From a data quality perspective, it is important to check for duplicates, missing values, syntax errors, format errors, and semantic errors. If you are detecting statistical quality issues, you should look for anomalies and outliers in your data.
Bear in mind, however, that what you should and should not test, and how you test it, all depends on the project. In general, data testing is still done manually.
Some tools to mention: Deequ, GreatExpectations, Tensorflow Data Validation.
Note: I described the process for Data QA in detail here — Data Quality Highlight System.
Model Testing
The major principle of ML model testing is that you treat your model as an application, with all of its features, inputs, and outputs. Conceptually, if you look at your models that way, it will be much easier to test them.
Testing of any application starts with unit tests. You should have lots of high-quality unit tests, to cover as many scenarios as possible. Though this best practice is not followed by many ML engineers, I would argue that unit testing is key to ensuring high accuracy and performance of the model.
Dataset testing is a critical stage of model testing. Your priority here is to ensure that the training set and the testing set are statistically equivalent; that is, the difference between sets is smaller than what is considered meaningful, and statistically falls within the interval indicated by the equivalence bounds. The image below shows datasets that are NOT statistically equivalent.
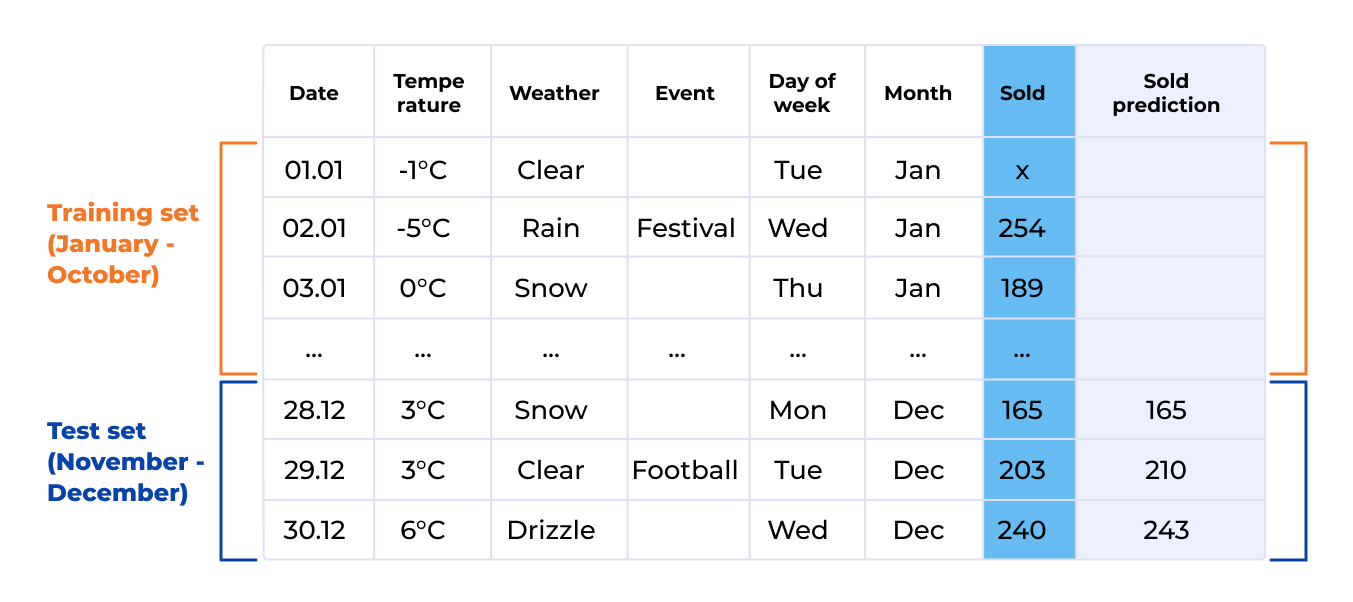
Data is also important because it should be used to write use cases. Basically, datasets represent your test cases for checking the robustness of the model. For instance, depending on your model and use case, you could use Golden UAT datasets, security datasets, production traffic replay datasets, regression datasets, datasets for bias, datasets for edge cases, and more.
