Testing AI-Infused Apps: A Dual-Layer Framework for AI Quality Assurance
Reliable AI delivery isn't either/or—it's both/and. Test conventionally for functionality. Evaluate probabilistically for quality. Deploy with dual-discipline confidence.
Join the DZone community and get the full member experience.
Join For FreeAI-infused apps are different from traditional software. Apps that embed large language models, agents, retrieval-augmented generation (RAG), or tool-calling workflows bring their own characteristics. They combine deterministic code with probabilistic intelligence. This creates new failure modes that standard testing practices cannot fully address.
Engineering leaders, QA architects, platform teams, DevOps engineers, AI product owners, and reliability teams must adopt a dual testing strategy: rigorous software testing alongside continuous probabilistic evaluation of AI behavior. Production readiness depends on integrating both disciplines into a single, automated delivery pipeline.
In this article, I start by explaining why AI-infused apps fail differently. A two-layer testing framework is then analyzed, followed by a paragraph explaining why contract tests and evaluation harnesses are important. The next paragraph explains that since prompts are release artifacts, they should be treated as such. Regression testing, especially in production, is important for such systems, and the article concludes with a unifying testing strategy for AI-infused apps.
Why AI Apps Fail Differently
Software development was never fully predictable. While code itself may execute deterministically under controlled conditions, real-world software systems behave within dynamic environments shaped by users, infrastructure, integrations, networks, data quality, operational constraints, and evolving requirements. On the other hand, emergent behavior has always caused nondeterminism in software systems.
The introduction of AI-infused apps, however, adds another dimension of unpredictability. It all starts with the stochastic nature of foundation models. Even with the same input, outputs can vary due to temperature settings, model updates, prompt sensitivity, or data distribution shifts. Modern AI workflows compound this complexity: a user query triggers prompt orchestration, retrieval from knowledge bases, agent reasoning loops, multiple tool calls to external APIs, safety guardrails, and structured output formatting. AI-infused applications are not monolithic. They compose multiple components, each requiring distinct testing approaches:
- Prompts and system instructions: The "code" that guides model behavior
- Retrieval systems: Vector databases, embedding models, search relevance
- Agent orchestration: Tool selection, reasoning chains, decision trees
- Integration APIs: Authentication, rate limits, error handling, data transformation
- Security controls: Input validation, output filtering, permission boundaries
- Observability infrastructure: Logging, tracing, evaluation metrics
A failure in any layer can cascade. A prompt regression can cause increased tool misuse. Embedding model drift can reduce retrieval quality. A poorly validated API integration can leak sensitive data. Traditional software testing catches some of these. AI evaluation catches others. For production readiness, we need to consider both.
The Two-Layer Testing Framework
Successful AI system testing requires recognizing two fundamentally different quality dimensions. The conventional dimension focuses on traditional software testing, and the probabilistic dimension of evaluating AI.
The Two Layers of QA
|
Testing Layer |
Layer 1 CONVENTIONAL Software Testing |
Layer 2 Probabilistic AI Evaluation |
|---|---|---|
|
Focus |
Traditional software components: APIs, databases, infrastructure, integrations, permissions, deployment mechanisms |
AI-specific behavior: prompt effectiveness, reasoning quality, output appropriateness, agent decision-making) |
|
Testing Types |
Unit tests: Individual functions, utilities, data transformations Integration tests: API contracts, service communication, database operations Contract tests: Tool interfaces, webhook payloads, third-party API schemas E2E tests: Authentication flows, permission boundaries, error handling Infrastructure tests: Deployment validation, scaling, failover Performance tests: Latency, throughput, resource utilization |
Prompt evaluation: Instruction following, tone consistency, safety adherence Agent behavior tests: Tool selection accuracy, reasoning coherence, task completion Retrieval quality: Relevance scoring, ranking accuracy, citation validation Output validation: Groundedness, factuality, formatting compliance Reasoning assessment: Logical coherence, step-by-step clarity, error recovery Safety evaluation: Harm prevention, bias detection, PII protection |
|
Success Criteria |
Binary pass/fail: Test either passes (assertion true) or fails (assertion false, exception thrown) |
Threshold-based scoring: Metrics scored on continuous scale (0.0-1.0), must exceed thresholds (e.g., safety_score ≥ 0.95) |
|
Tooling |
PyTest, JUnit, Jest (unit testing) Postman, Pact (contract testing) Selenium, Playwright (E2E) JMeter, Locust (load testing) Terraform validators (infrastructure) |
LangSmith, LangGraph, Phoenix Arize (evaluation platforms) LLM-as-judge frameworks Embedding similarity metrics Human evaluation interfaces Golden dataset harnesses Rubric scoring systems |
Figure 1: The two layers of QA for AI-infused apps
Systems can pass software tests while failing AI quality expectations. AI systems must be flexible, adaptable, autonomous, evolving, unbiased, ethical, transparent, interpretable, explainable, and safe. Conventional QA may declare that an AI-infused app is healthy. However, AI failures may cause users to experience it as broken, as in the case below.