You should also test features. Specifically, your goal here is to figure out which features impact how the model generates predictions the most. Feature testing is crucial if you have more than one model in the pipeline and have to complete them to select the more accurate one.
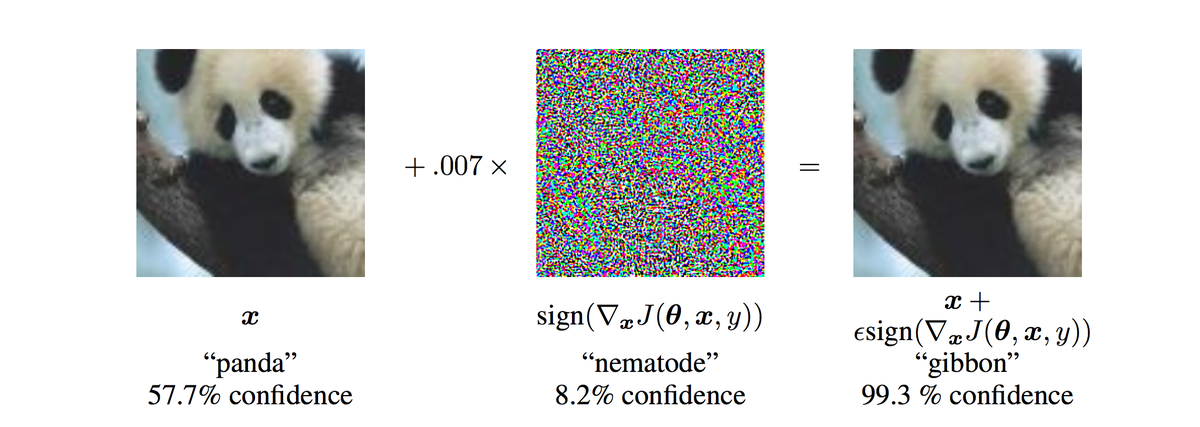
Models have to be tested for security. This is a broad topic in itself, and I will only scratch the surface a bit. Models, like any other piece of software, can be infected by viruses (so-called nematodes). Nematodes can cause models to misidentify objects and generate false predictions. For instance, a model infected by a nematode can 'see' a gibbon instead of a panda in the image of a panda.
Finally, you need to test models for bias. Bias is a disproportionate inclination or prejudice for or against an idea or thing. It exists in many shapes, but from a model testing perspective, the most impactful types of bias are:
- Selection Bias — The selection of data in such a way that the sample is not reflective of the real-world distribution.
- Framing Bias — Information is presented in such a way that it changes how people make decisions about equivalent choice problems.
- Systematic Bias — Consistent and repeatable errors in values caused by various factors that skew the data in a particular direction.
- Personal Perception Bias — The tendency to focus on (and assign more value to) information that confirms a person’s preconceptions.
It is critical to scrutinize outlier data and to closely inspect missing values to find a trade-off between bias and variance. Try to avoid overfitting and underfitting, and be as objective in filtering data as you possibly can.
Eradicating bias in data and in models is easier said than done, though.
First, as humans, we are biased by nature and no one is 100% objective. Second, bias testing is almost always done manually, which can only add more errors to data in the long run.
Fortunately, there are several services that can help you handle bias more efficiently. One is Pymetrics, an open-source bias testing tool for generalized ML applications. Another is Amazon SageMaker Clarify, a fully managed service that makes it easier for developers to look into their training data and models to identify and limit bias and explain predictions.