- ✅ All APIs return 200 OK
- ✅ Response times under 500ms
- ✅ No exceptions in logs
- ✅ Permission boundaries enforced
- ✅ Database queries optimized
- ✅ Infrastructure scales appropriately
- ❌ Agent selects wrong tools 30% of the time
- ❌ Retrieval returns irrelevant documents
- ❌ Responses ignore safety instructions
- ❌ Hallucination rate increased 15% since last deploy
Reliability Through Contract Testing and Evaluation Harnesses
AI agents interact with the world through tools: APIs they can call, databases they can query, and services they can invoke. Each tool represents a contract that must remain stable. Especially when our tests give different results every time we run them due to AI, contract testing, and evaluation harnesses are indispensable.
Contract Testing for AI Tools
When an agent calls a tool (like an API or a database function), the communication is essentially an integration point. We can use contract tests to enforce strict input/output validation at this boundary. By using schema-validation libraries (such as Pydantic), if the LLM hallucinates a parameter, validation blocks it before it hits the production database.
Example: Our agent is tasked with calling get_user_balance(email: str). A contract test verifies that even if the LLM tries to pass an object or an array, the interface throws a validation error, preventing the agent from executing a malformed query.
Evaluation Harnesses
Just as software teams maintain test suites, AI teams need evaluation harnesses. These are systematic frameworks for measuring AI behavior quality. An evaluation harness is an automated framework that runs our application against a golden dataset. This is a curated, versioned set of inputs and "ground truth" reference outputs. Rather than manual spot-checking, these harnesses use LLM-as-a-Judge. A highly capable model acts as the evaluator for the production model. Key metrics include:
- Groundedness: Does the response rely solely on the provided context?
- Citation Validation: Does the response correctly link claims back to the retrieved sources?
- Task Completion: Does the final output solve the user's underlying intent?
By automating these checks, we shift AI development towards an engineering process rather than a "vibes-based" set of activities.
Prompts Are Release Artifacts
Prompts are not just temporary text. If they are a fundamental ingredient for how our AI system thinks, behaves, and makes decisions, then we should treat them as code. Store them in Git, review changes, run automated tests on them, and keep old versions. This way, we can track what changed, catch problems early, roll back bad changes quickly, and prevent unexpected surprises for users.
- Version Control: Prompts should exist as a versioned artifact in our source code repository.
- Auditability: When a model starts behaving erratically, we should be able to roll back to the last known "good" prompt version instantly.
- Regression Risk: Before deploying a new prompt, we should run it through the evaluation harness. Two important issues that we want to address here are instruction drift and safety degradation. Instruction drift is when the AI system starts following its core directives correctly, and then incrementally stops adhering to them. Safety degradation is where the model becomes more susceptible to prompt injection.
Regression Testing in Production
When behavior can change even when no application code has been modified, regression testing is essential. Conventionally, code changes trigger regression testing. Here, we need to run our regression tests even without code changes. Our regression suites should be executed continuously at regular intervals. AI systems depend on dynamic components such as prompts, models, embeddings, retrieval pipelines, external tools, and user interactions. All that continuously evolves over time. AI systems drift over time due to:
- Model updates from providers
- Embedding model changes
- Data distribution shifts
- User behavior evolution
- Tool API modifications
- Corpus growth or changes
Regression testing in production helps detect behavioral drift by continuously measuring output quality. Safety compliance, task completion, and response consistency can also be tracked. With regression testing, teams can monitor operational signals such as escalation frequency, fallback usage, latency anomalies, and drops in evaluation scores. The crucial point here is to find such issues before users report major failures. Since real user behavior is often more diverse and adversarial than test datasets, production validation becomes necessary to uncover edge cases that pre-release testing missed. Continuous regression testing in production is a mechanism that keeps AI systems aligned with user trust over time. Key metrics to track:
- Escalation frequency: Increase suggests AI can't handle queries
- Fallback usage: "I don't know" responses rising
- Latency spikes: Tool calls timing out, retrieval slowing
- Evaluation score drops: Golden dataset performance declining
- User feedback: Thumbs down rates, explicit complaints
- Tool error rates: API failures, permission denials increasing
- Citation accuracy: Groundedness scores dropping
- Safety violations: Harmful content detection rising
Unifying Testing Strategy
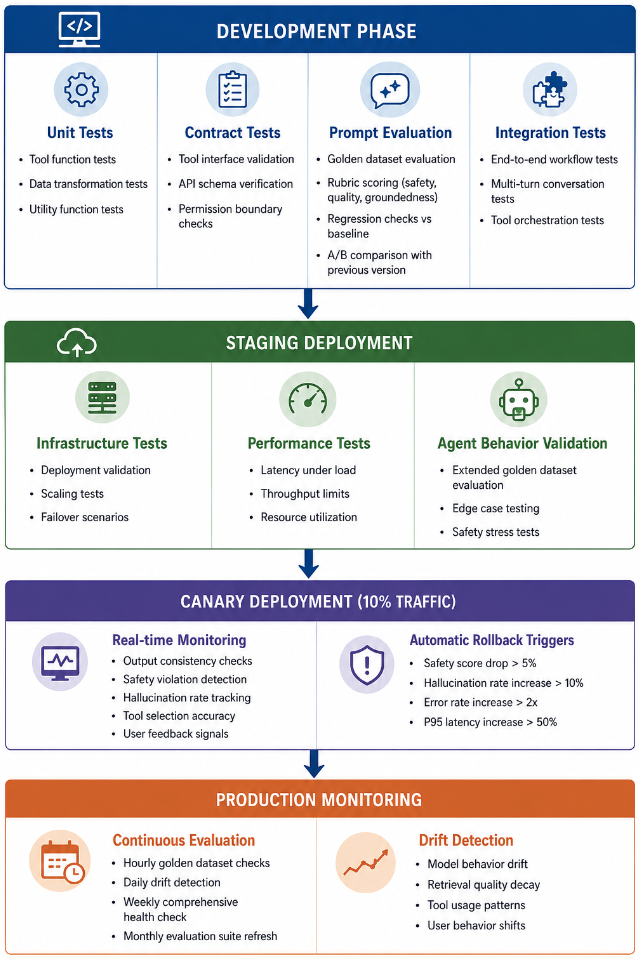
But how do we test all the above, and most importantly, when and where? As the code is written, we need to test at a unit level. We also need contract tests, prompt evaluation, and integration tests. We need to evaluate prompts and AI behavior using golden datasets and scoring systems, and verify complete workflows through integration testing. Our goal here is to be confident that both the traditional software components and the AI components behave correctly before deployment.
In a staging deployment, the system is tested in an environment that closely resembles production. Here, teams can validate infrastructure reliability, performance under load, scalability, and failover behavior. The overall behavior of AI agents under edge cases and safety stress tests can also be evaluated.
After staging, the application can move to a canary deployment, where only a small percentage of real users interact with the new version. Here, the system continuously monitors hallucination rates, safety violations, response consistency, latency, and tool-selection accuracy. If important metrics degrade beyond predefined thresholds, the system could automatically roll back to the previous stable version.
Finally, the system enters production monitoring. This is where evaluation becomes continuous. The application regularly checks for behavioral drift, retrieval quality degradation, and changing user behavior. Scheduled evaluations and monitoring signals can detect emerging reliability issues.
Wrapping Up
AI-infused applications represent a trend in software engineering. Conventional testing is necessary but insufficient. Production readiness requires two parallel disciplines: The first is software QA for APIs, infrastructure, and integrations. The second is AI evaluation for prompts, agents, retrieval, and model behavior.
Organizations that treat these as separate concerns — delegating one to engineering and the other to data science—may struggle with quality issues. Those that integrate both into unified delivery pipelines can build AI systems that are reliable, maintainable, and trustworthy.
The path forward is clear:
- Test tools like APIs: Contract tests, schema validation, permission boundaries
- Evaluate prompts like code: Version control, regression checks, systematic evaluation
- Monitor agents like services: Drift detection, quality metrics, automatic rollback
- Integrate testing disciplines: One pipeline, automated gates, continuous validation
AI systems will fail in new ways. The question is whether we catch those failures or our customers catch them. A two-layer testing framework with a unifying testing strategy can catch them early, fix them systematically, and deliver AI applications that users can trust.
Opinions expressed by DZone contributors are their own.
Comments