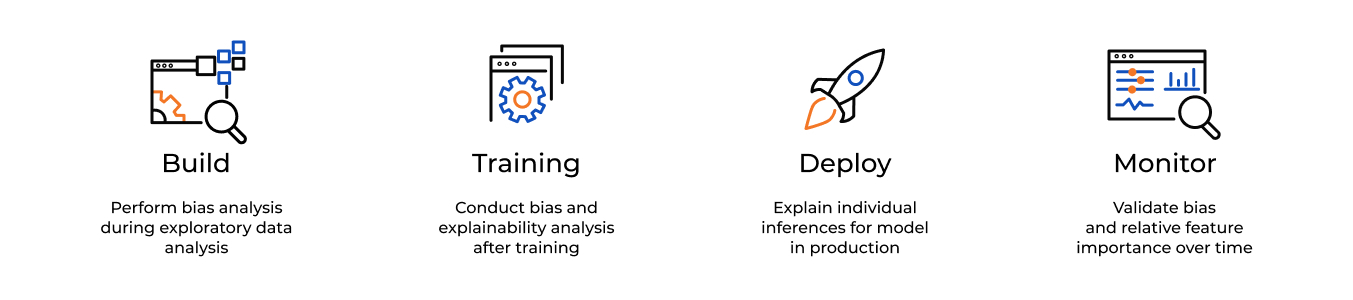
Amazon Sagemaker Clarify was announced at AWS re:Invent 2020 in December 2020. It is still too early to tell how effective and useful the service is, but if AWS lives up to its promise, SageMaker Clarify can revolutionize the way bias testing is done.
Testing a Model Within a Complex IT System
Often machine learning models are designed and built as offline solutions. That is, they are developed by ML engineers who are not very concerned about how these models will be used in real-world applications.
With the advance of reproducible machine learning, MLOps, and feature stores, this situation has been changing at a rapid pace, which is awesome for QA professionals. Because ML models can now be developed (and tested) as part of a comprehensive IT system, testers can move into the field more quickly and easily.
When a model is tested within an IT system as part of an entire application or solution, all types of testing that QA engineers are used to can be applied. For example, you can run integration tests to check if all components work as expected. Or you can go with system testing, to find out if the whole system works as intended.
In addition, it is important to write integration tests to test APIs (you can use Postman for that), run incorrect data sets through the system to check fault tolerance, and check for compatibility with different versions of the environment.
Systems tests should cover such areas as configuration testing, security testing, performance testing, and UI testing. They can be performed both manually and automatically.
Put simply, at this stage you test the entire system and the models within the system — you do not view any model as an offline component of the system.
Testing After Deployment to Production
The major difference between software testing and ML testing is that AI/ML solutions (and ML models as part of these solutions) have to be repeatedly tested after they have been deployed to production.
When you deploy the model, it continues to evolve and degrade. Many models degrade in production, as the reality, they once reflected has changed. These processes can be influenced by:
- Changing customer habits.
- Natural anomalies and disasters.
- One-time events.
In other words, as the data processed by the model changes, its accuracy and performance also change. This process is called data drift.
To ensure that you keep track of model degradation, you should have a logging and monitoring system. It will help you to pinpoint critical points when the model’s accuracy and performance are affected by data (other factors), and act proactively to tune the model.
To complement your efforts on the testing side, you should run A/B tests to compare different models, to select champion and challenger models you could deploy to production. Of course, an automated continuous testing system should be in place to do all of that smoothly and efficiently.
Conclusion
Quality Assurance for machine learning is still in its infancy. For QA engineers who are willing to explore what AI and ML offers (and they offer a lot), this is a good thing.
In this article, I have discussed the major stages of QA for machine learning and provided a short overview of what a QA has to know to move into the field. I have summarized my own experience so far, and I would greatly appreciate feedback from the community. (I am pretty sure that some of the best practices I mentioned here are debatable.)
Summing it all up, major takeaways are:
- Focus on data. You have to ensure that the data you use to train and test a model is high quality. For that, make sure you visualize it and check it for anomalies, outliers, and statistical issues.
- Look at your model as if it were an ordinary application. Test your AI solution and test your model as parts of a complex IT system. That is, run all types of tests you would generally run to test software, but bear in mind biases and fitting.
- Continue to test the model after deployment. Account for data drift and other factors that may affect the performance of the model. Add monitoring and logging to keep track of changes; test, tune and deploy new models quickly with CI/CD in place.
I hope this article will help you kick off your career in ML testing. Kindly share your feedback and ideas in the comments section.
Published at DZone with permission of Aleksei Chumagin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments